오디오 캡션 듣고 말하기
본 논문은 청각 장면을 자연어 문장으로 기술하는 “오디오 캡션” 과제를 정의하고, 병원 현장을 중심으로 10시간 분량의 한·영 이중 라벨링 데이터셋을 구축하였다. 베이스라인으로 GRU 기반 인코더‑디코더 모델을 제시하고, 로그멜스펙트로그램과 필터뱅크 특징을 비교한다. BLEU 점수는 인간 수준에 근접하지만, 인간 평가에서는 여전히 품질 차이가 드러난다.
저자: Mengyue Wu, Heinrich Dinkel, Kai Yu
본 논문은 청각 장면을 인간과 유사하게 이해하고 서술할 수 있는 “오디오 캡션”이라는 새로운 과제를 제시한다. 기존 오디오 데이터베이스(예: AudioSet, TUT Acoustic Scenes, UrbanSound)는 주로 단일 이벤트에 대한 라벨링에 머물러 있어, 복합적인 청각 상황을 설명하기엔 한계가 있었다. 저자들은 인간이 청각 정보를 처리할 때 “무엇이 들리는가”, “누가 만들었는가”, “어떻게 들리는가”, “어디서 발생했는가”라는 네 가지 차원을 동시에 고려한다는 인지 모델을 기반으로, 이러한 정보를 자연어 문장으로 표현하는 데이터셋을 구축하였다.
데이터 수집은 중국의 주요 동영상 플랫폼(Youku, iQiyi, Tencent)에서 10초 길이의 비디오 클립을 추출하고, 배경음악을 최소화해 실제 생활 소리를 최대한 보존하도록 설계되었다. 현재는 병원 현장에 초점을 맞춰 3710개의 클립(약 10시간)으로 구성된 라벨링을 공개했으며, 향후 은행, 자동차, 가정, 회의실 등 4가지 추가 시나리오를 순차적으로 확장할 계획이다. 라벨링 과정은 세 명의 대학생 라이터가 동일 클립에 대해 자유 서술형 Mandarin 캡션을 작성하고, 이후 Baidu 번역기를 이용해 영문으로 번역하였다. 라벨링 단계에서는 “소리 정의”, “소리 주체”, “소리 속성”, “소리 위치” 네 질문을 제시해 라이터가 체계적으로 정보를 정리하도록 유도했으며, 최종적으로 각 클립당 3개의 인간 레퍼런스 문장이 확보되었다.
텍스트 전처리는 Stanford NLP 토크나이저를 사용해 Mandarin 문장을 어절 단위로 토큰화하고, 영문 역시 동일 파이프라인을 적용했다. 음성 특징은 두 종류를 실험했는데, 128차원 로그멜스펙트로그램(LMS)과 64차원 필터뱅크(FBANK)이다. LMS는 40 ms 윈도우와 20 ms 시프트, FBANK은 20 ms 윈도우와 10 ms 시프트로 추출했으며, 훈련 데이터의 평균·표준편차로 정규화하였다.
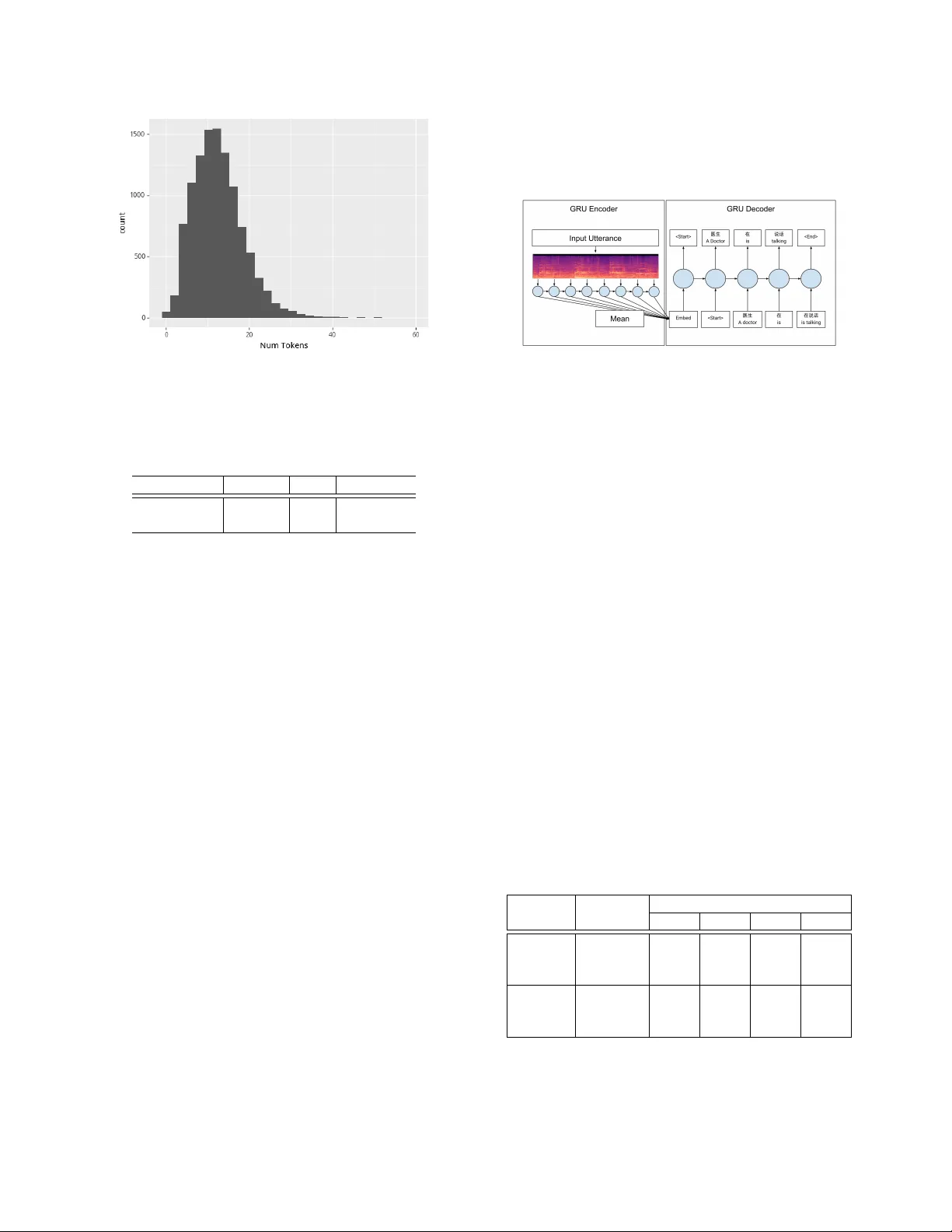
