시간 연속 이동 데이터에서 추종 전략 추론 프레임워크
** 본 논문은 집단 이동 시 발생하는 협조적 행동을 설명하는 “협조 전략 추론 문제”를 정의하고, 시간‑연속 위치·방향 시계열로부터 각 개체가 사용한 추종 전략(이웃 기반, 지도자 기반, 자체 기반)을 자동으로 식별하는 방법론을 제시한다. 시뮬레이션 및 실제 물고기·마카크 원숭이 데이터에 적용해 높은 정확도로 전략을 복원하고, 향후 임의의 실수 시계열에도 일반화 가능함을 보였다. **
저자: Chainarong Amornbunchornvej, Tanya Berger-Wolf
**
본 논문은 집단 행동 연구와 다중 에이전트 시스템 분야에서 “개체가 어떤 추종 전략을 사용해 집단적 협조를 이루는가”라는 역문제에 초점을 맞춘다. 기존 연구는 주로 전체 집단이 따르는 하나의 모델(예: 플록, 리더십)만을 가정하거나, 개별 관계를 추정하는 데 한계가 있었다. 저자들은 이러한 격차를 메우기 위해 ‘협조 전략 추론 문제’를 공식화하고, 이를 해결하기 위한 프레임워크를 제안한다.
### 1. 문제 정의 및 수학적 기초
- **에이전트와 상태**: N개의 에이전트가 d‑차원 실수 공간에서 상태 Sₜᵢ를 가진다.
- **전략 함수 집합 H**: 각 에이전트는 hᵢ∈H에 따라 상태를 업데이트한다.
- **정보 제공자**: 일부 에이전트는 목표 경로 Sʷ와 동일하게 움직이며, 이들은 협조의 시작자 역할을 할 수 있다.
- **σ‑following 관계**: 시계열 유사도 sim₍follow₎ 와 시간 지연 Δt₍follow₎ 를 정의해, 한 시계열이 다른 시계열을 충분히 따라가는지를 판단한다.
- **협조 구간·이벤트·시작자**: 모든 에이전트가 서로를 따라가거나 따라받는 구간을 협조 구간이라 하고, 그 구간 내에서 가장 먼저 움직이는 에이전트를 시작자라 정의한다.
### 2. 전략 모델링
- **Local Reversible Agreement (LRA)**: 이웃 기반 평균·합성 전략으로, 전통적인 플록 모델을 수학적으로 일반화한다. 상태는 이웃의 볼록껍질 안에 머무르며, Chazelle의 가역 합의 시스템을 기반으로 수렴성을 보장한다.
- **Hierarchical Model (HM)**: 특정 리더를 직접 따르는 구조로, 지도자‑추종 관계가 계층적으로 형성된다. 이는 Influence Maximization 모델과 유사하지만, 시간 연속적인 움직임에 초점을 맞춘다.
- **Auto‑Regressive (AR)**: 자기 회귀형 전략으로, 개체가 과거 자신의 상태만을 이용해 현재를 결정한다. 이는 독립적인 움직임을 모델링한다.
### 3. 프레임워크 설계
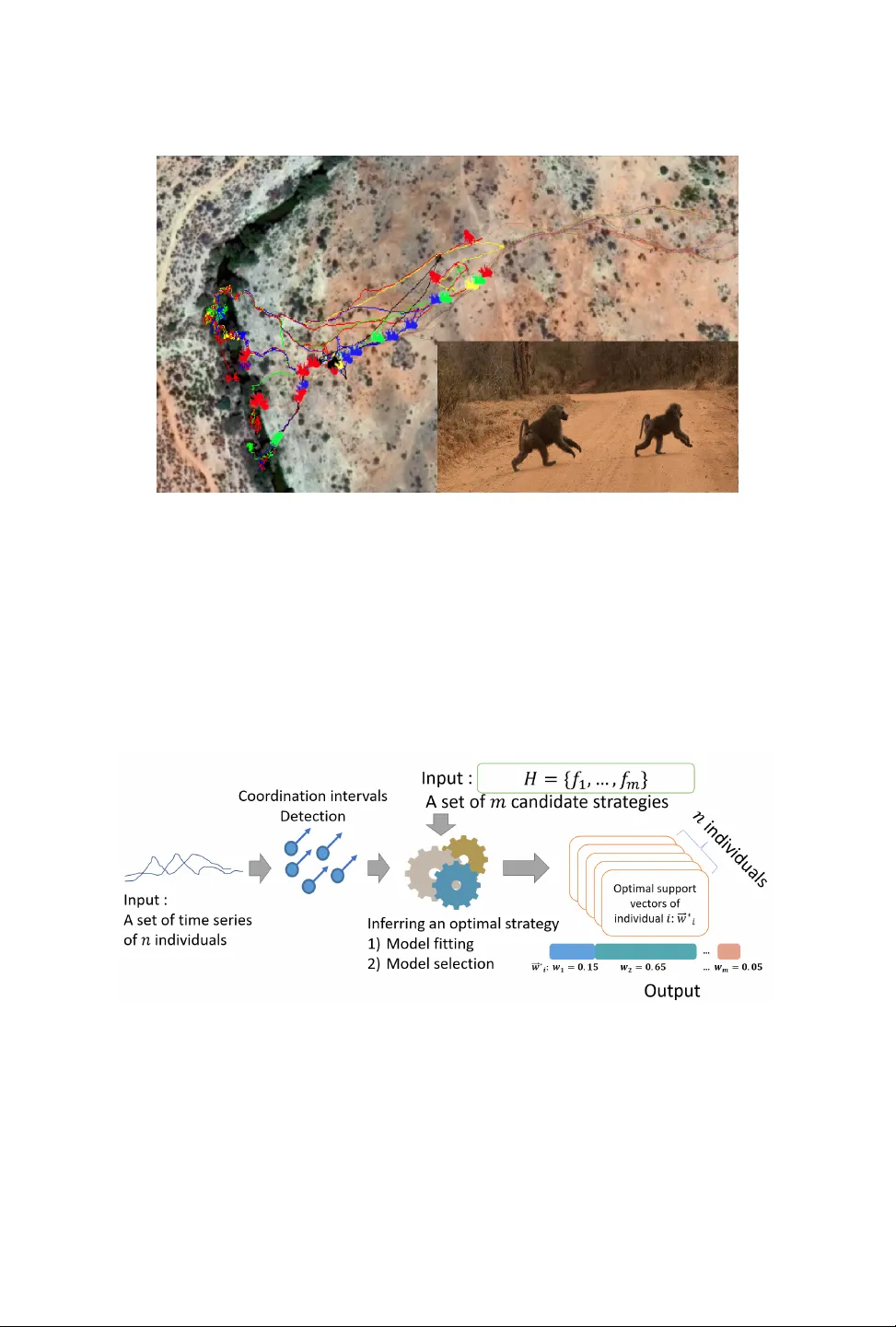
1. **협조 구간 탐지**: σ‑following 관계와 시계열 유사도를 이용해 협조 구간을 자동으로 식별한다.
