그래프 기반 신경망 구조 인코딩 GATES로 예측기 기반 NAS 효율 향상
초록
GATES는 연산을 정보 흐름의 변환으로 모델링하여 그래프 기반 신경망 구조를 일관되게 인코딩한다. 이는 기존 노드‑기반·엣지‑기반 인코딩의 한계를 극복하고, 구조 동형성을 자연스럽게 처리한다. 실험에서 GATES를 사용한 성능 예측기가 높은 순위 상관관계를 보였으며, 이를 기반으로 한 NAS는 적은 샘플로도 우수한 아키텍처를 찾는다.
상세 분석
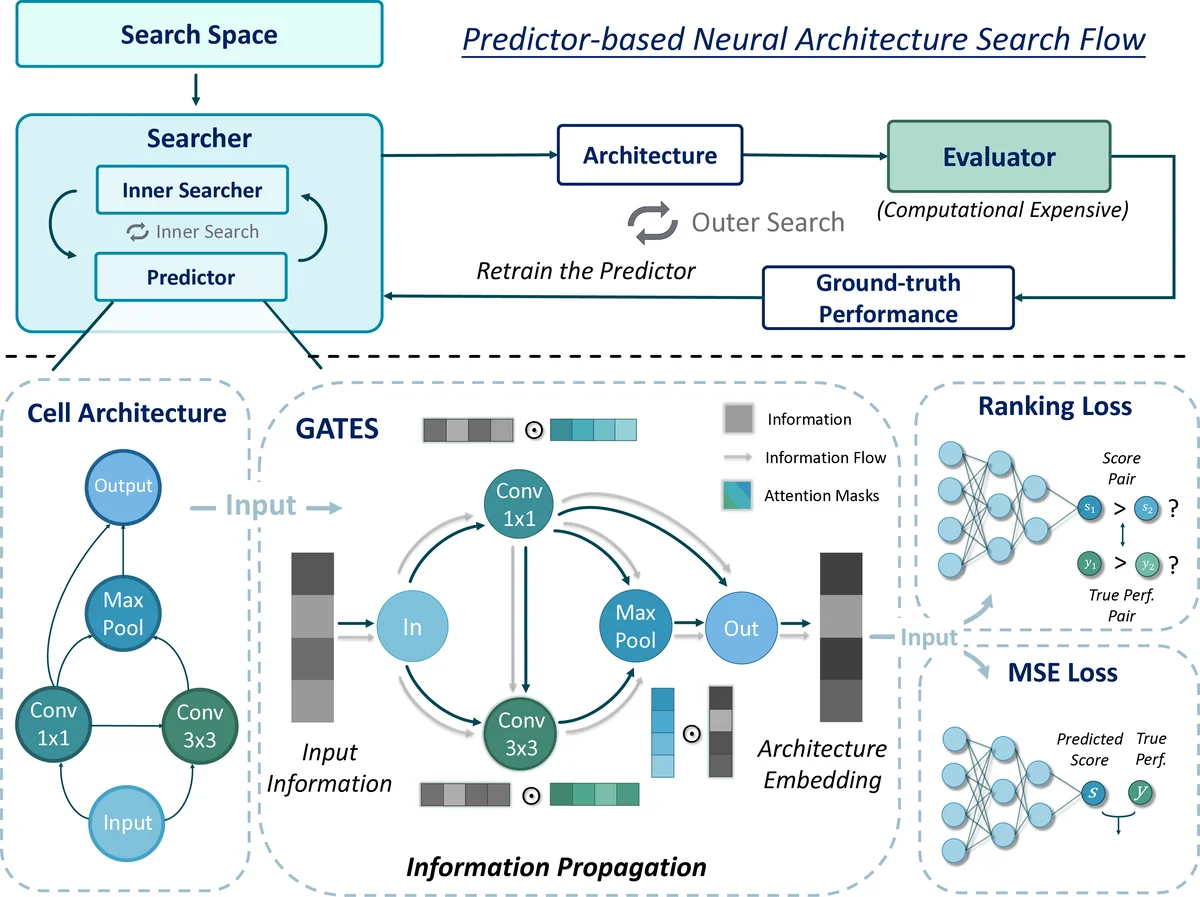
본 논문은 예측기 기반 NAS의 핵심인 “아키텍처 인코더” 설계에 초점을 맞추었다. 기존의 시퀀스 기반 인코더는 토폴로지를 암묵적으로만 반영해 표현력이 제한적이며, 그래프 컨볼루션(GCN) 기반 인코더는 연산을 노드 속성으로 취급한다. 이는 실제 신경망이 입력 텐서를 변환하는 데이터 흐름과는 거리가 있다. 특히 연산이 엣지에 위치하는 OOE(search space)에서는 GCN 적용이 어려워, 기존 연구는 노드에 엣지 연산을 연결해 임시적으로 해결했지만 동형성 처리에 결함이 있었다.
