오디오 기반 음악 분류와 태깅을 위한 제로샷 학습
초록
본 논문은 음악 트랙에 대한 장르·무드·악기 등 다중 라벨을 예측하는 기존의 고정 라벨 방식의 한계를 제로샷 학습으로 극복한다. 인간이 직접 라벨에 부여한 속성(악기 벡터)과 일반 단어 임베딩(GloVe) 두 종류의 부가 정보를 활용해 음향 특성과 의미 공간을 연결한다. 또한 다중 라벨 데이터에 적합한 인스턴스·라벨 분할 방식을 제안하고, 제안 모델을 FMA·MSD 등 공개 데이터셋에 적용해 성능을 검증한다.
상세 분석
이 논문은 음악 정보 검색(MIR) 분야에서 “보지 못한 라벨”을 예측할 수 있는 제로샷 학습(zero‑shot learning, ZSL)의 적용 가능성을 체계적으로 탐구한다. 기존의 음악 분류·태깅 모델은 고정된 라벨 집합에 대해 지도학습을 수행하므로, 새로운 장르나 사용자가 임의로 만든 검색어를 처리하지 못한다는 근본적인 제약이 있다. 이를 해결하기 위해 저자는 두 가지 부가 정보(side information) 전략을 도입한다. 첫 번째는 Free Music Archive(FMA)와 OpenMIC‑2018에서 제공되는 인간 라벨 기반 속성, 즉 20개의 악기 존재 여부를 0/1 혹은 확률값으로 표현한 40차원(긍정·부정) 벡터를 장르 라벨에 매핑한다. 이는 음악 장르와 악기 간의 의미적 연관성을 명시적으로 모델링할 수 있어 해석 가능성이 높다. 두 번째는 Million Song Dataset(MSD)와 Last.fm 태그를 이용해 Word2Vec/GloVe와 같은 대규모 단어 임베딩을 라벨에 할당하는 방법이다. 일반 단어 임베딩은 라벨 어휘가 풍부하고 새로운 라벨에 대한 사전 지식이 자동으로 제공되지만, 음악 도메인 특수성(예: 특정 장르에만 쓰이는 용어)을 반영하지 못할 위험이 있다.
다중 라벨 특성을 고려한 데이터 분할 설계는 논문의 핵심 기여 중 하나이다. 기존 ZSL 연구는 주로 단일 라벨 문제에 초점을 맞추어 라벨을 ‘seen’·‘unseen’으로 나눈 뒤, 인스턴스를 자동으로 구분했다. 그러나 음악 데이터는 하나의 트랙에 여러 라벨이 동시에 존재하므로, 라벨‑우선(split‑first)과 인스턴스‑우선(split‑first) 방식 모두 실용적 한계가 있다. 저자는 라벨을 먼저 ‘seen(X)’과 ‘unseen(Y)’으로 구분하고, 이후 인스턴스를 세 그룹(A, B, C)으로 나눈다. A는 오직 seen 라벨만, B는 seen·unseen 라벨을 모두, C는 오직 unseen 라벨만 포함한다. 이를 기반으로 학습 셋(A‑X, B‑X, (A+B)‑X)과 테스트 셋(주석 과제: B‑Y, C‑Y, (B+C)‑Y 등; 검색 과제: (B+C)‑Y, (A+B+C)‑Y 등)을 다양하게 조합함으로써 ‘전통적 ZSL’, ‘라벨‑우선 ZSL’, ‘일반화 ZSL’ 등 여러 평가 시나리오를 동시에 검증한다. 이러한 설계는 실제 서비스 환경에서 “새로운 라벨을 추가했을 때 기존 데이터와 어떻게 혼합될지”를 모사하는 데 유용하다.
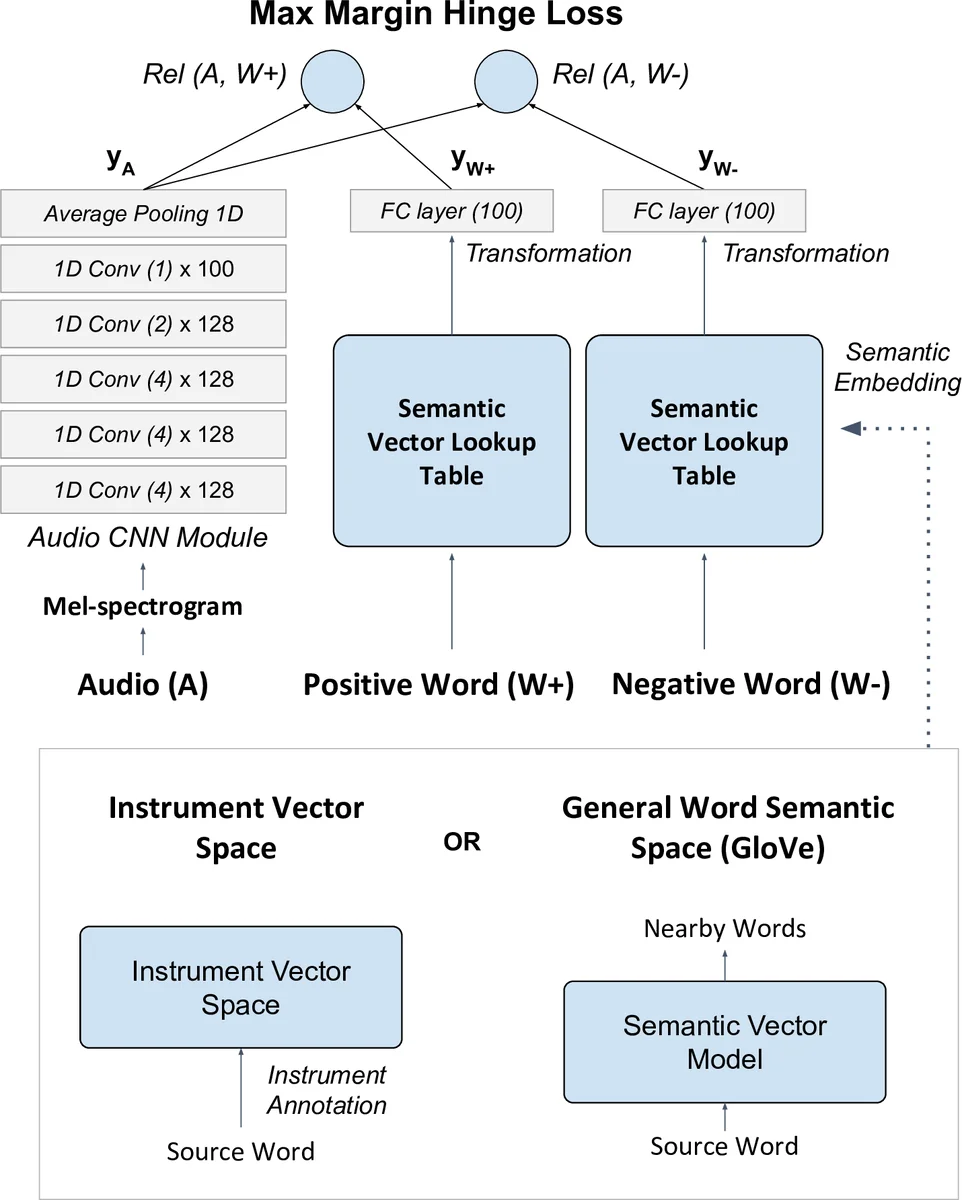
