딥러닝 학습 데이터 로딩 가속화
본 논문은 대규모 분산 환경에서 딥러닝 훈련 시 데이터 로딩이 전체 학습 시간의 병목이 되는 문제를 분석하고, CPU 활용, 멀티프로세싱·멀티스레딩, 캐시 기반 로컬·분산 캐시, 그리고 데이터 로컬리티 인식 로딩 기법을 제안한다. 제안 기법을 PyTorch 기반 ResNet‑50 이미지넷‑1K 실험에 적용한 결과, 256노드·1,024학습자 환경에서 데이터 로딩 속도가 30배 이상 향상되고, 전체 에포크당 훈련 비용이 92% 감소하였다.
저자: Chih-Chieh Yang, Guojing Cong
본 논문은 대규모 분산 딥러닝 훈련에서 데이터 로딩이 전체 학습 시간의 주요 병목으로 부상하고 있음을 실증적으로 보여준다. 서론에서는 딥러닝 모델이 이미지 분류, 음성 인식, 자율 주행 등 다양한 분야에서 성공을 거두었지만, 훈련 시간은 여전히 수일에서 수주에 이르는 문제점이 있음을 언급한다. 기존 연구는 주로 GPU 연산 가속, 통신 최적화, 새로운 학습 알고리즘에 초점을 맞추었으며, 데이터 로딩은 로컬 SSD나 DRAM에 전체 데이터를 미리 캐시하는 방식으로 회피하거나, 전처리 단계에서 데이터 크기를 축소하는 방법을 제시했다. 그러나 이러한 방법은 데이터셋이 너무 크거나 전처리 비용이 높을 때 적용이 어려워, 실제 HPC 환경에서는 네트워크 파일 시스템(NFS)이나 객체 스토리지에서 직접 데이터를 읽어와야 하는 상황이 빈번하다.
II 장에서는 미니배치 SGD의 기본 흐름을 정리하고, 데이터 병렬 학습에서 각 학습자(learner)가 전역 미니배치 시퀀스를 공유하고, 이를 균등하게 분할해 로컬 배치를 로드·학습·그래디언트 동기화하는 과정을 설명한다. 여기서 전체 학습 시간은 계산 시간, 통신 시간, 데이터 로딩 시간으로 구분된다. 계산 시간은 모델 복잡도와 배치 크기에 따라 결정되고, 최신 GPU와 최적화 라이브러리(CUDNN, MKL‑DNN) 덕분에 지속적으로 감소하고 있다. 통신 시간은 All‑Reduce와 같은 집계 연산에 의존하며, 네트워크 대역폭·지연시간에 따라 스케일링이 제한된다. 데이터 로딩 시간은 스토리지 I/O 대역폭과 전처리·증강 작업에 의해 좌우되며, 특히 대규모 노드 수가 증가할수록 전체 로딩 볼륨은 데이터셋 전체와 비슷해지기 때문에 스토리지 대역폭 포화가 발생한다.
