비디오에서 애니메이션으로의 무쌍 모션 스타일 전송
초록
본 논문은 스타일 레이블만 있는 비쌍(unaligned) 모션 데이터로부터 학습하여, 3D 애니메이션에 비디오에서 추출한 스타일을 적용하는 새로운 프레임워크를 제안한다. 콘텐츠와 스타일을 각각 별도의 잠재 코드로 분리하고, 시간 불변 적응형 인스턴스 정규화(AdaIN)를 이용해 스타일을 변환한다. 2D 관절 위치만으로도 스타일을 추출할 수 있어 3D 재구성 없이도 동영상에서 직접 스타일을 가져올 수 있다.
상세 분석
이 연구는 기존 모션 스타일 전송 방법이 요구하던 ‘쌍(pair)’ 데이터와 대규모 스타일 샘플의 한계를 극복한다. 핵심 아이디어는 모션을 콘텐츠 코드와 스타일 코드라는 두 개의 잠재 표현으로 분해하는 것이다. 콘텐츠 코드는 3D 관절 회전 데이터를 입력으로 받아 시간적 컨볼루션 네트워크(TCN)로 인코딩되며, 고차원 특징 맵을 생성한다. 스타일 코드는 3D 관절 위치 혹은 2D 관절 좌표(비디오에서 추출)에서 별도의 인코더를 통해 얻으며, 차원 수가 제한된 벡터 형태이다.
디코더 단계에서 콘텐츠 특징 맵에 시간 불변 AdaIN을 적용한다. AdaIN은 각 채널의 평균과 분산을 스타일 코드가 제공하는 통계값으로 교체함으로써, 전체 시퀀스의 시간적 형태는 유지하면서 스타일에 해당하는 색채(즉, 움직임의 강도, 리듬, 관절 가속도 등)를 조절한다. 이 방식은 이미지 스타일 전송에서 성공한 AdaIN을 시간 연속성을 보존하도록 확장한 것으로, 기존 방법이 필요로 했던 프레임별 정합(pairwise correspondence)을 요구하지 않는다.
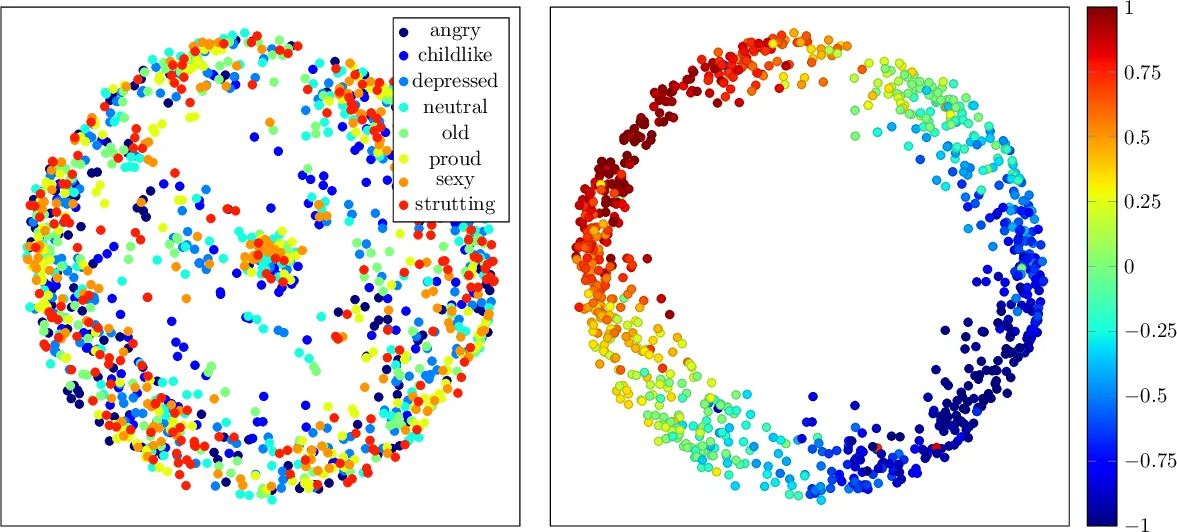
또한, 스타일 인코더는 공동 임베딩 공간을 학습한다. 3D 모션과 그 2D 투영이 서로 다른 인코더를 거쳐 동일한 스타일 코드에 매핑되도록 손실 함수를 설계했으며, 이는 비디오에서 직접 스타일을 추출할 수 있게 만든다. 이 공동 임베딩은 스타일 간 보간(interpolation)과 스타일 거리 측정도 가능하게 한다.
학습 목표는 두 가지 손실로 구성된다. 첫째, 콘텐츠 일관성 손실은 동일 스타일 레이블을 가진 입력(콘텐츠와 스타일이 같은 경우)에서 원본 콘텐츠가 재구성되도록 강제한다. 둘째, 스타일 분리 손실은 서로 다른 스타일 레이블을 가진 샘플 간에 스타일 코드가 구별되도록 한다. 인스턴스 정규화와 잠재 코드 차원 제한을 통해 단순히 콘텐츠를 복사하는 것을 방지한다.
실험에서는 무쌍 데이터만으로 학습했음에도 불구하고, 기존의 쌍 기반 최첨단 방법과 동등하거나 더 나은 결과를 얻었다. 특히, 훈련 시 보지 못한 새로운 스타일을 단일 예시 영상만으로도 성공적으로 전송했으며, 이는 스타일 추출이 2D 비디오에서도 가능함을 입증한다. 전체 시스템은 시간적 컨볼루션과 AdaIN 기반 변환으로 실시간에 가까운 속도로 동작한다.
댓글 및 학술 토론
Loading comments...
의견 남기기