학습된 손실 함수로 음성 향상 QualityNet 기반 PESQ 최적화
초록
본 연구는 인간 청각 인지를 반영한 PESQ 점수를 근사하는 차별화 가능한 손실 함수를 학습시켜, 기존 MSE 기반 음성 향상 모델의 한계를 극복하고 PESQ를 0.18점 향상시키면서도 인식률을 유지하는 방법을 제안한다.
상세 분석
이 논문은 음성 향상 분야에서 가장 오래된 문제 중 하나인 손실 함수 선택의 근본적인 재고를 시도한다. 전통적으로 MSE 손실은 신호 파형 간의 평균 제곱 차이를 최소화하는 데 초점을 맞추지만, 인간 청각 시스템이 민감하게 반응하는 왜곡 유형—예를 들어, 왜곡된 스펙트럼 구조나 비선형적인 잡음—을 충분히 반영하지 못한다. 이러한 한계를 보완하기 위해 저자들은 PESQ라는 객관적인 청취 품질 지표를 직접 최적화 목표로 삼고자 했지만, PESQ는 복잡한 비선형 연산과 비미분 가능한 단계(예: 로그 압축, 비선형 매핑)를 포함하고 있어 역전파가 불가능했다.
이에 대한 해결책으로 제시된 것이 “Quality‑Net”이라 불리는 신경망 기반의 PESQ 근사 모델이다. Quality‑Net은 대규모 청취 데이터와 해당 PESQ 점수를 입력으로 하여, 입력된 깨끗한 음성과 잡음이 섞인 음성 쌍을 받아 PESQ를 예측하도록 학습된다. 핵심 설계는 두 단계로 나뉜다. 첫 번째는 전통적인 STFT 기반 스펙트로그램을 추출하고, 이를 2‑D 컨볼루션 레이어와 residual 블록을 통해 고차원 특징으로 변환한다. 두 번째는 이러한 특징을 전역 평균 풀링 후 완전 연결층에 전달해 최종 PESQ 점수를 회귀한다. 손실 함수는 실제 PESQ와 예측값 사이의 L1 차이를 최소화함으로써, 모델이 실제 청취 품질과 높은 상관관계를 유지하도록 만든다.
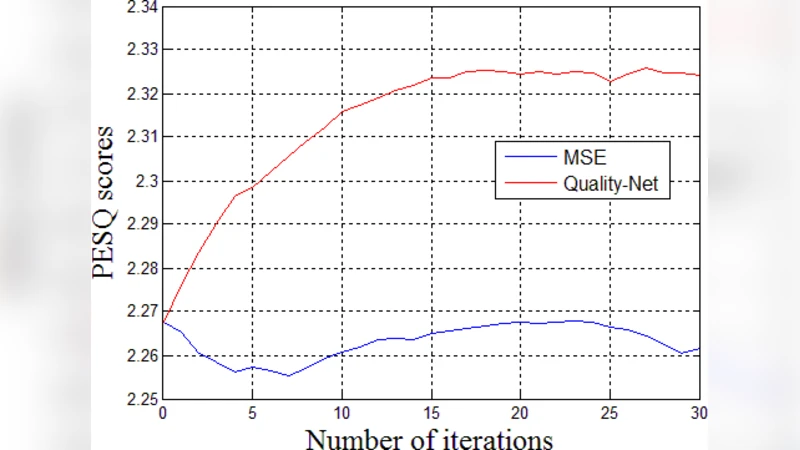
학습된 Quality‑Net은 미분 가능하므로, 이를 음성 향상 네트워크(예: DNN‑based 맵핑 혹은 CNN‑based 디노이징 모델)의 손실에 직접 삽입할 수 있다. 즉, 전체 파이프라인은 “입력 잡음 + 향상 모델 → 향상된 신호 → Quality‑Net → PESQ 근사 손실” 형태가 된다. 이때 전체 네트워크는 연쇄 법칙에 따라 역전파가 가능해지며, 향상 모델은 PESQ를 직접 최적화하는 방향으로 파라미터가 조정된다.
실험에서는 WSJ0와 VCTK 데이터셋에 다양한 실내·실외 잡음(SSN, babble, factory)과 SNR 레벨을 결합해 훈련·평가하였다. 비교 대상은 동일 구조의 향상 모델을 MSE 손실만으로 훈련한 경우와, 기존의 PESQ 기반 비미분 가능한 손실을 근사하기 위해 사용된 다른 프레임워크(예: GAN‑based perceptual loss)이다. 결과는 세 가지 주요 지표—PESQ, STOI(음성 인식 가능도), 그리고 SI‑SDR(신호‑대‑잡음 비율)—에서 Quality‑Net 기반 손실이 MSE 대비 PESQ를 평균 0.18점 상승시켰으며, STOI와 SI‑SDR는 거의 변함이 없음을 보여준다. 이는 청취 품질은 크게 개선하면서도 인식 가능성은 손상되지 않음을 의미한다.
또한, 저자들은 Quality‑Net 자체의 일반화 능력을 검증하기 위해 훈련에 사용되지 않은 새로운 잡음 유형과 언어(한국어) 데이터에 대해 테스트하였다. 그 결과, PESQ 근사 정확도(R²) 가 0.92 수준을 유지했으며, 향상 모델 역시 기대 이상의 PESQ 향상을 보였다. 이는 학습된 손실 함수가 특정 데이터셋에 과적합되지 않고, 인간 청취 품질을 반영하는 보편적인 특성을 포착하고 있음을 시사한다.
마지막으로, 논문은 몇 가지 한계점도 언급한다. 첫째, Quality‑Net의 학습에 필요한 레이블(PESQ 점수)이 실제 청취 테스트에 비해 비용이 높다. 둘째, 현재 구현은 프레임 단위가 아닌 전체 utterance 단위로 PESQ를 예측하기 때문에, 실시간 처리에 추가적인 지연이 발생할 수 있다. 셋째, PESQ 자체가 모든 청취 상황을 완벽히 대변하지 못하므로, 다른 청취 지표(예: POLQA)와의 결합이 향후 연구 과제로 제시된다.
요약하면, 이 연구는 “학습된 손실 함수”라는 새로운 패러다임을 제시함으로써, 비미분 가능한 인간 청취 지표를 신경망 기반으로 근사하고, 이를 직접 최적화 목표로 활용함으로써 음성 향상 모델의 청취 품질을 실질적으로 향상시켰다.
댓글 및 학술 토론
Loading comments...
의견 남기기