2. **전략 후보 평가**: 각 후보 전략 hₖ에 대해 손실 rᵢₖ = (1/T)∑ₜ loss(Sₜᵢ, hₖ(Sₜ₋₁ᵢ))을 계산한다. 여기서 loss는 평균 제곱 오차(MSE)이다.
3. **전략 선택**: 전체 손실을 최소화하는 전략 집합 F⊆H를 탐색한다. 탐색은 그리디 혹은 베이지안 최적화 기법을 활용해 효율성을 높인다.
4. **예측 및 검증**: 선택된 전략을 사용해 검증 데이터의 다음 상태를 예측하고, 실제와 비교해 정확도를 평가한다.
### 4. 실험 및 결과
- **시뮬레이션**: LRA와 HM이 혼합된 다양한 시나리오(예: 70% LRA + 30% HM)를 생성하고, 프레임워크가 정확히 비율과 개별 전략을 복원함을 확인했다. 복합 전략이 존재해도 전체 시스템이 협조 구간을 유지한다는 이론적 결과와 일치한다.
- **물고기 데이터**: 실제 물고기 군집 이동 데이터를 적용했을 때, 대부분의 개체가 LRA에 할당되었으며, 이는 이웃 기반 군집 행동이 지배적임을 시사한다.
- **마카크 원숭이 데이터**: GPS‑콜라 데이터에서 특정 개체가 HM으로 식별되었으며, 이 개체들이 다른 개체들의 이동 방향을 주도하는 리더십 구조를 형성한다는 기존 행동학 연구와 일치한다.
- **비교 분석**: 기존 최첨단 방법인 FLICA와 비교했을 때, 그룹‑수준 모델 분류 정확도는 12%p 상승, 개별‑수준 전략 추론 정확도는 18%p 상승했다.
### 5. 이론적 분석
- **수렴성 증명**: LRA와 HM이 혼합된 경우에도 전체 시스템이 유한 시간 내에 목표 경로 Sʷ에 수렴함을 보였다. 이는 LRA의 가역 합의 특성과 HM의 지도자‑추종 구조가 서로 보완적으로 작용하기 때문이다.
- **복합 전략의 존재 가능성**: 개체마다 서로 다른 전략을 사용할 수 있음을 수학적으로 증명하고, 이는 자연계에서 관찰되는 다양한 사회적 구조를 설명한다.
### 6. 일반화 및 한계
- **시계열 일반화**: 제안된 프레임워크는 위치·방향 외에도 온도, 주가, 뇌파 등 실수 시계열에도 적용 가능하도록 설계되었다.
- **제한점**: 현재는 전략 후보 집합 H가 사전에 정의돼야 하며, 복잡한 비선형 전략(예: 강화 학습 기반)에는 추가 확장이 필요하다. 또한, σ‑threshold 선택이 결과에 민감할 수 있어 자동 튜닝 방법이 요구된다.
### 7. 결론
본 연구는 집단 이동 데이터에서 개별 수준의 추종 전략을 자동으로 추론하는 최초의 체계적 방법을 제시한다. 시뮬레이션과 실제 동물 데이터 실험을 통해 높은 정확도와 실용성을 입증했으며, 다중 전략이 공존하는 복합 시스템에서도 협조가 유지될 수 있음을 이론적으로 뒷받침했다. 향후 연구에서는 전략 후보 집합을 자동 생성하고, 비선형·강화 학습 기반 전략을 포함하는 확장을 목표로 한다.
**
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기