셀룰러 GAN 학습의 병렬 분산 구현과 성능 분석
초록
**
본 논문은 GAN 훈련에 경쟁적 공동진화 방식을 적용한 Mustangs/Lipizzaner 프레임워크를 고성능 컴퓨팅 환경에서 실행할 수 있도록 MPI 기반의 분산 메모리 모델로 구현한다. 2×2‑4×4 토러스형 격자와 5셀 Moore 이웃을 이용해 생성기·판별기 집단을 동시에 학습시키고, 마스터‑슬레이브 구조와 하트비트 감시를 통해 작업 부하를 균등 배분한다. MNIST 손글씨 생성 실험에서 훈련 시간 감소와 확장성을 입증하였다.
**
상세 분석
**
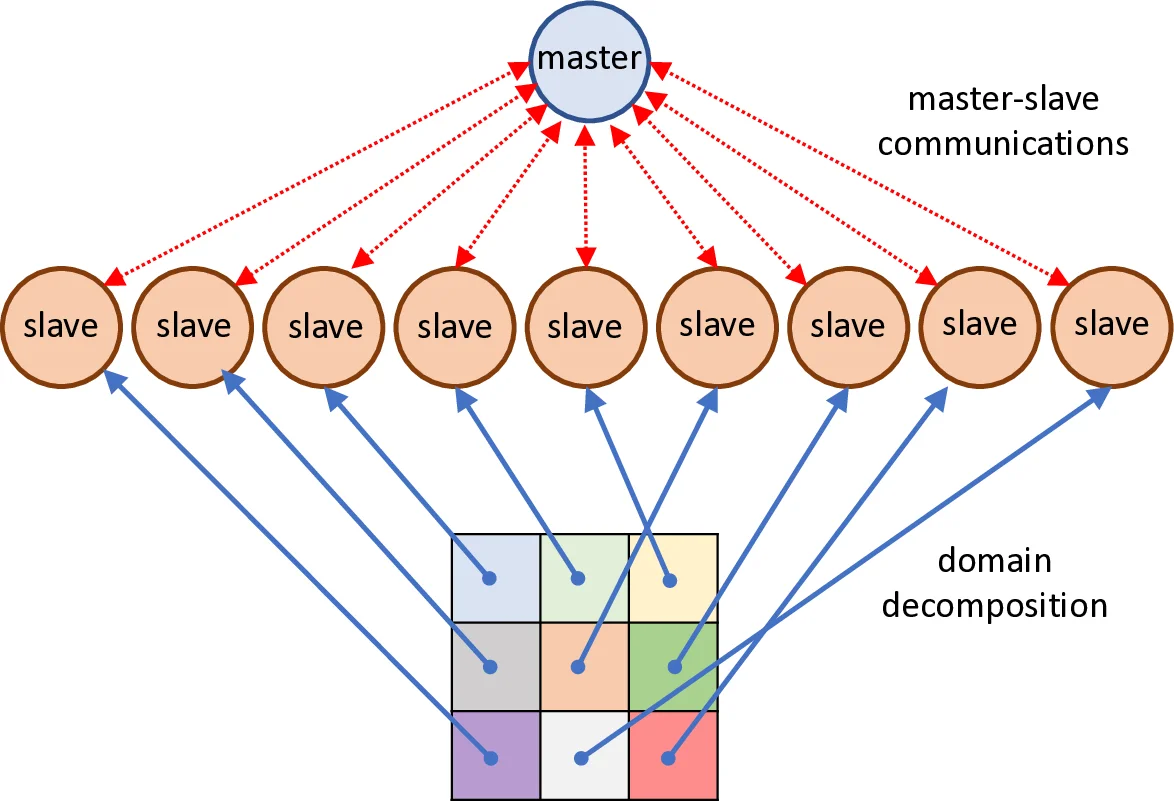
이 연구는 GAN 훈련의 불안정성을 완화하기 위해 다수의 생성기와 판별기를 동시에 진화시키는 공간적 공동진화 알고리즘을 채택한다. 기존 Mustangs/Lipizzaner 구현은 단일 노드에서 동기식으로 동작했으나, 본 논문은 두 단계의 병렬화를 도입한다. 첫 번째 단계는 MPI Cartesian 토폴로지를 이용해 격자 셀을 슬레이브 프로세스에 1:1 매핑함으로써 데이터와 파라미터를 지역적으로 교환한다. 두 번째 단계는 각 슬레이브 내부에서 멀티스레드(마스터 스레드와 트레이닝 스레드)로 구성해 CPU 기반 학습 루프와 향후 GPU 가속을 동시에 지원한다.
통신 구조는 세 개의 MPI 커뮤니케이터로 구분된다. WORLD 커뮤니케이터는 초기 설정 전파와 슬레이브 시작·종료 신호에 사용되고, LOCAL 커뮤니케이터는 동일 격자 내 활성 슬레이브 간의 집계(gather) 연산을 수행한다. 이는 각 이웃의 최신 생성기·판별기 파라미터를 즉시 공유하게 하여, 경쟁적 압력을 지속적으로 유지한다. GLOBAL 커뮤니케이터는 마스터가 모든 슬레이브로부터 최종 결과를 수집할 때 활용된다.
슬레이브 상태 머신은 ‘inactive → processing → finished’ 로 정의되며, 마스터는 하트비트 스레드를 통해 주기적으로 슬레이브의 상태를 모니터링한다. 이 설계는 노드 장애나 지연 발생 시 빠른 재스케줄링을 가능하게 하여 대규모 클러스터 환경에서의 견고성을 높인다.
실험에서는 MNIST 데이터셋을 대상으로 2×2, 3×3, 4×4 격자 규모를 테스트하였다. 격자 크기가 커질수록 전체 연산량은 증가하지만, 슬레이브당 작업량이 일정하게 유지되므로 평균 훈련 epoch당 소요 시간이 거의 선형적으로 감소한다. 특히 4×4 격자에서는 순차 구현 대비 약 6배 이상의 속도 향상을 기록했으며, 생성 이미지 품질을 평가하는 Inception Score에서도 경쟁적 공동진화가 모드 붕괴를 억제함을 확인했다.
이 구현은 순수 CPU 기반이지만, 트레이닝 스레드 내부에 GPU 연산을 삽입할 수 있는 인터페이스를 제공한다는 점에서 향후 확장성이 크다. 또한, 동적 이웃 재구성 기능을 통해 학습 중에 격자 토폴로지를 변경함으로써 다양한 탐색‑활용 균형을 실험할 수 있다. 전체적으로, 고성능 컴퓨팅 자원을 효율적으로 활용하면서 GAN 공동진화의 장점을 유지하는 설계가 돋보인다.
**
댓글 및 학술 토론
Loading comments...
의견 남기기