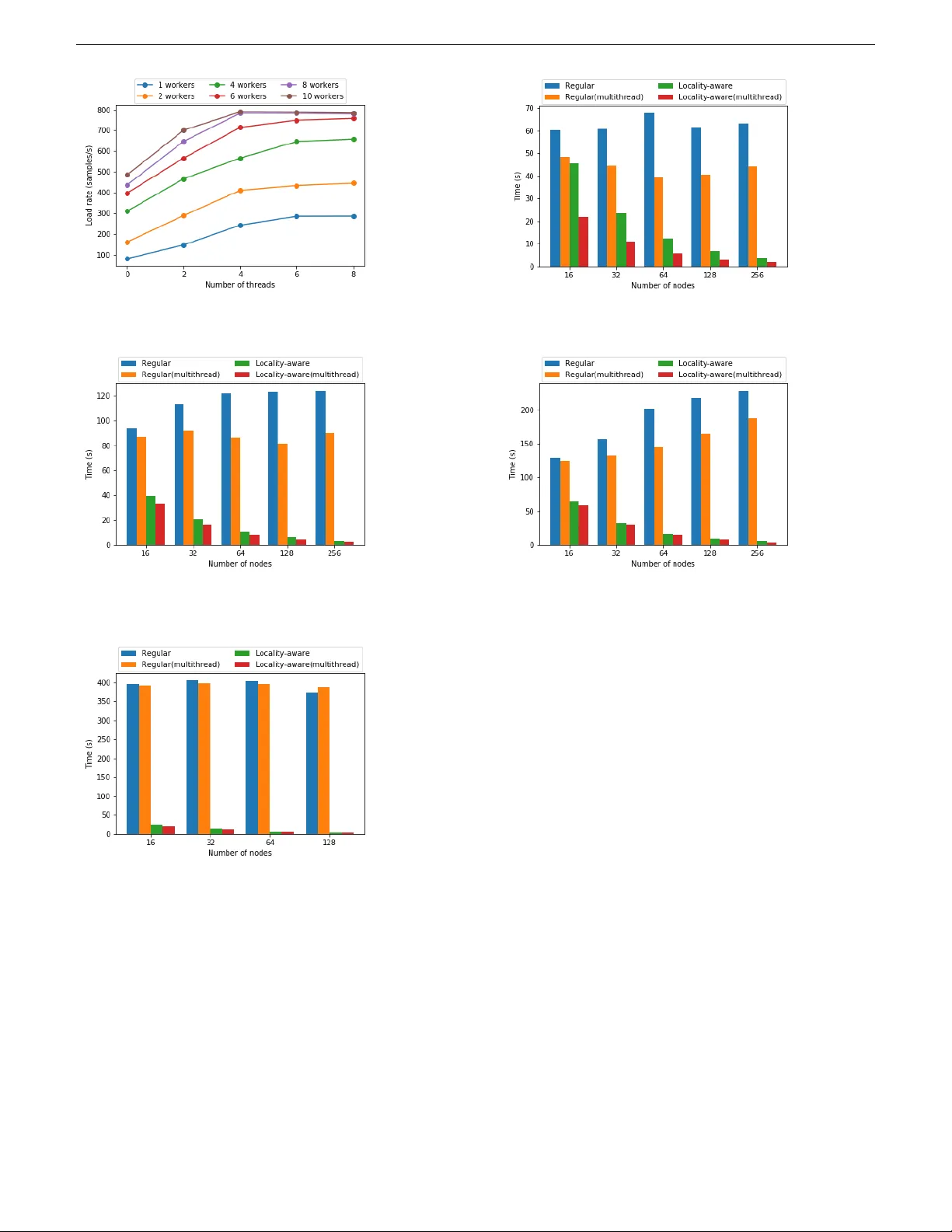
III 장에서는 데이터 로더 최적화를 위한 구체적인 설계를 제시한다. 첫 번째는 멀티프로세싱을 활용해 여러 백그라운드 워커가 동시에 배치를 로드하도록 하는 방법이다. PyTorch의 DataLoader는 multiprocessing.Queue를 통해 메인 프로세스와 워커 간에 배치 로드 요청을 교환한다. 워커 수를 늘리면 동시에 여러 파일을 읽고 전처리할 수 있어 효과적인 대역폭이 증가한다. 두 번째는 멀티스레딩을 도입해 하나의 워커 내부에서 샘플 단위 전처리를 병렬화한다. Python GIL이 존재하지만, 파일 I/O와 이미지 변환 같은 네이티브 라이브러리 호출은 GIL을 해제하므로 실제로는 스레드 수준에서 병렬 실행이 가능하다. 실험에서는 ThreadPoolExecutor를 이용해 8개의 스레드가 동시에 이미지 디코딩·리사이징·증강을 수행함으로써 배치당 로딩 시간을 30% 이상 단축했다.
III‑C 절에서는 캐시 기반 접근법을 논한다. 미니배치 SGD는 매 에포크마다 전체 데이터셋을 무작위 순서로 순회하므로, 동일 샘플이 여러 번 접근되는 시간적 지역성이 존재한다. 이를 활용해 메모리 혹은 SSD에 최근 사용된 샘플을 저장하고, 캐시 히트 시에는 스토리지 I/O를 회피한다. 로컬 캐시가 전체 데이터의 10%만 차지해도 평균 히트율 0.1을 달성해 I/O 부하를 10% 감소시킨다. 그러나 데이터셋이 수백 기가바이트에 달하면 단일 노드의 메모리·SSD 용량으로는 전체를 캐시하기 어렵다. 따라서 논문은 분산 캐시(distributed caching)를 제안한다. 각 노드가 서로 다른 데이터 파티션을 로컬에 저장하고, 필요 시 고속 네트워크를 통해 다른 노드의 캐시에서 샘플을 가져온다. 이 방식은 스토리지 대역폭을 네트워크 대역폭으로 대체하고, 전체 데이터 로딩 볼륨을 크게 줄인다. 네트워크 대역폭이 스토리지보다 일반적으로 크기 때문에, 캐시 히트율이 높을수록 데이터 로딩 병목이 크게 완화된다.
