클라우드 딥러닝을 위한 효율적 FPGA 가상화
초록
본 논문은 단일 FPGA를 공유하는 클라우드 환경에서 딥러닝 추론을 위한 가상화 프레임워크를 제안한다. 공간 분할 다중화(SDM) 기반의 다코어 하드웨어 자원 풀과 2단계 정적‑동적 컴파일 방식을 도입해 물리적·성능 격리를 제공하고, 런타임 재구성 오버헤드를 1 ms 수준으로 낮춘다. 실험 결과, 기존 정적 설계 대비 1.07‑3.12배의 처리량 향상을 달성한다.
상세 분석
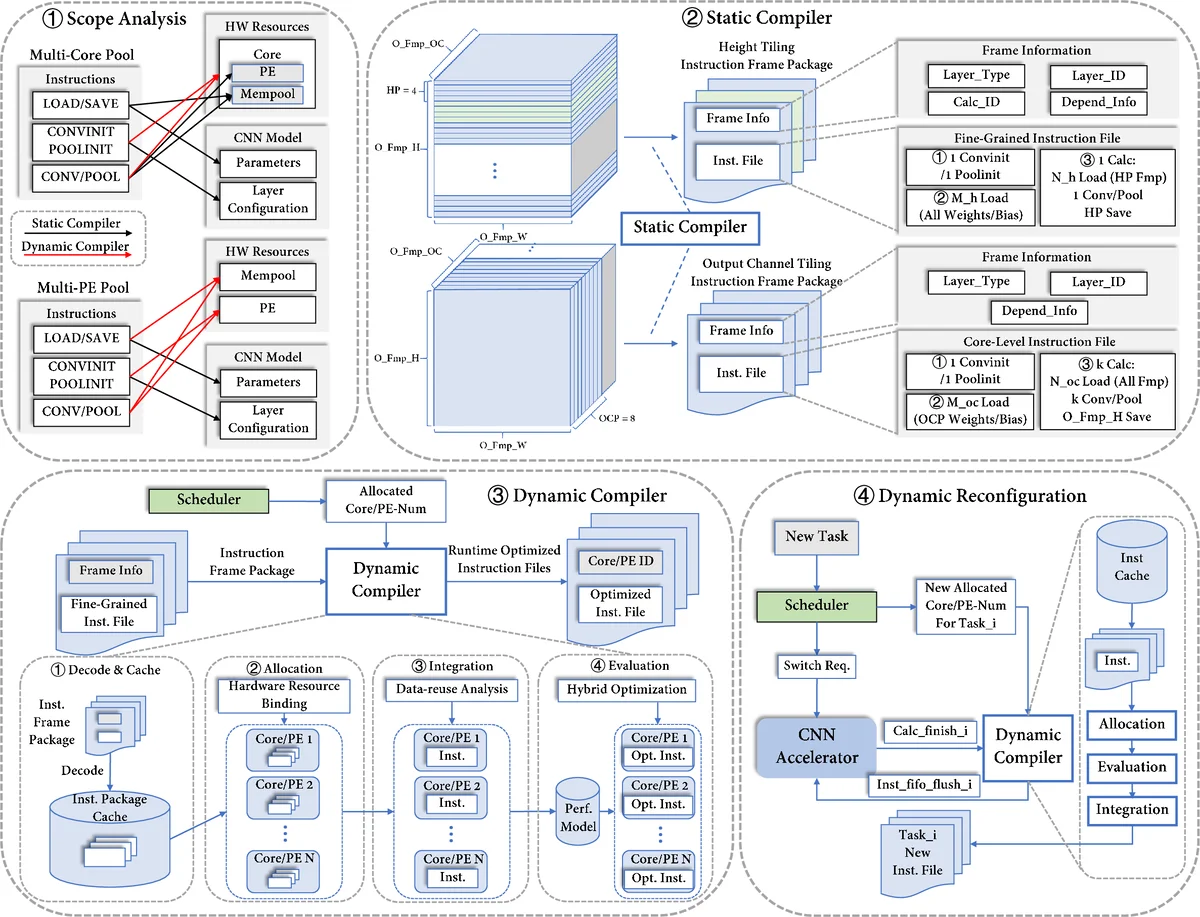
이 논문은 현재 클라우드에서 FPGA 기반 DNN 가속기가 주로 시간 분할 다중화(TDM) 방식으로 운영되며, 재컴파일에 수십 초가 소요되는 문제점을 지적한다. 이러한 구조는 물리적 자원 격리가 어려워 보안 위험과 성능 간섭을 초래한다. 저자들은 이를 해결하기 위해 두 가지 핵심 기술을 제시한다. 첫 번째는 공간 분할 다중화(SDM)를 기반으로 한 다코어 하드웨어 자원 풀(HRP)이다. 하나의 대형 코어를 여러 개의 소형 코어로 분할하고, 각 사용자에게 독립적인 코어 집합을 할당함으로써 물리적 격리와 성능 격리를 동시에 달성한다. 코어 간 통신·동기화 오버헤드를 최소화하기 위해 워크로드 균형을 고려한 타일링 기반 인스트럭션 패키지를 설계했으며, 이는 작은 코어가 큰 코어와 동일한 효율을 유지하도록 돕는다. 두 번째는 두 단계 정적‑동적 컴파일 흐름이다. 오프라인 단계에서 모든 가능한 하드웨어 구성에 대해 미리 세분화된 인스트럭션 패키지를 생성하고, 온라인 단계에서는 런타임에 할당된 자원에 맞춰 패키지를 재조합·재배치한다. 이 과정은 경량 런타임 정보만 재컴파일하므로 재구성 지연을 약 1 ms로 축소한다. 실험에서는 공개 클라우드 시나리오에서 다코어 SDM 설계가 성능 편차를 1 % 이하로 유지하면서, 기존 단일코어 TDM 대비 1.07‑1.69배, 다코어 정적 설계 대비 1.88‑3.12배의 처리량 향상을 보였다. 또한, 재구성 오버헤드가 100 s 수준이던 기존 방식과 달리 1 ms 수준으로 감소해 레이턴시 민감한 DNN 추론 서비스에 적합함을 입증한다. 논문은 또한 보안 측면에서 코어 충돌·크래시 격리를 구현해 악성 사용자가 다른 사용자의 작업을 방해하지 못하도록 설계하였다. 전체적으로, 이 연구는 FPGA 가상화를 위한 하드웨어·소프트웨어 공동 설계 방법론을 제시하며, 클라우드 환경에서 다중 사용자·동적 워크로드를 효율적으로 지원할 수 있는 실용적인 로드맵을 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기