전천후 언폴딩: OmniFold로 관측량 전부를 한 번에 복원
OmniFold은 머신러닝 기반 가중치 재조정을 통해 시뮬레이션 데이터를 반복적으로 맞추어, 히스토그램 없이 고차원 관측값을 동시에 언폴딩하는 새로운 방법이다. 기존의 구간화된 언폴딩이 갖는 차원·정보 손실 문제를 해결하고, jet substructure와 같은 복잡한 LHC 데이터에 적용해 기존 Iterative Bayesian Unfolding(IBU)보다 우수한 성능을 보였다.
저자: Anders Andreassen, Patrick T. Komiske, Eric M. Metodiev
본 논문은 입자 물리 실험에서 필수적인 “언폴딩(unfolding)” 절차를 근본적으로 재정의하는 OmniFold 방법을 제안한다. 전통적인 언폴딩은 측정값을 사전 정의된 히스토그램 빈에 매핑하고, 응답 행렬 R_ij를 이용해 역문제를 해결한다. 그러나 이 방식은 (i) 빈 선택에 대한 주관적 판단, (ii) 다차원 관측량을 동시에 다루기 어려움, (iii) 보조 변수와 detector response 사이의 복잡한 상관관계를 반영하지 못한다는 세 가지 주요 한계를 가진다. OmniFold은 이러한 문제를 머신러닝 기반 가중치 재조정으로 해결한다.
핵심 아이디어는 시뮬레이션(event t, m) 쌍을 이용해 두 단계의 확률비를 추정하고, 이를 통해 가중치를 반복적으로 업데이트하는 것이다. Step 1에서는 detector‑level 시뮬레이션을 실제 데이터와 매칭시키기 위해, “Data vs. Simulation” 이진 분류기를 학습한다. 이 분류기의 출력은 p_Data(m)/p_Sim(m)에 해당하는 확률비 L이며, 이를 기존 시뮬레이션 가중치 ν_push에 곱해 새로운 detector‑level 가중치 ω를 얻는다. Step 2에서는 ω를 particle‑level(Generation)으로 “pull back”한 뒤, “Weighted Generation vs. Generation” 분류기를 학습해 p_WeightedGen(t)/p_Gen(t) 를 추정한다. 이 확률비를 기존 particle‑level 가중치 ν에 곱해 새로운 ν를 얻는다. 이 두 단계는 각각 Eq.(3)과 Eq.(4)에서 정의된 likelihood ratio를 신경망으로 근사하는 과정이며, 전체 절차는 Eq.(5)에서 제시된 형태로 최대우도 해에 수렴한다.
모델 구현에는 Particle Flow Network(PFN)를 채택했다. PFN은 입자 집합을 직접 입력받아, Φ와 F라는 두 개의 완전연결 네트워크를 통해 집합 함수를 학습한다. 이는 jet을 구성하는 각 입자의 (p_T, y, φ, PID) 정보를 그대로 활용해, 전통적인 히스토그램 기반 변수와 달리 전체 방사 패턴을 고차원적으로 표현한다. 논문에서는 latent 차원 256, Adam 옵티마이저, 20% 검증 데이터 비율 등을 사용했으며, 각 반복마다 이전 모델을 warm‑start한다.
