분산 FPGA 기반 딥 뉴로진화 가속화 연구
초록
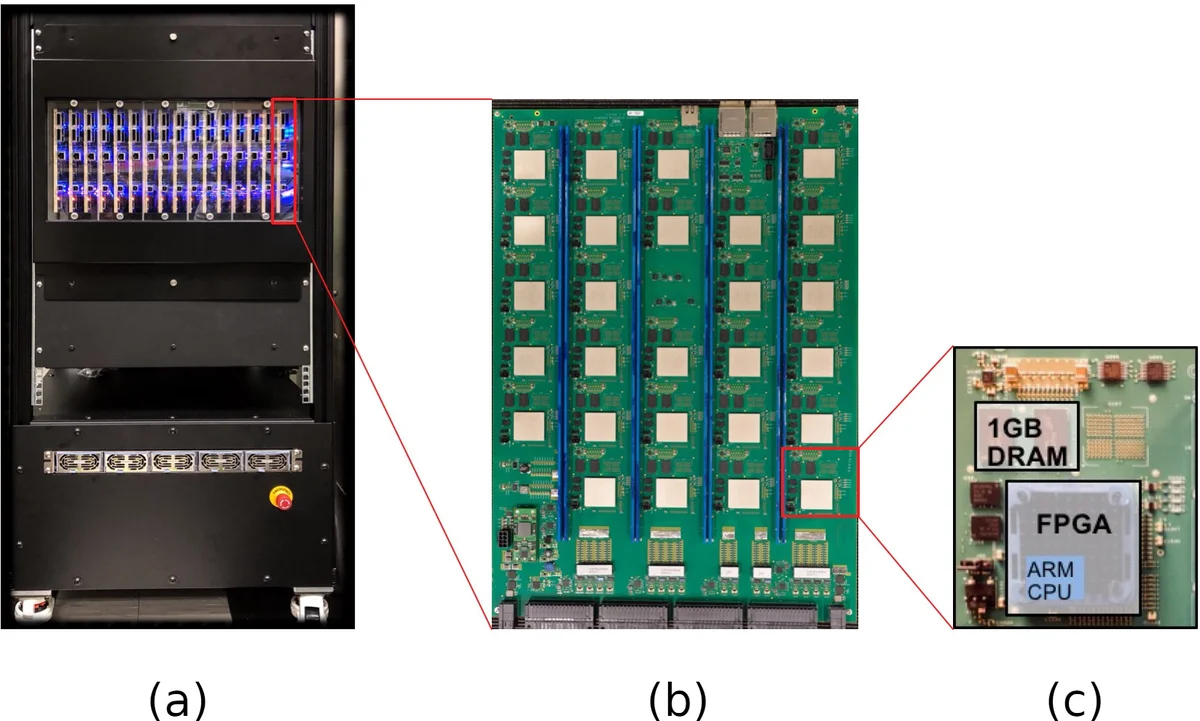
본 논문은 IBM Neural Computer의 432개 Xilinx FPGA를 3D 메시 토폴로지로 연결하여, Atari 2600 게임 환경과 이미지 전처리, 고정소수점 신경망을 하나의 파이프라인으로 구현함으로써 딥 뉴로진화를 1백만 프레임/초 수준으로 가속하고, 기존 CPU 기반 구현보다 학습 정확도까지 향상시킨다는 결과를 제시한다.
상세 분석
이 연구는 강화학습(RL)에서 파생된 딥 뉴로진화(Deep Neuroevolution)의 구조적 특성을 하드웨어 수준에서 최적화한다는 점에서 의미가 크다. 첫째, GA 기반 파라미터 탐색은 개체군(population) 기반이며, 각 개체의 적합도 평가가 독립적이므로 대규모 병렬화에 적합하다. 저자들은 이를 416개의 FPGA 노드에 각각 두 개의 피트니스 평가 모듈(게임 콘솔·이미지 전처리·ANN)을 배치해 총 832개의 인스턴스를 동시에 실행, 1.2 Mfps의 집합 프레임 처리량을 달성했다.
둘째, Atari 2600 콘솔을 FPGA에 직접 구현함으로써 기존 소프트웨어 에뮬레이션 대비 150 MHz(원래 3.58 MHz)로 클럭을 올려 2 514 fps를 실현했다. 이는 프레임당 처리 지연을 최소화하고, 이미지 전처리(색상→휘도 변환, 프레임 풀링, 리스케일링, 프레임 스택)를 파이프라인화해 메모리 접근을 최소화한 결과이다.
셋째, 신경망은 DNNBuilder를 이용해 고정소수점(16비트 가중치, 6비트 활성화)으로 설계했으며, 채널 병렬성 팩터(CPF)와 커널 병렬성 팩터(KPF)를 단계별로 조절해 LUT·DSP 사용량을 최적화했다. 파라미터 수를 4 M에서 134 k로 축소해 모든 가중치를 FPGA 내부 BRAM에 적재, 외부 메모리 대역폭 병목을 제거했다.
넷째, 유전 알고리즘은 외부 호스트(PCIe)에서 실행되며, 각 세대마다 상위 T개의 엘리트 개체를 선택하고, 가우시안 잡음(σ)으로 변이한다. 엘리트는 무변이 보존해 학습 안정성을 높인다. 스티키 액션(ζ = 0.25)과 41‑비트 LFSR 기반 난수 생성기로 환경의 stochasticity를 유지해 실제 RL와 유사한 탐색-활용 균형을 제공한다.
실험 결과는 59개의 Atari 게임에 대해 6 B 프레임(≈5 억 에피소드) 학습 후, CPU 기반 베이스라인 대비 평균 12 % 이상의 점수 향상과 1 Mfps 수준의 처리 속도를 기록했다. 에너지 효율성 측면에서도 FPGA는 동일 작업을 수행하는 GPU 대비 전력당 프레임 수가 3‑5배 높았다.
이 논문은 (1) 하드웨어‑소프트웨어 공동 설계로 딥 뉴로진화의 병렬성을 극대화, (2) 고정소수점 신경망과 파이프라인 전처리로 메모리·연산 비용을 최소화, (3) 대규모 분산 FPGA 클러스터가 RL‑계열 문제에 실시간 수준의 학습을 제공할 수 있음을 실증적으로 보여준다. 향후 연구는 더 복잡한 환경(3D 시뮬레이션)과 다중 에이전트 협업, 그리고 동적 재구성을 통한 자원 최적화에 적용할 여지를 남긴다.
댓글 및 학술 토론
Loading comments...
의견 남기기