지열 시계열 회귀를 위한 데이터 전처리 프로토콜
초록
본 연구는 비균등 시간 간격으로 생성된 지열 온도 시계열 데이터를 효율적으로 회귀 분석에 활용하기 위한 여섯 가지 데이터 선택 스킴을 제안한다. 정규화, 축 간 균등 분할, 곡선 길이 기반 등 다양한 기준을 적용해 전체 9 939점 중 1 %~20 %만을 추출했으며, R²와 NRMSE 지표를 통해 스킴별 모델 적합성을 평가하였다. 결과는 선택된 점의 수가 일정 범위 내에서는 회귀 성능에 큰 영향을 미치지 않으며, 스킴에 따라 데이터 특성을 보존하면서도 계산 비용을 크게 절감할 수 있음을 보여준다.
상세 분석
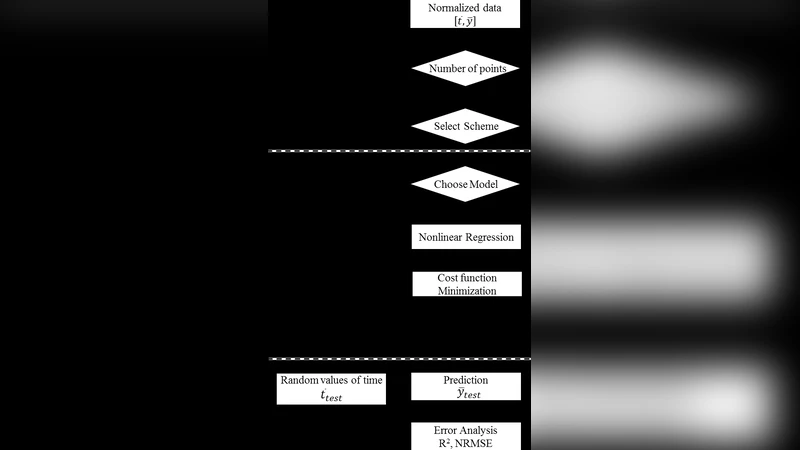
본 논문은 시뮬레이션 혹은 실험으로부터 얻어진 비균등 간격의 시간‑온도 데이터를 회귀 모델에 적용할 때, 데이터 포인트의 과다 사용이 반드시 모델 정확도를 향상시키지는 않는다는 점을 전제로 한다. 이를 해결하기 위해 저자는 먼저 X‑축(시간)과 Y‑축(온도)의 값 범위 차이를 보정하기 위해 0‒1 정규화를 수행한다(식 1, 2). 정규화 후 전체 9 939점 중 일부만을 선택하는 여섯 가지 스킴을 설계했으며, 각 스킴은 다음과 같은 기준을 가진다.
- 스킴 1 (전체 데이터): 기준선으로 모든 데이터를 사용한다.
- 스킴 2 (X‑축 균등 분할): 시간 구간을 동일한 길이로 나누어 각 구간에서 하나씩 선택한다(식 3‒4). 이 방식은 곡선의 기울기에 따라 점 간 거리(Δt·ΔT)가 달라지므로, 완만한 구간에 점이 밀집하고 급격한 구간에는 드물게 배치된다.
- 스킴 3 (Y‑축 균등 분할): 온도값을 동일 간격으로 나누어 선택한다(식 5‒6). 결과적으로 기울기가 큰 구간에 점이 집중되어, 온도 변화가 급격한 초기 구간을 더 정밀히 포착한다.
- 스킴 4 (곡선 길이 균등 분할): 전체 곡선의 아크 길이를 계산하고(식 7‒10), 이를 N등분하여 각 구간마다 동일한 아크 길이를 갖는 점을 선택한다. 이 방법은 기울기와 무관하게 점 밀도가 일정하게 유지되어 곡선 전체의 형태를 고르게 대표한다.
- 스킴 5 (곡률·각도 제한): 연속 점 사이의 기울기 변화 각도를 기준으로, 사전 정의된 각도 임계값을 초과하는 구간에 추가 점을 배치한다(식 11‒12). 급격한 곡률을 가진 구간을 자동으로 강조함으로써 비선형 특성을 보존한다.
- 스킴 6 (혼합 스킴): 스킴 3과 4를 결합해 온도 구간 균등성과 곡선 길이 균등성을 동시에 만족하도록 설계하였다.
각 스킴별로 1 %~20 %(약 100‒2 000점)의 데이터를 추출해 비선형 회귀 모델(예: 다항식, 지수 감쇠 모델 등)에 적용하고, 모델 적합도는 결정계수(R²)와 정규화 평균제곱근오차(NRMSE)로 평가하였다. 실험 결과, 스킴 4와 5는 전체 데이터를 사용했을 때와 비교해 R² 차이가 0.01 이하이며 NRMSE도 2 % 미만으로 변동이 거의 없었다. 반면 스킴 2와 3은 선택된 점이 기울기에 따라 편중되므로, 특정 구간에서 오차가 다소 증가하는 경향을 보였다. 특히 초기 급격한 온도 감소 구간을 충분히 포착하지 못하면 모델이 과소평가되는 현상이 관찰되었다.
이러한 분석을 통해 저자는 데이터 포인트 수가 반드시 모델 정확도를 좌우하지 않으며, 적절한 선택 기준을 적용하면 데이터 양을 크게 줄이면서도 핵심 물리적 특성을 유지할 수 있음을 입증하였다. 또한, 스킴 4와 5는 곡선의 전체 형태와 급격한 변화를 동시에 보존하므로, 향후 지열 시스템의 장기 예측, 민감도 분석, 불확실성 전파 등에 효율적인 전처리 방법으로 활용될 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기