GATES는 이러한 문제를 해결하기 위해 연산을 “정보 변환 함수”로 정의한다. 입력 노드에 초기 정보(임베딩)를 부여하고, 각 연산(o)은 두 단계 변환을 수행한다. 첫 번째는 연산 임베딩 EMB(o)와 가중치 W_o를 통해 시그모이드 게이트 m을 생성하고, 이를 입력 정보 x_in에 원소곱한 뒤, 두 번째 변환 W_x 로 최종 출력 x_out을 만든다(식 2). 이렇게 하면 연산 자체가 정보 흐름을 조절하는 ‘소프트 게이트’ 역할을 하게 된다. 여러 입력이 합쳐지는 노드에서는 단순 합산으로 정보를 집계하고, 최종 출력 노드의 임베딩을 셀 전체의 표현으로 사용한다.
핵심 장점은 다음과 같다. 첫째, 연산을 실제 데이터 처리와 동일한 형태로 모델링함으로써 구조의 의미론적 정보를 풍부히 보존한다. 둘째, 정보 흐름을 토폴로지 순서대로 전파하기 때문에 동형 구조는 동일한 임베딩을 얻게 되어, 그래프 이소모피즘 문제를 자연스럽게 해결한다. 셋째, OON(노드 연산)과 OOE(엣지 연산) 두 검색 공간을 동일한 파이프라인으로 처리할 수 있어, 기존 방법이 필요로 했던 별도 설계가 불필요하다.
실험에서는 NAS‑Bench‑101, NAS‑Bench‑201, ENAS 등 다양한 벤치마크에서 GATES 기반 예측기의 Kendall‑τ와 Pearson‑R이 기존 GCN·LSTM·MLP 대비 크게 향상됨을 보였다. 특히 샘플 효율성 측면에서, 동일한 평가 횟수(예: 500 arch)로도 GATES는 상위 10% 아키텍처를 높은 확률로 찾아냈으며, 전체 NAS 파이프라인에서는 전체 탐색 비용을 30‑40 % 정도 절감했다. 또한, 가중치 W_o, W_x 와 연산 임베딩은 학습 과정에서 자동으로 최적화되며, 별도의 파라미터 공유나 메타‑학습 없이도 강건한 성능을 유지한다.
한계점으로는 현재 GATES가 셀 수준의 인코딩에 초점을 맞추고 있어, 전체 네트워크(다중 셀, 스케일링)까지 확장할 때 추가 설계가 필요할 수 있다. 또한, 연산 변환을 선형 W_x와 시그모이드 m에만 의존하기 때문에, 복잡한 비선형 연산(예: attention, dynamic routing)에는 확장성이 제한될 가능성이 있다. 향후 연구에서는 이러한 비선형 변환을 포함한 확장형 GATES와, 메타‑학습 기반의 가중치 초기화 전략을 탐색할 여지가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기