강화 학습에서 적응형 트랜스포머의 성능 향상과 효율성
초록
본 연구는 부분 관찰 가능 강화 학습 환경에서 안정화된 트랜스포머(Stable Transformer)의 성능을 검증하고, 여기에 적응형 주의 범위(Adaptive Attention Span) 메커니즘을 도입하여 계산 비용을 줄이면서도 성능을 개선했음을 보여줍니다. 메모리 기반 DMLab30 환경에서 기존 모델 대비 향상된 결과를 확인했습니다.
상세 분석
이 논문의 핵심 기술적 기여는 강화 학습(RL) 도메인에 ‘적응형 주의 범위(Adaptive Attention Span)’ 메커니즘을 성공적으로 적용했다는 점입니다. 기존의 Stable Transformer 아키텍처는 TransformerXL(TXL)을 기반으로 하며, 고정된 메모리 블록 전체에 주의를 기울여야 하는 계산적 부담이 있었습니다. 저자들은 각 어텐션 헤드마다 학습 가능한 마스킹 변수 ‘z’를 도입하여, 필요한 과거 시간 스텝에만 선택적으로 주의를 집중할 수 있도록 했습니다. 이는 Equation 1에서 기존 소프트맥스 어텐션 계산에 마스킹 함수 m_z(t-r)을 곱하는 방식으로 구현되었습니다.
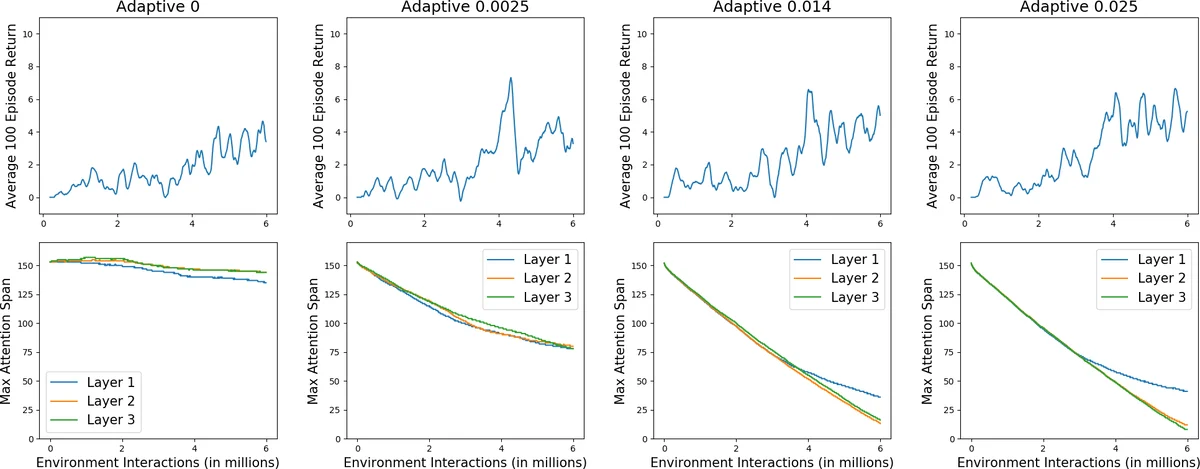
이 접근법의 주요 이점은 두 가지입니다. 첫째, 계산 효율성입니다. 모든 레이어가 전체 긴 문맥을 볼 필요 없이, 일부 레이어만 긴 범위의 의존성을捕捉하고 나머지는 짧은 범위의 로컬 정보에 집중함으로써 평균 주의 범위를 작게 유지할 수 있습니다. 실험 결과(Figure 4)에서 3층 모델의 1층은 최대 범위 33을, 2, 3층은 범위 2를 학습하여, 고정 범위 TXL 대비 상당한 계산 절감을 이루었습니다. 둘째, 구조적 정규화 역할입니다. L1 정규화를 주의 범위 파라미터에 적용함으로써(Figure 6), 모델이 특정 작업에 실제로 필요한 어텐션 레이어의 수와 깊이를 ‘학습’하게 하는 효과를 보였습니다. 이는 불필요한 계산을 사전에 차단하는 매우 매력적인 정규화 방식입니다.
실험 설계에서도 주목할 점은, 적응형 모델의 초기 메모리 길이를 Stable Transformer의 두 배(400)로 설정했다는 것입니다. 이는 모델이 각 레이어에서 필요한 최소 주의 범위를 학습할 경우, 더 큰 메모리를 사용하면서도 계산량은 비슷하게 유지할 수 있다는 가설을 검증하기 위함입니다. DMLab30의 ‘rooms_select_nonmatching_object’ 환경에서 적응형 모델이 더 높은 평균 보상과 더 낮은 분산으로 수렴한 결과(Figure 3 오른쪽, Table 1)는 이 가설을 지지하며, 메모리 집약적 POMDP 작업에서 적응형 주의 범위의 유용성을 입증했습니다.
댓글 및 학술 토론
Loading comments...
의견 남기기