모델 아키텍처는 비선형 호환성(Non‑linear Compatibility) 기반의 딥 임베딩 구조를 채택한다. 입력은 3초 길이의 멜‑스펙트로그램이며, 1‑D 컨볼루션 레이어 4개와 풀링·ReLU를 거쳐 고정 차원의 오디오 임베딩을 만든다. 라벨 임베딩은 사전 정의된 속성 벡터(악기) 혹은 일반 단어 임베딩을 100차원 Fully‑Connected 레이어를 통해 변환한다. 두 임베딩 사이의 코사인 유사도를 ‘관련도(Rel)’로 정의하고, 양성 라벨(W⁺)과 음성 라벨(W⁻)을 무작위 샘플링해 마진 힌지 손실(max‑margin hinge loss)로 학습한다. 이 방식은 기존 이미지‑텍스트 ZSL에서 사용되던 구조를 오디오 도메인에 그대로 적용하면서, 라벨 간 의미 관계를 직접 학습하도록 설계되었다. 또한 동일 구조를 다중 라벨 분류용으로 변형해, 오디오 모듈만 사용하고 시그모이드·바이너리 교차 엔트로피로 학습하는 ‘분류 모델’도 구현해 비교 실험을 수행한다.
실험은 두 데이터셋(FMA·MSD)과 두 부가 정보(악기 속성·일반 단어 임베딩) 조합으로 4가지 시나리오를 만든다. FMA‑OpenMIC 조합에서는 157개의 장르 라벨 중 125개를 seen, 32개를 unseen으로 나누고, 악기 20종을 40차원 벡터로 변환해 라벨 임베딩으로 사용한다. MSD‑Last.fm 조합에서는 1,126개의 태그를 900/226으로 분할하고, GloVe 임베딩을 라벨 벡터로 활용한다. 평가 지표는 주석 과제에서 mAP, P@k, 그리고 검색 과제에서 유사도 기반 정밀도 등을 사용한다. 결과는 전반적으로 제로샷 설정에서도 의미 있는 성능을 보이며, 특히 악기 속성 기반 모델이 일반 단어 임베딩보다 높은 P@k를 기록한다. 이는 도메인 특화된 속성 정보가 라벨 간 의미 전이를 더 효과적으로 촉진한다는 점을 시사한다. 또한 라벨‑우선(split‑first)과 일반화 ZSL 평가에서 모델이 unseen 라벨뿐 아니라 seen+unseen 라벨 전체에 대해 균형 잡힌 예측을 수행함을 확인한다.
한계점으로는 (1) 악기 속성 벡터가 제한된 20종에 국한돼 있어 장르 다양성을 충분히 포괄하지 못한다는 점, (2) 일반 단어 임베딩이 음악 특수 용어(예: “chillhop”)를 제대로 반영하지 못해 성능 격차가 발생한다는 점, (3) 현재 모델은 단일 트랙을 3초 샘플링해 학습하므로 장시간 구조적 정보를 놓칠 가능성이 있다. 향후 연구에서는 더 풍부한 음악‑전문 속성(리듬, 화성 등)과 멀티‑스케일 오디오 컨텍스트를 결합하고, 트랜스포머 기반의 교차‑모달 어텐션을 도입해 의미 공간과 음향 공간의 정교한 정렬을 시도할 수 있다.
요약하면, 이 논문은 (i) 음악 도메인에 맞는 부가 정보 설계, (ii) 다중 라벨 ZSL을 위한 체계적인 데이터 분할·평가 프레임워크, (iii) 비선형 호환성을 활용한 딥 임베딩 모델을 제시함으로써, 기존의 고정 라벨 기반 MIR 시스템이 갖는 확장성 문제를 효과적으로 해결하고, 새로운 라벨을 동적으로 추가·검색할 수 있는 기반을 마련하였다.
댓글 및 학술 토론
Loading comments...
의견 남기기