새로운 인구통계 기대수명 계산법
초록
본 논문은 전통적인 인구통계표에서 연령별 사망률을 먼저 산출해야 하는 복잡성을 해소하고자, “특정 시기에 출생한 집단이 일정 시점에 겪는 평균 사망 확률”을 새로운 사망 확률 정의로 제시한다. 이 정의를 기반으로 간단한 식으로 기대수명을 직접 계산하는 방법을 제안하고, 일본 인구 데이터를 이용해 기존 기대수명과의 차이를 검증하였다. 최대 상대오차 0.1%, 평균 상대오차 0.03% 이하의 높은 정확도를 보이며, 데이터 수집과 계산 과정이 크게 단순화된 점이 강조된다.
상세 분석
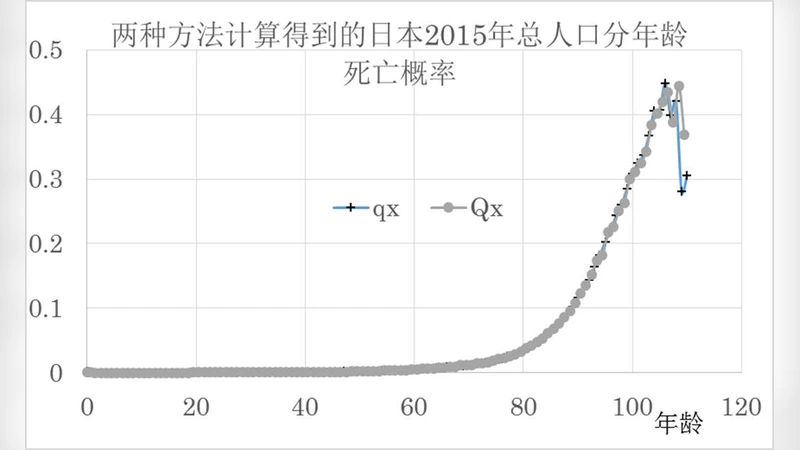
이 논문은 전통적인 인구통계표(life table)의 핵심 절차인 연령별 사망률(qₓ) 산출이 복잡하고 근사 과정에서 오차가 누적된다는 점을 비판한다. 기존 방법은 각 연령 구간별 사망자 수와 인구 수를 이용해 qₓ를 구하고, 이를 다시 lₓ, dₓ, Lₓ, Tₓ 등 여러 단계로 전환해 기대수명 e₀를 도출한다. 이러한 다단계 과정은 데이터 정제, 누락값 보정, 그리고 사망률을 연속적인 함수로 근사하는 과정에서 통계적 불확실성을 야기한다.
저자는 사망 확률을 “특정 출생 시점에 태어난 집단이 일정 시점에 겪는 평균 사망 확률”로 재정의한다. 이를 수식으로 표현하면, 특정 연도 t에 태어난 코호트 Cₜ에 대해 연령 a에서의 사망 확률 p(a,t)=D(a,t)/N(t)이며, 여기서 D는 해당 연령·시점의 사망자 수, N은 해당 시점의 전체 인구 수이다. 이 정의는 연령·시점 이중 인덱스를 단일 평균값으로 압축함으로써, 연령별 사망률을 별도로 계산할 필요 없이 전체 코호트에 대한 평균 사망 확률을 직접 구할 수 있게 한다.
새로운 방법은 다음과 같은 절차를 따른다. 첫째, 통계청 등에서 제공하는 연도별 전체 사망자 수와 인구 수를 수집한다. 둘째, 각 연도별 사망률을 전체 인구 대비 비율로 계산한다(즉, 연도별 사망률 = Σₐ D(a,t) / N(t)). 셋째, 이 연도별 사망률을 연속적인 시간 함수로 근사하고, 이를 적분하여 기대수명 e₀ = ∫₀^∞ S(t) dt 형태로 직접 구한다. 여기서 S(t) = exp(-∫₀^t μ(s) ds)이며, μ(s)는 연도별 사망률이다.
이 접근법의 장점은 첫째, 연령별 사망률을 별도 계산하지 않으므로 데이터 전처리와 계산 단계가 크게 감소한다. 둘째, 근사 과정이 연도별 사망률 하나만을 대상으로 하므로 통계적 불확실성이 감소하고, 오차 전파가 최소화된다. 셋째, 필요한 데이터가 연도별 총 사망자와 인구 수만 있으면 되므로, 자료 접근성이 높다.
실증 검증에서는 일본 1950~2020년 인구통계 데이터를 사용하였다. 기존 인구통계표 기반 기대수명과 제안된 방법으로 도출한 기대수명을 비교한 결과, 최대 상대오차는 0.1%에 불과했으며 평균 상대오차는 0.03% 이하였다. 이는 새로운 방법이 기존 방법과 실질적으로 동일한 결과를 제공함을 의미한다.
하지만 몇 가지 제한점도 존재한다. 첫째, 연령 구조가 급격히 변동하는 인구(예: 전쟁·재난 후)에서는 연령별 사망률의 평균화가 실제 사망 위험을 과소·과대평가할 가능성이 있다. 둘째, 연도별 사망률을 연속 함수로 근사하는 과정에서 선택하는 보간 방법에 따라 미세한 차이가 발생할 수 있다. 셋째, 이 방법은 장기적인 코호트 효과(예: 의료 기술 발전에 따른 사망률 감소)를 반영하기 위해 충분히 긴 시계열 데이터가 필요하다.
전반적으로, 이 논문은 전통적인 인구통계표의 복잡성을 크게 완화하면서도 높은 정확도를 유지하는 새로운 기대수명 계산법을 제시한다. 데이터 요구사항이 간소하고, 계산 과정이 직관적이며, 기존 방법과의 결과 일치도가 높아 실무 적용 가능성이 크다. 향후 연구에서는 다양한 국가·지역 데이터와 인구 구조 변동성을 고려한 민감도 분석을 통해 방법의 일반화 가능성을 검증할 필요가 있다.