약한 시연을 활용한 대화 정책 학습
초록
본 논문은 대규모 멀티도메인 대화 시스템에서 강화학습(DRL) 기반 대화 관리자를 학습하기 위해, 완전 라벨링된 데이터가 아닌 약한 시연(weak demonstrations)을 활용하는 방법을 제안한다. Full Label Expert(FLE), Reduced Label Expert(RLE), No Label Expert(NLE)라는 세 단계의 전문가 모델을 설계하고, 이를 Deep Q‑learning from Demonstrations(DQfD)에 통합한다. 또한, 환경에서 수집된 전이 데이터를 이용해 전문가를 지속적으로 미세조정하는 Reinforced Fine‑tune Learning(RoFL) 알고리즘을 도입해 도메인 간 격차를 완화한다. ConvLab·MultiWOZ 기반 실험에서 약한 시연만으로도 높은 성공률을 달성함을 입증한다.
상세 분석
이 연구는 대화 관리(DM)를 강화학습으로 최적화할 때 직면하는 두 가지 핵심 문제, 즉 “대규모 상태·행동 공간”과 “희소한 보상”을 약한 시연을 통해 해결하고자 한다. 기존 DQfD는 강력한 규칙 기반 혹은 완전 라벨링된 전문가 시연을 필요로 했지만, 논문은 라벨링 비용을 단계적으로 낮춘 세 종류의 전문가를 설계한다. 첫 번째인 Full Label Expert(FLE)는 전통적인 지도학습 방식으로, 대화 상태를 입력받아 정확한 시스템 행동을 예측한다. 여기서는 DQfD의 원래 큰 마진 손실을 그대로 적용한다. 두 번째인 Reduced Label Expert(RLE)는 모든 도메인에서 공통적으로 사용되는 ‘inform’, ‘request’, ‘other’와 같은 고수준 라벨만을 예측하도록 설계했으며, 예측된 라벨 집합에서 무작위로 행동을 샘플링해 시연으로 사용한다. 이를 위해 보조 손실의 마진 항을 라벨 집합에 맞게 변형하였다. 세 번째인 No Label Expert(NLE)는 전혀 라벨이 없는 대화 텍스트 쌍을 이용해, 주어진 사용자 발화에 대한 적절한 시스템 응답을 판단하는 이진 분류 모델이다. 긍정 예시와 무작위 샘플링한 부정 예시를 통해 학습하고, 일정 임계값 이상을 보이는 응답 집합을 시연으로 제공한다. 이러한 약한 시연은 모두 DQfD의 replay buffer에 사전 채워짐으로써, 초기 탐색 단계에서 유의미한 Q‑값 업데이트를 가능하게 한다.
또한, 논문은 전문가와 환경 사이의 도메인 격차를 줄이기 위해 Reinforced Fine‑tune Learning(RoFL)이라는 알고리즘을 제안한다. RoFL은 사전 학습 단계에서 약한 전문가가 생성한 전이 중 보상이 일정 임계값을 초과하는 경우를 ‘인‑도메인’ 데이터로 수집하고, 일정 주기마다 이를 이용해 전문가 네트워크를 미세조정한다. 이렇게 업데이트된 전문가가 최종 DQfD 시연을 제공함으로써, 초기 약한 시연이 점진적으로 환경에 맞게 개선된다.
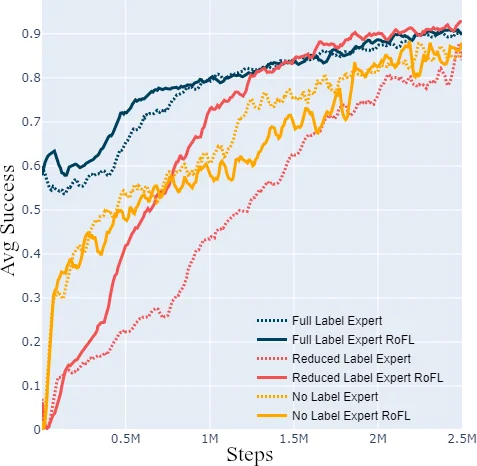
실험은 멀티도메인 대화 프레임워크인 ConvLab( MultiWOZ 기반)에서 수행되었으며, FLE, RLE, NLE 각각을 사용한 DQfD 에이전트가 성공률, 대화 길이, 보상 측면에서 기존 규칙 기반 시연 대비 우수한 성능을 보였다. 특히 RLE와 NLE는 라벨링 비용이 거의 들지 않음에도 불구하고, RoFL을 적용했을 때 성능 격차가 크게 감소하였다. 이 결과는 약한 시연이 충분히 강력한 지도 신호를 제공할 수 있음을 입증한다.
핵심 기여는 (1) 라벨링 비용을 단계적으로 낮춘 세 종류의 전문가 설계, (2) DQfD와의 원활한 통합을 위한 손실 함수 변형, (3) RoFL을 통한 도메인 적응 메커니즘 제시이며, 이는 대규모 실제 서비스에 적용 가능한 저비용 대화 정책 학습 방법론으로 평가된다.
댓글 및 학술 토론
Loading comments...
의견 남기기