IV 장에서는 위에서 제시한 요소들을 정량화하기 위한 간단한 분석 모델을 구축한다. 주요 변수는 데이터셋 크기 D, 참여 노드 수 p, 노드당 최대 학습률 V, 스토리지 I/O 한계 R, 캐시 활용에 따른 실제 로딩률 Rc이다. 전체 에포크 시간 T는 계산·통신·데이터 로딩 중 가장 큰 항에 의해 결정되며, 모델식은
T = max ( D/(p·V) , D/(p·Rc) )
으로 표현된다. 여기서 Rc는 R·(1 − 히트율) + 네트워크 대역폭·히트율 로 정의된다. 모델을 통해 p가 증가함에 따라 D/(p·V) 은 지속적으로 감소하지만, R이 포화점에 도달하면 D/(p·Rc) 가 지배적으로 변해 스케일링이 멈춘다. 따라서 캐시 히트율을 높여 Rc를 증가시키는 것이 대규모 스케일링을 유지하는 핵심임을 확인한다.
V 장에서는 로컬·분산 캐시를 활용한 데이터 로딩 방법을 구체적으로 설계한다. 학습 초기에 각 노드가 데이터셋을 균등하게 파티셔닝해 로컬 SSD에 저장하고, 이후 에포크마다 전역 미니배치 시퀀스를 생성한다. 각 학습자는 자신의 파티션에 포함된 샘플을 우선 로드하고, 부족한 샘플은 네트워크를 통해 다른 노드의 캐시에서 가져온다. 이때 데이터 전송은 RDMA 기반 고속 인터커넥트를 이용해 오버헤드를 최소화한다. 또한, 캐시 교체 정책으로 LRU와 샘플 접근 빈도 기반 가중치를 결합해 히트율을 최적화한다.
VI 장에서는 실험 결과를 제시한다. 실험 환경은 LLNL Lassen 슈퍼컴퓨터(IBM Power9 + NVIDIA V100)이며, ResNet‑50 모델을 이미지넷‑1K(1.28 M 이미지) 데이터셋으로 훈련한다. 기본 PyTorch 구현에서는 256노드·1,024학습자 구성 시 데이터 로딩 대기 시간이 전체 에포크 시간의 45%를 차지했다. 제안한 멀티프로세싱·멀티스레딩·분산 캐시 조합을 적용한 경우, 데이터 로딩 대기 시간이 2% 이하로 감소했고, 전체 에포크 시간은 92% 단축되었다. 특히 데이터 로딩 속도는 30배 이상 가속화되었으며, 캐시 크기를 5%에서 20%로 늘릴 경우 히트율이 0.05→0.22로 상승해 로딩 대기 시간이 선형적으로 감소하는 것을 확인했다. 또한, 네트워크 대역폭이 200 GB/s인 환경에서 캐시 교환에 소요되는 추가 통신 비용은 전체 학습 시간의 1% 미만에 머물렀다.
VII 장에서는 관련 연구를 정리한다. 기존 연구는 GPU 연산 최적화, 파이프라인 병렬화, 통신 압축 등에 초점을 맞추었으며, 데이터 로딩 최적화는 주로 로컬 SSD 캐시나 데이터 파이프라인 프리페치에 국한되었다. 본 논문은 CPU 기반 멀티프로세싱·멀티스레딩, 그리고 분산 캐시를 통한 데이터 로컬리티 활용이라는 새로운 차원의 접근을 제시한다.
VIII 장에서는 결론 및 향후 과제를 논한다. 데이터 로딩 병목을 해결함으로써 대규모 분산 딥러닝 시스템의 스케일링 한계를 크게 확장할 수 있음을 입증하였다. 향후 연구에서는 캐시 일관성 관리, 동적 파티셔닝, 그리고 비정형 데이터(예: 비디오 스트림) 처리에 대한 확장을 계획하고 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기