대규모 로봇군을 위한 적응형 온라인 분산 최적 제어
초록
본 논문은 최적 질량 운송 이론과 Wasserstein‑GMM 공간을 기반으로, 시간에 따라 변하는 장애물 지도와 로봇 집단의 확률밀도함수를 이용한 적응형 온라인 분산 최적 제어(ADOC) 프레임워크를 제안한다. 값 함수와 Q‑함수를 정의하고, critic‑only Q‑learning을 통해 제어 연산자를 직접 학습하지 않으며, 선형계획법(LP)으로 실시간 최적 PDF 전이를 계산한다. 시뮬레이션 결과는 기존 DOC·MARL·MFC 방식보다 평균 이동거리와 에너지 비용에서 우수함을 보여준다.
상세 분석
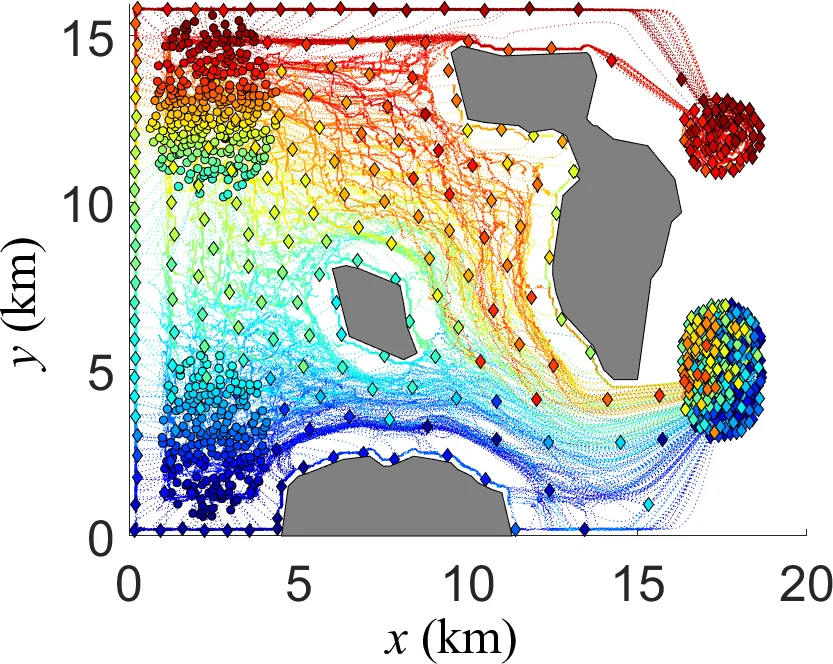
이 연구는 매우 큰 규모(VLSR)의 로봇 시스템을 대상으로, 전통적인 최적 제어와 다중 에이전트 강화학습(MARL)의 확장성 문제를 동시에 해결하려는 시도이다. 핵심 아이디어는 로봇들의 미시적 상태를 개별적으로 다루는 대신, 전체 로봇군을 확률밀도함수(PDF)로 모델링하고, 이를 가우시안 혼합 모델(GMM) 형태로 근사한다는 점이다. 이렇게 하면 상태공간이 연속적이면서도 고차원인 문제를 Wasserstein 거리 기반의 최적 질량 운송(OMT) 이론에 귀속시켜, PDF 간의 최적 전이 경로를 정의할 수 있다.
시간에 따라 변하는 장애물 정보는 Hilbert occupancy map을 이용해 연속적인 확률 지도 h(x,t)를 학습하고, 이를 이진 장애물 지도 m(x,t)로 변환한다. 이 지도는 매 시간 단계마다 로봇들의 센서 관측을 통해 업데이트되며, ADOC는 이 변동성을 값 함수 V_k와 Q‑함수에 직접 반영한다. 특히, Q‑함수는 L(·)와 V_k+1을 합한 형태로 Bellman 방정식을 만족하도록 설계되었으며, 최적 제어 PDF ℙ*{k+1}=arg min{ℙ} Q*_k(ℙ_k,m_k,ℙ) 로부터 얻어진다.
제어 연산자를 직접 근사하지 않는 critic‑only Q‑learning(CoQL) 방식을 채택함으로써, 온라인 환경에서 연산량을 크게 줄였다. 실제 구현에서는 Wasserstein‑GMM 공간의 하위 공간에서 선형계획법(LP)을 풀어 ℙ_{k+1}을 계산한다. 이는 기존 DOC 방식이 연속 공간에서 비선형 프로그래밍(NLP)을 수행해야 하는 복잡성을 회피한다.
수렴성 분석에서는 Theorem 1을 통해 시간 k에서 얻은 최적 값 함수 V*_k가 이전 단계들의 값 함수보다 하한임을 증명, 즉 학습이 진행될수록 비용이 감소한다는 보장을 제공한다. 실험에서는 장애물 배치가 점진적으로 밝혀지는 시나리오에서, ADOC가 평균 경로 길이와 에너지 소비 측면에서 기존 DOC, MARL 기반 MFC, 그리고 전통적인 MDP 기반 방법보다 현저히 우수함을 확인했다.
이 논문의 주요 공헌은 (1) 시간‑가변 장애물 정보를 Lagrangian에 통합, (2) 새로운 값 함수 정의, (3) Wasserstein‑GMM 기반 OMT 정리 적용, (4) LP 기반 온라인 구현, (5) 광범위한 시뮬레이션을 통한 성능 검증이다. 따라서 대규모 로봇군이 불확실하고 동적으로 변하는 환경에서 실시간으로 재계획하고 적응할 수 있는 실용적인 프레임워크를 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기