베이스라인 모델은 인코더‑디코더 구조를 채택했으며, 인코더는 단일 층 GRU로 구성해 입력 시퀀스 전체 타임스텝의 은닉 상태를 평균(pool)해 512 차원의 고정 벡터 u를 만든다. 이 벡터는 디코더 입력에 연결되어, 디코더 역시 단일 층 GRU와 256 차원 임베딩, 드롭아웃을 적용해 다음 토큰을 순차적으로 예측한다. 손실 함수는 토큰별 음성 로그우도(Negative Log Likelihood)이며, 최대 20 epoch 학습 후 검증 퍼플렉시티가 가장 낮은 모델을 선택한다. 생성 단계에서는 greedy 방식을 사용해 최대 50 토큰까지 출력한다.
평가 지표는 언어에 독립적인 BLEU‑1~4를 사용했으며, 인간 레퍼런스 3개와 모델 출력 1개를 비교했다. 결과적으로 LMS 기반 모델이 BLEU‑4에서 0.069~0.086 점을 기록해 FBANK보다 약간 우수했으며, 인간 레퍼런스와의 BLEU 차이는 0.01~0.02 수준으로 매우 근접했다. 그러나 인간 평가에서는 8명의 원어민이 모델 캡션에 평균 1.89점(1~4 척도)을 부여해, 인간 레퍼런스(2.88점)보다 현저히 낮았다. 통계적으로도 p < 0.001의 유의미한 차이가 나타났으며, Fleiss’ Kappa가 0.82로 높은 일관성을 보였지만, 인간 레퍼런스 간 합의는 낮아(κ≈0.28) 인간 평가가 주관적임을 보여준다.
논문은 이러한 결과를 두 가지 관점에서 해석한다. 첫째, 데이터셋이 비교적 작고 특정 도메인(병원)에 편중돼 있어, 모델이 제한된 어휘와 구문을 반복하는 경향이 있다. 실제 인간 레퍼런스는 1236개의 고유 단어를 사용한 반면, 모델은 193개에 불과했다. 둘째, BLEU 점수는 n‑gram 일치에 초점을 맞추어 의미적 다양성이나 흐름을 충분히 반영하지 못한다는 점이다. 따라서 향후 연구에서는 대규모 다도메인 데이터 구축, Transformer 기반의 더 깊은 모델, 멀티모달(영상·텍스트·음성) 연계 학습, 그리고 인간 평가와 일치하는 새로운 자동 평가지표 개발이 필요하다.
결론적으로, 이 연구는 오디오 캡션이라는 새로운 과제를 정의하고, 최초의 Mandarin‑English 이중 라벨링 데이터셋과 베이스라인 모델을 제공함으로써 청각 인식 연구의 범위를 이미지·비디오 캡션과 동등하게 확장하는 초석을 놓았다. 향후 연구자들은 이 데이터와 코드를 기반으로 더 정교한 모델을 개발하고, 청각 장애인 지원, 자동 청각 감시 등 실용적인 응용 분야에 적용할 수 있을 것으로 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기