시스템 테스트 데이터 생성을 위한 실용적 제약 해결
초록
본 논문은 UML·OCL 기반 시스템 테스트 데이터 모델에 대해 메타휴리스틱 탐색과 SMT를 결합한 하이브리드 제약 해결 기법을 제안한다. 변환된 NNF 형태의 제약을 검색과 SMT에 적절히 분배함으로써 복잡한 제약도 실용적인 시간 안에 대규모 데이터 샘플을 생성한다. 세 개의 산업 사례 연구에서 기존 솔버 대비 적용 가능성과 확장성이 크게 향상된 것을 실증하였다.
상세 분석
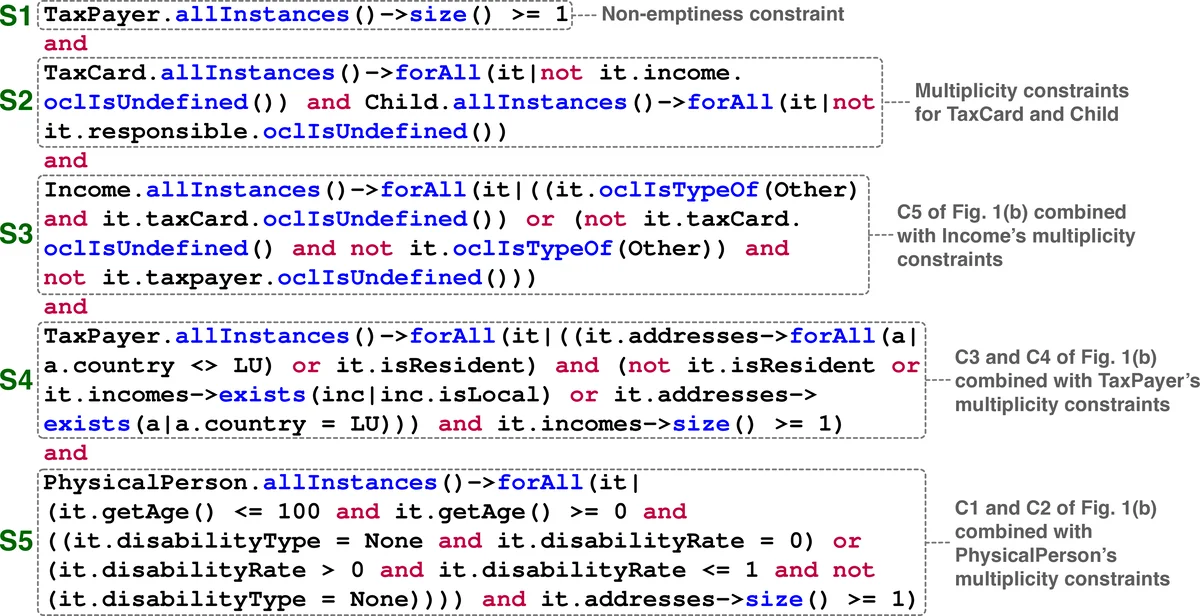
이 논문은 시스템 수준 테스트에서 요구되는 복잡하고 대규모의 제약을 효율적으로 해결하기 위해 두 가지 전통적인 기법—메타휴리스틱 탐색(search‑based)과 Satisfiability Modulo Theories(SMT)—의 장점을 결합한 새로운 프레임워크를 설계한다. 핵심 아이디어는 OCL 제약을 부정 정규형(Negation Normal Form, NNF)으로 변환한 뒤, 각 서브포뮬러를 “검색 친화적”과 “SMT 친화적”으로 구분해 각각에 최적화된 엔진에 위임하는 것이다. 검색 친화적 서브포뮬러는 변수 도메인이 큰 경우나 비선형, 문자열·컬렉션 연산이 많이 포함된 경우에 메타휴리스틱(예: 유전 알고리즘, 입자 군집)으로 탐색한다. 반면, 선형 산술, 부울 연산, 정수 구간 등 SMT가 강점으로 갖는 이론 배경에 해당하는 서브포뮬러는 Z3와 같은 최신 SMT 솔버에 전달한다. 이러한 분할은 NNF 구조를 이용해 논리 연산자를 위쪽에 배치하고, 각 리터럴을 독립적인 제약 클러스터로 분리함으로써 가능해진다.
기술적 구현 측면에서 저자들은 PLEDGE라는 도구를 개발했으며, UML 클래스 다이어그램과 OCL 제약을 입력받아 자동으로 NNF 변환, 서브포뮬러 분할, 검색/SMT 호출, 그리고 결과 통합 과정을 수행한다. 검색 단계에서는 초기 해를 무작위 생성하고, 적합도 함수는 OCL 제약 위반 수와 가중치를 기반으로 설계한다. SMT 단계에서는 변환된 서브포뮬러를 SMT‑LIB 형식으로 출력하고, 솔버가 반환한 모델을 검색 단계에 피드백한다. 이 피드백 루프는 검색이 지역 최적에 빠지는 것을 방지하고, SMT가 제공하는 정확한 해를 활용해 전체 제약 만족도를 빠르게 끌어올린다.
평가에서는 룩셈부르크 정부의 개인소득세 시스템, 의료 보험 청구 시스템, 그리고 자동차 제조사의 부품 관리 시스템이라는 세 개의 실제 산업 사례를 대상으로 실험을 진행했다. 각 사례마다 10 ~ 100 만 개 규모의 객체 인스턴스를 생성해야 했으며, 기존의 전통적 SAT/Alloy 기반 솔버와 UML‑to‑CSP는 메모리 초과 혹은 시간 초과를 빈번히 보였다. 반면 PLEDGE는 평균 2~5배 빠른 실행 시간에 95 % 이상 성공률을 기록했고, 특히 복합적인 양화(∀,∃)와 컬렉션 연산이 많이 포함된 제약에서도 안정적인 성능을 보였다. 또한, 검색‑SMT 연계 전략이 없을 경우(단일 검색 또는 단일 SMT)보다 전체 실행 시간이 30 %~70 % 정도 증가함을 실험적으로 확인하였다.
논문의 한계로는 현재 OCL의 전형적인 백그라운드 이론(선형 산술, 부울) 외에 비선형 실수 연산이나 고차 함수 호출을 완전히 지원하지 못한다는 점을 인정한다. 또한, 메타휴리스틱 파라미터(돌연변이율, 교배 비율 등)의 튜닝이 도메인마다 필요할 수 있다. 그럼에도 불구하고, 제안된 하이브리드 접근법은 복잡한 시스템 테스트 데이터 모델을 실무에 적용할 수 있는 수준으로 끌어올렸으며, 향후 다른 모델링 언어(Ecore, SysML)와의 확장 가능성도 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기