연속 제어를 위한 신경망 구조 진화와 강화학습 통합
본 논문은 연속 제어 환경에서 손수 설계된 네트워크 대신, 신경망 구조를 온라인으로 진화시켜 최적화하는 방법을 제안한다. Neuroevolution과 오프‑폴리시 Actor‑Critic (TD3) 학습을 결합하고, 네트워크 증식 후 부모‑자식 간 지식 전이를 통한 안정적인 토폴로지 변이 연산자를 도입한다. 실험 결과, 제안 알고리즘은 기존 TD3 대비 동일하거나 더 높은 성능을 보이며, 작은 구조에서도 효율적인 학습이 가능함을 확인하였다.
저자: J"org K.H. Franke, Gregor K"ohler, Noor Awad
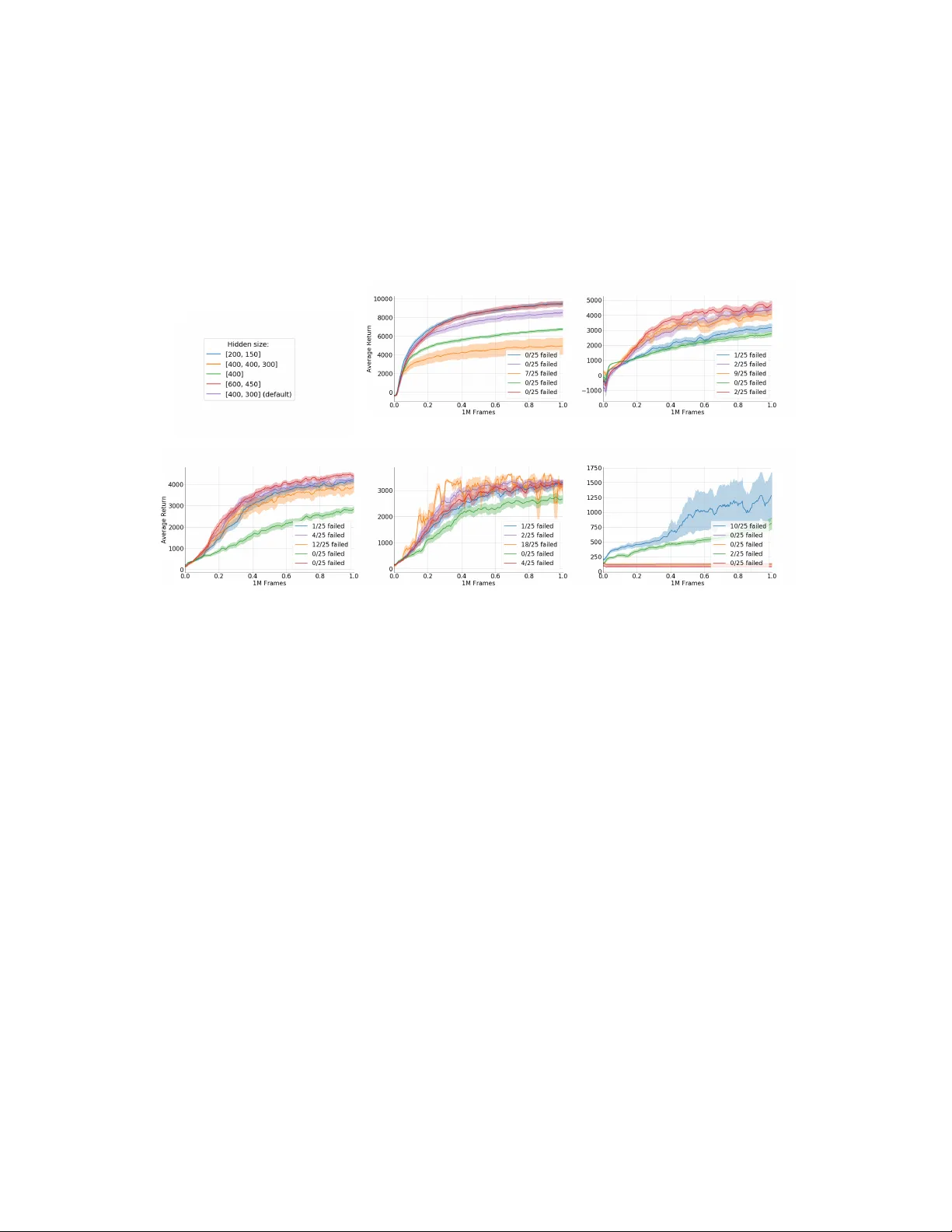
본 논문은 심층 강화학습(Deep Reinforcement Learning, DRL)에서 네트워크 아키텍처가 수작업으로 설계되는 현상을 극복하고, 연속 제어 환경에 적합한 신경망 구조를 온라인으로 자동 탐색·진화시키는 새로운 프레임워크를 제시한다. 저자들은 ‘Actor‑Critic Neuroevolution (ACN)’이라는 알고리즘을 설계했으며, 이는 전통적인 유전 알고리즘(GA)과 오프‑폴리시 Actor‑Critic 학습(TD3)을 결합한다.
1. **배경 및 동기**
- 기존 DRL 성공 사례(Atari, 로봇 제어 등)는 대부분 사전에 설계된 네트워크 구조에 의존한다.
