대규모 서비스 환경에서 빠른 차원 분석을 통한 근본 원인 탐색
본 논문은 수백 개의 특성을 가진 수백만 건의 구조화 로그를 대상으로, Apriori와 FP‑Growth 기반의 빈발 항목 집합 마이닝을 활용한 근본 원인 분석 프레임워크를 제안한다. Scuba 실시간 메모리 DB를 이용한 사전 집계, 불필요한 컬럼 필터링, 지원도와 lift 기반 후처리, 그리고 병렬 처리를 결합해 대규모 데이터에서도 수초~수분 내에 의미 있는 연관 규칙을 도출한다. 실제 페이스북 인프라에 적용한 사례와 실험 결과가 제시된다.
저자: Fred Lin, Keyur Muzumdar, Nikolay Pavlovich Laptev
논문은 대규모 인터넷 서비스 기업에서 발생하는 복잡한 장애 원인을 빠르게 파악하기 위한 차원 분석 프레임워크를 제안한다. 서론에서는 글로벌 데이터센터에 분산된 하드웨어·소프트웨어·툴링 로그가 별도 저장돼 통합 분석이 어려운 현실을 제시하고, 기존 로지스틱 회귀·결정 트리 기반 방법이 해석성·특징 엔지니어링 문제로 실용성이 떨어짐을 지적한다. 이어서 기존 근본 원인 분석 연구들을 검토하며, STUCCO와 같은 대비 집합 마이닝이 중요한 연관을 놓칠 수 있음을 설명한다.
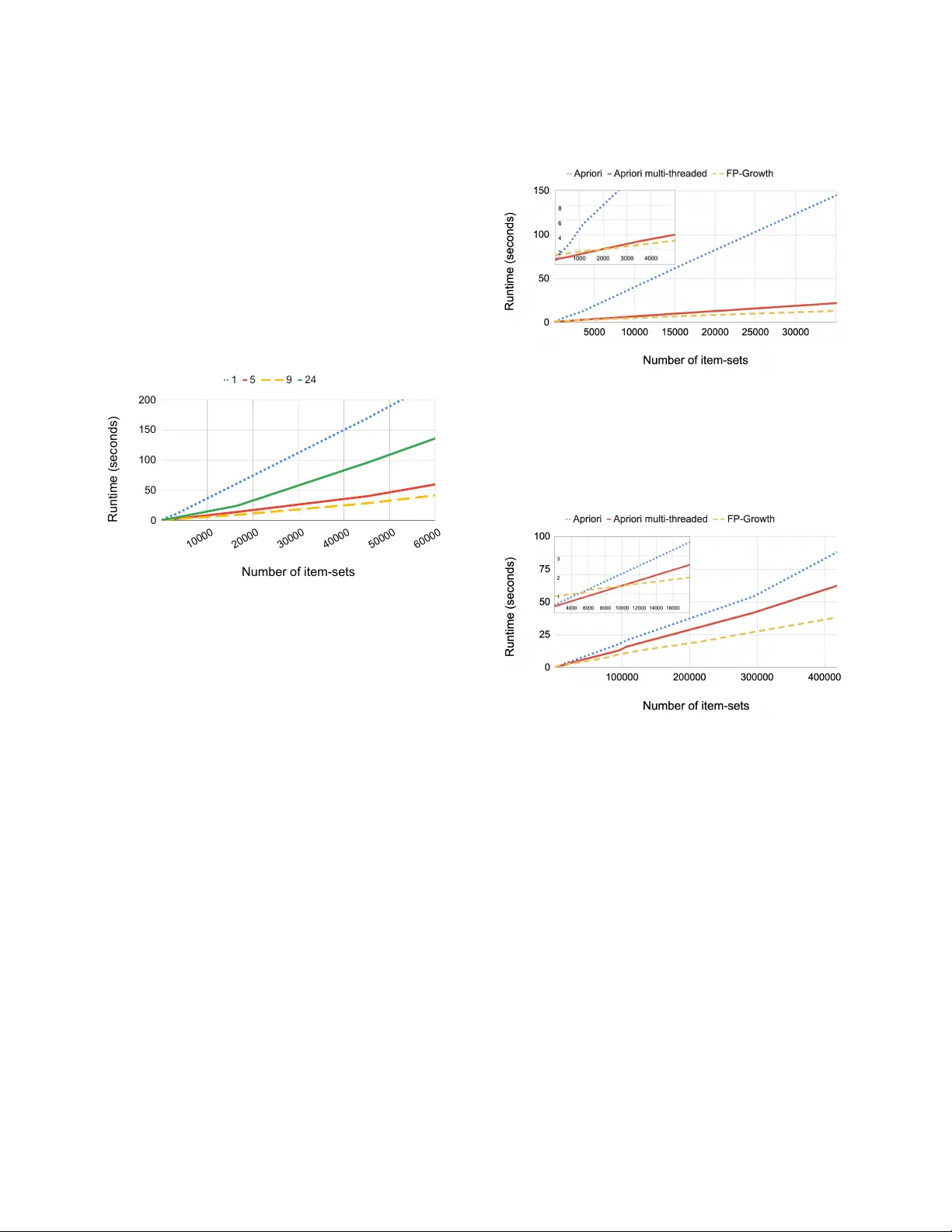
본 연구의 핵심은 빈발 항목 집합 마이닝을 활용한 연관 규칙 추출이다. 로그를 구조화된 테이블 형태로 변환하고, 각 컬럼 값을 아이템으로 정의한다. Apriori 알고리즘은 후보 생성과 다중 스캔을 통해 빈발 아이템 집합을 찾지만, 아이템 수가 많아지면 지수적 복잡도가 문제가 된다. 이를 보완하기 위해 FP‑Growth를 도입한다. FP‑Tree를 구축해 후보 생성을 생략하고, 재귀적으로 빈발 패턴을 추출함으로써 메모리와 시간 효율을 크게 개선한다. 논문은 실험을 통해 FP‑Growth가 대규모 데이터에서 Apriori 대비 50 % 이상 빠른 성능을 보인다고 보고한다.
