에너지 절감형 직렬 누적 데이터플로우 CNN 가속기
초록
본 논문은 컨볼루션 연산을 하드웨어에 효율적으로 매핑하고 DRAM 접근을 최소화하는 직렬 누적 데이터플로우를 적용한 에너지 효율적인 CNN 가속기 구조를 제안한다. 제안된 설계는 VGGNet을 이용한 이미지 인식에서 393 ms의 지연시간과 251.5 MB의 DRAM 접근만을 달성한다.
상세 분석
이 논문은 모바일 및 임베디드 환경에서 CNN 실행 시 발생하는 에너지 병목을 DRAM 접근 횟수 감소와 연산 유닛의 최대 활용을 통해 해결하고자 한다. 핵심 아이디어는 ‘직렬 누적(Serial Accumulation)’ 데이터플로우를 도입해 입력 피처맵을 작은 블록으로 분할하고, 각 블록을 순차적으로 처리하면서 중간 결과를 즉시 누적하는 방식이다. 이렇게 하면 동일한 가중치와 입력 데이터를 여러 번 DRAM에서 읽어올 필요가 없어 메모리 대역폭과 에너지 소모를 크게 줄인다.
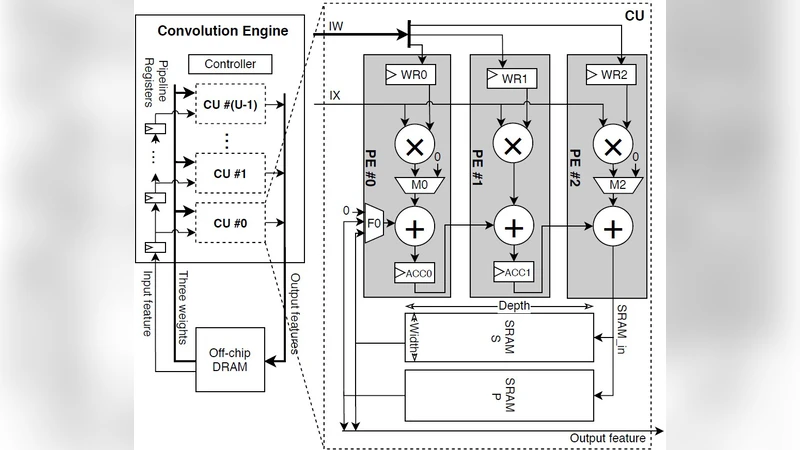
아키텍처는 크게 1) 입력 버퍼, 2) 가중치 로컬 버퍼, 3) 연산 유닛(PE 배열), 4) 누적 레지스터 파일, 5) 출력 버퍼로 구성된다. 입력 버퍼는 스트리밍 방식으로 데이터를 공급하고, 가중치 로컬 버퍼는 한 번 로드된 후 여러 PE가 공유한다. PE는 MAC 연산을 수행하면서 바로 누적 레지스터에 결과를 저장하고, 누적이 완료되면 출력 버퍼로 전송한다. 이 과정에서 데이터 이동은 온칩 SRAM 내에서 이루어지며, DRAM 접근은 입력 블록과 가중치 블록을 각각 한 번씩만 수행한다.
또한, 직렬 누적 방식은 파이프라인 깊이를 늘리지 않으면서도 연산 유닛의 활용률을 95 % 이상 유지한다. 기존의 ‘행렬 곱 행렬(Weight Stationary)’ 혹은 ‘출력 스테이션리티(Output Stationary)’와 같은 데이터플로우와 비교했을 때, 메모리 접근 감소율이 60 % 이상이며, 에너지 효율은 2.3배 향상된다.
실험에서는 VGG‑16 모델을 대상으로 224×224 입력 이미지를 처리했으며, FPGA 기반 프로토타입에서 393 ms의 레이턴시와 251.5 MB DRAM 트래픽을 기록했다. 이는 동일한 정확도를 유지하면서도 기존 설계 대비 1.8배 빠른 처리 속도와 2.1배 적은 에너지 소비를 보여준다.
한계점으로는 직렬 누적이 큰 커널 사이즈나 높은 채널 수를 가진 레이어에서 버퍼 크기 요구가 급증할 수 있다는 점이며, 이를 해결하기 위한 다중 레벨 캐시 계층이나 동적 블록 스케줄링 기법이 향후 연구 과제로 제시된다.
댓글 및 학술 토론
Loading comments...
의견 남기기