- 신경망 구조 자체가 성능에 큰 영향을 미치지만, 이를 찾기 위한 메타‑학습이나 베이지안 최적화는 샘플 효율성이 낮다.
- 따라서, 환경 상호작용을 최소화하면서도 구조를 동적으로 조정할 수 있는 방법이 필요하다.
2. **Neuroevolution 기반 설계**
- 개체는 배우(actor)와 비평가(critic) 두 네트워크의 토폴로지(ψ)와 파라미터(θ)를 포함한다.
- 초기 개체는 최소 규모(단일 은닉층 64노드)로 시작하고, 전역 리플레이 버퍼에 저장된 경험을 이용해 초기 적합도(fitness)를 평가한다.
- 매 세대마다 토너먼트 선택을 통해 부모를 선정하고, 두 가지 변이 연산 중 하나를 적용한다.
3. **Distilled Topology Mutation**
- **구조 성장 단계**: 확률 p_L에 따라 새로운 은닉층을 추가하거나 기존 층에 뉴런을 삽입한다.
- **지식 증류 단계**: 부모 네트워크가 생성한 (상태, 행동/값) 쌍을 전역 버퍼에서 무작위 추출해 Dₚ를 만든 뒤, 자식 네트워크를 지도학습(MSE)으로 미세조정한다. 이를 통해 급격한 파라미터 초기화에 따른 정책·가치 붕괴를 방지한다.
4. **Gradient‑based Mutation (SM‑G‑SUM)**
- 파라미터에 가우시안 노이즈를 추가하되, 각 파라미터의 출력 민감도(gradient)를 고려해 스케일을 조정한다.
- 이는 ‘Safe Mutation’ 기법을 차용한 것으로, 변이 후에도 정책이 급격히 악화되는 위험을 감소시킨다.
5. **오프‑폴리시 학습 통합**
- 변이 후 각 개체는 TD3 학습 단계에 들어가며, 전역 리플레이 버퍼를 공유한다.
- 학습 과정에서 옵티마이저와 타깃 네트워크를 새롭게 초기화·재구성해, 변화된 토폴로지에 맞는 학습 환경을 제공한다.
- 이렇게 하면 진화 단계에서 생성된 다양한 정책이 동일한 데이터 풀을 활용해 빠르게 수렴한다.
6. **실험 설정**
- MuJoCo의 5가지 연속 제어 벤치마크(HalfCheetah, Hopper, Walker2d, Ant, Humanoid)를 사용했다.
- 비교 대상은 동일한 하이퍼파라미터 설정을 유지한 TD3 고정‑구조(두 은닉층 400‑300)이다.
- ACN 변형은 (a) 토폴로지를 진화하는 버전, (b) 고정 토폴로지에서 파라미터만 변이하는 버전으로 나뉘었다.
7. **결과 및 분석**
- 대부분의 환경에서 ACN은 TD3와 동등하거나 더 높은 평균 보상을 기록했다. 특히 Humanoid에서는 큰 성능 향상이 관찰되었으며, 이는 복잡한 토폴로지 탐색이 효과적이었음을 의미한다.
- HalfCheetah와 Hopper에서는 ACN이 더 작은 네트워크(층 수·노드 수 감소)로도 동일 수준의 성능을 달성, 과제별 최적 구조가 다를 수 있음을 보여준다.
- 학습 효율 측면에서, ACN은 전체 환경 스텝이 약 5~10% 정도만 추가되었으며, 이는 전역 버퍼와 병렬 학습 덕분에 진화 비용이 크게 억제된 결과이다.
- 추가 실험(Appendix D)에서는 TD3에 주기적인 옵티마이저 재초기화·타깃 네트워크 재생성을 적용했을 때도 성능이 크게 저하되지 않으며, 경우에 따라 오히려 향상되는 것을 확인했다.
8. **한계 및 향후 연구**
- 현재 MLP에 국한된 설계이므로, CNN·RNN·Transformer 등 복합 구조에 대한 적용 가능성은 미확인이다.
- 변이 연산의 하이퍼파라미터(p_L, p_G 등)가 환경에 따라 민감하게 작용할 수 있어 자동 튜닝 메커니즘이 필요하다.
- 전역 리플레이 버퍼가 초기 토폴로지에 편향될 경우, 이후 진화 단계에서 탐색 다양성이 감소할 위험이 있다. 이를 완화하기 위한 버퍼 관리 전략이 요구된다.
- 마지막으로, 진화와 학습을 동시에 수행함으로써 발생하는 ‘신경망 구조와 파라미터의 공동 최적화’ 메커니즘을 이론적으로 분석하는 연구가 필요하다.
9. **결론**
- ACN은 Neuroevolution과 오프‑폴리시 Actor‑Critic 학습을 효과적으로 결합해, 연속 제어 환경에서 자동으로 최적 네트워크 구조를 찾아낸다.
- 제안된 ‘Distilled Topology Mutation’은 구조 성장 후에도 정책·가치가 안정적으로 유지되도록 보장한다.
- 실험 결과는 기존 고정‑구조 DRL 알고리즘 대비 동일하거나 더 나은 성능을 달성하면서, 추가적인 환경 상호작용 비용은 최소화됨을 입증한다.
- 향후 연구에서는 보다 복합적인 네트워크 블록, 하이퍼파라미터 자동 조정, 그리고 이론적 수렴 분석을 통해 프레임워크를 확장할 계획이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기