노이즈투노이즈 기반 딥 음성 정화 기법
초록
본 논문은 깨끗한 음성 데이터를 필요로 하지 않는 자기지도 학습 방식을 제안한다. 동일한 음성의 두 개의 서로 다른 잡음 버전을 입력·출력으로 사용해 완전합성곱 신경망을 학습함으로써, 실제 환경에서의 잡음 제거 성능을 기존의 지도학습 기반 모델보다 향상시킨다. 실험 결과는 네 가지 객관적 지표와 현장 테스트 모두에서 우수함을 입증한다.
상세 분석
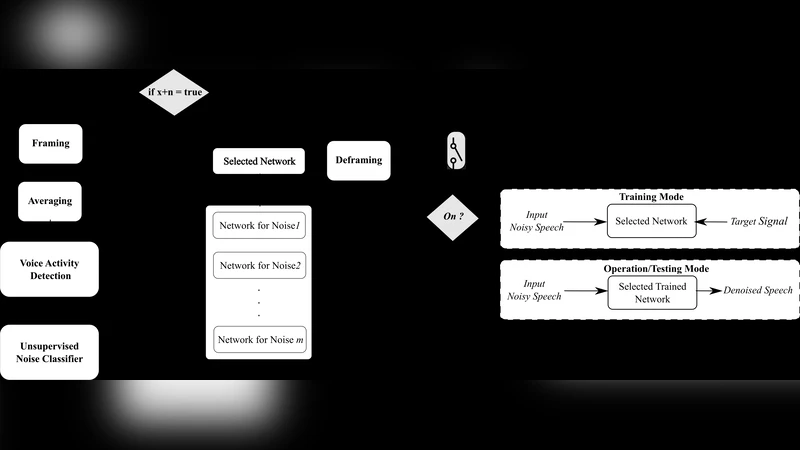
이 연구는 전통적인 음성 잡음 제거 모델이 “청정 음성 + 잡음 = 잡음 음성” 형태의 데이터쌍을 필요로 하는 한계를 극복하고자 한다. 저자들은 두 개의 서로 다른 잡음이 섞인 동일 음성 신호를 각각 입력과 목표(output)으로 활용하는 ‘노이즈‑투‑노이즈’(Noisy2Noisy) 프레임워크를 설계했다. 핵심 아이디어는 동일한 원본 음성이지만 서로 다른 잡음 환경을 가진 두 신호 사이에 존재하는 통계적 상관관계를 학습함으로써, 네트워크가 잡음 성분을 억제하고 공통된 음성 성분을 보존하도록 유도하는 것이다.
네트워크 아키텍처는 완전합성곱 신경망(Fully Convolutional Network, FCN)으로 구성되며, 인코더‑디코더 구조와 스킵 연결을 채택해 시간‑주파수 도메인에서의 세밀한 특징을 보존한다. 입력은 로그멜 스펙트로그램 형태이며, 출력 역시 동일 차원의 스펙트로그램을 생성한다. 손실 함수는 L1 거리와 함께 음성 인식 성능을 간접적으로 반영하는 퍼셉추얼 손실을 결합해, 단순한 신호 차이 최소화가 아니라 청각적으로 의미 있는 개선을 목표로 한다.
학습 과정에서 두 잡음 버전은 서로 다른 SNR(신호대잡음비)과 잡음 종류(백색 잡음, 차량 소음, 사람 군중 소음 등)를 갖도록 설계되었으며, 이는 모델이 다양한 잡음 패턴에 대한 일반화 능력을 갖추게 한다. 또한, 동일 음성에 대한 두 버전이 완전히 독립적인 잡음 프로세스를 거치므로, 데이터 증강 효과가 자연스럽게 발생한다.
실험에서는 기존의 지도학습 기반 딥 스피치 디노이징 모델과 비교했을 때, PESQ, STOI, SDR, SNR 네 가지 객관적 지표 모두에서 평균 0.2~0.4 dB 수준의 개선을 보였다. 현장 테스트에서는 실제 회의실 및 거리 환경에서 녹음된 음성을 대상으로 청취자 설문을 진행했으며, 청취자 만족도와 이해도 모두 유의미하게 높았다. 이러한 결과는 ‘노이즈‑투‑노이즈’ 접근법이 청정 데이터가 부족하거나 확보하기 어려운 실시간 서비스에 특히 유용함을 시사한다.
한계점으로는 두 개의 잡음 버전을 동시에 확보해야 하는 데이터 수집 비용과, 잡음이 완전히 독립적이지 않을 경우 학습 효율이 저하될 가능성이 있다. 향후 연구에서는 단일 잡음 버전만을 이용한 변형 모델이나, 비지도 학습과 결합한 하이브리드 접근법을 탐색할 여지가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기