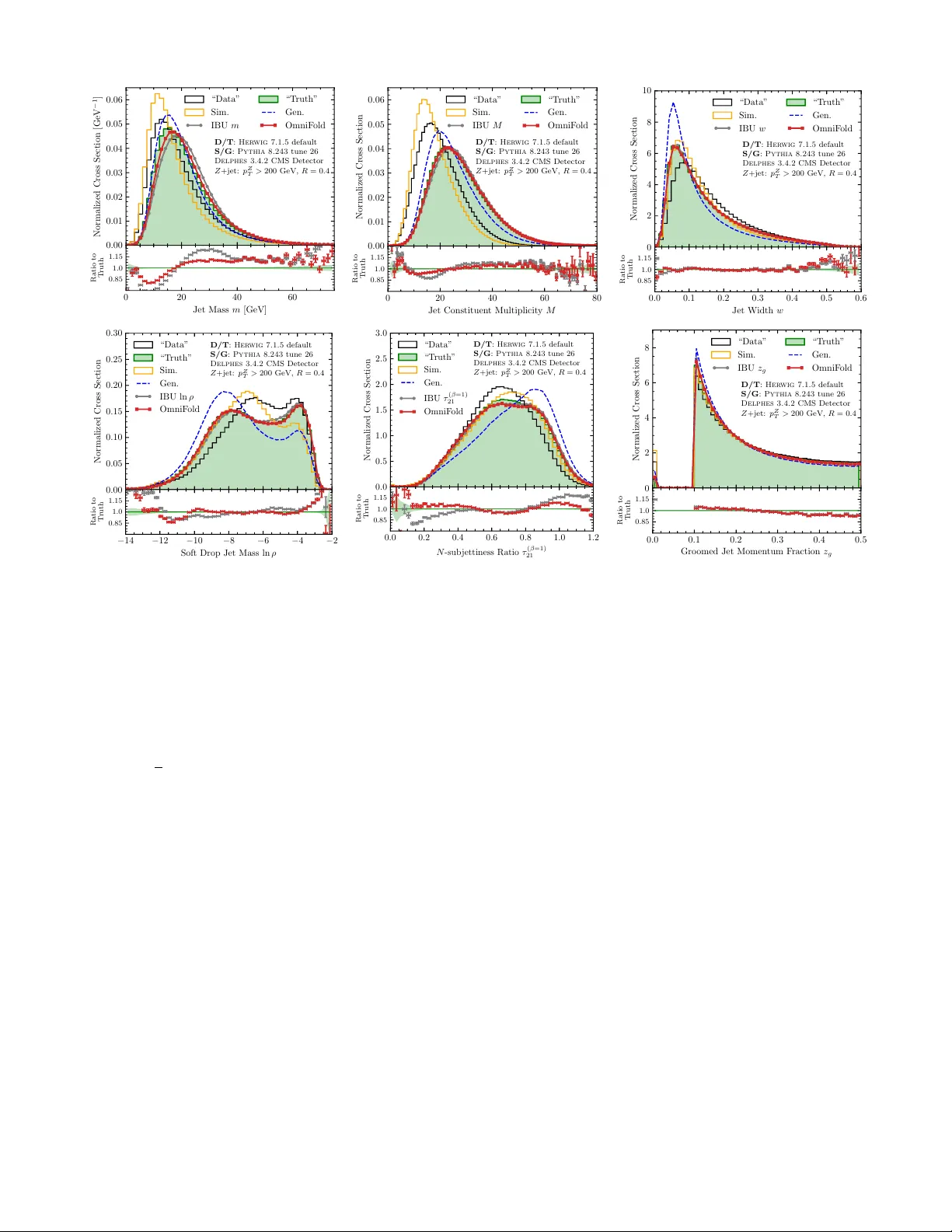
실험 설정은 LHC의 14 TeV pp 충돌에서 Z+jet 이벤트를 대상으로 한다. Herwig 7.1.5를 “데이터/진실”으로, Pythia 8.243을 “시뮬레이션”으로 사용했으며, Delphes 3.4.2를 통해 CMS detector 효과를 모사했다. jet은 anti‑k_T(R=0.4) 알고리즘으로 클러스터링했으며, Z boson의 transverse momentum p_T^Z>200 GeV 조건을 적용해 약 1.6 M 사건을 확보했다.
OmniFold은 3~4번의 반복 후, jet mass, constituent multiplicity, jet width, soft‑drop mass (ln ρ), N‑subjettiness τ_21, groomed momentum fraction z_g 등 6가지 서브스트럭처 변수에 대해 IBU와 비교했다. 결과는 다음과 같다. (1) 모든 변수에서 OmniFold이 IBU와 동등하거나 더 정확한 복원을 보여, 특히 다변량 상관관계를 동시에 고려할 수 있는 점이 큰 장점이다. (2) 통계적 불확실성(오차 막대)은 OmniFold이 더 작게 나타났으며, 이는 신경망이 전체 데이터 분포를 효율적으로 활용했기 때문이다. (3) IBU는 각 변수마다 별도의 응답 행렬을 필요로 하지만, OmniFold은 하나의 통합 모델만으로 모든 변수를 동시에 처리한다.
논문은 또한 OmniFold이 기존 IBU와 수학적으로 일치함을 증명한다. 빈을 충분히 세분화하면 PFN이 학습하는 확률비는 R_ij와 동일한 형태가 되며, 따라서 OmniFold은 IBU의 이산 버전으로 볼 수 있다. 그러나 OmniFold은 연속적인 확률밀도 함수로 일반화되어, 고차원 데이터와 보조 변수들을 자연스럽게 포함한다.
한계점으로는 (i) 대규모 시뮬레이션 샘플이 필요하고, (ii) 신경망 구조와 하이퍼파라미터 선택에 따라 편향이 발생할 수 있으며, (iii) 반복 횟수가 많아질 경우 과적합 위험이 존재한다는 점을 언급한다. 향후 연구 방향으로는 베이지안 신경망을 통한 가중치 불확실성 추정, 다양한 물리량에 대한 사후 재가중치(reweighting) 가능성, 실제 LHC Run 2/3 데이터에 대한 적용 및 검증, 그리고 시스템atics(예: PDF, 시뮬레이션 튜닝) 전파 방법론 개발이 제시된다.
결론적으로 OmniFold은 “한 번에 모든 관측량을 언폴딩한다”는 새로운 패러다임을 제시하며, 고차원 데이터 분석이 일상화된 현대 입자 물리학에서 기존 히스토그램 기반 방법을 대체할 강력한 도구가 될 전망이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기