대규모 서비스 환경에서 로그 양이 방대하기에, 저자들은 Scuba라는 실시간 인메모리 데이터베이스를 활용해 사전 집계(pre‑aggregation)를 수행한다. 동일한 특성 조합을 하나의 레코드로 압축함으로써 데이터 크기를 500배 이상 감소시키고, 이후 FP‑Growth에 투입한다. 또한, 사용자가 분석에 불필요한 컬럼을 지정해 제외할 수 있는 자동 컬럼 필터링 기능을 제공한다. 지원도(support)와 상승도(lift)를 주요 평가 지표로 채택한다. 지원도는 목표 실패 상태(Y) 내에서 아이템 집합 X가 차지하는 비율을 나타내며, 하위 집합의 빈도 보존을 보장한다. 상승도는 X와 Y의 결합 확률이 독립적 기대값 대비 얼마나 높은지를 측정해, 흔히 발생하지만 원인과 무관한 아이템을 걸러낸다. 따라서 최종 결과는 높은 lift와 충분한 support를 동시에 만족하는 규칙들로 제한된다.
프레임워크는 병렬 처리와 자동 필터링을 결합해 확장성을 확보한다. 데이터 파티셔닝을 통해 여러 워커가 동시에 FP‑Tree를 구축하고, 결과를 합치는 방식으로 CPU 활용도를 최적화한다. 실험에서는 1억 건 로그(수백 GB)에서 메모리 사용량을 2 GB 이하로 유지하면서 전체 파이프라인을 3분 이내에 완료했으며, 기존 Spark 기반 FP‑Growth 대비 30 % 정도의 메모리 절감 효과를 보였다.
실제 적용 사례로는 (1) 하드웨어 펌웨어와 커널 버전 조합이 서버 재부팅 실패와 강하게 연관된 경우, (2) 특정 서비스 설정이 자동 복구 작업에서 오류를 일으키는 경우, (3) 특정 머신·메모리 할당 패턴이 작업 예외와 높은 상관관계를 보이는 경우 등을 제시한다. 각 사례에서 도출된 연관 규칙은 운영 엔지니어가 즉시 원인을 파악하고 대응 조치를 취할 수 있게 해준다. 마지막으로, 논문은 현재 프레임워크가 실시간 근본 원인 분석에 적합하지만, 희소한 오류 패턴 탐지를 위해 더 정교한 통계적 검증과 온라인 학습 기법을 도입하는 것이 향후 과제라고 결론짓는다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기