분류 정확도를 이용한 두 표본 검정: 고차원에서의 이론과 실용적 함의
초록
본 논문은 분류기의 정확도가 우연보다 ε만큼 높을 때, 해당 정확도를 검정통계량으로 사용하면 두 표본 검정이 가능함을 보인다. 고차원( d,n →∞) 상황에서 퍼뮤테이션 검정과 가우시안 근사 검정이 모두 일관성을 가지며, 특히 가우시안 평균 차이 검정에서 LDA·나이브 베이즈와 Hotelling 검정의 검정력 차이가 상수 1/√π 정도임을 밝혀냈다. 또한 타원형 분포와 최소극값 하한을 포함한 일반화 결과를 제시한다.
상세 분석
이 논문은 “분류 정확도 > ½ + ε”라는 아주 직관적인 조건만으로도 두 표본 검정의 일관성을 확보할 수 있음을 최초로 일반화된 형태로 증명한다. 첫 번째 주요 정리는 모든 차원과 모든 분류기에 대해 true error가 ε>0 만큼 chance보다 작을 경우, (a) 퍼뮤테이션 기반 검정이 일관적이며 (b) null 분포를 가우시안으로 근사한 검정도 일관적이라는 것이다. 여기서 “일관적”이란 검정의 파워가 n→∞, d→∞ 에서 1에 수렴함을 의미한다.
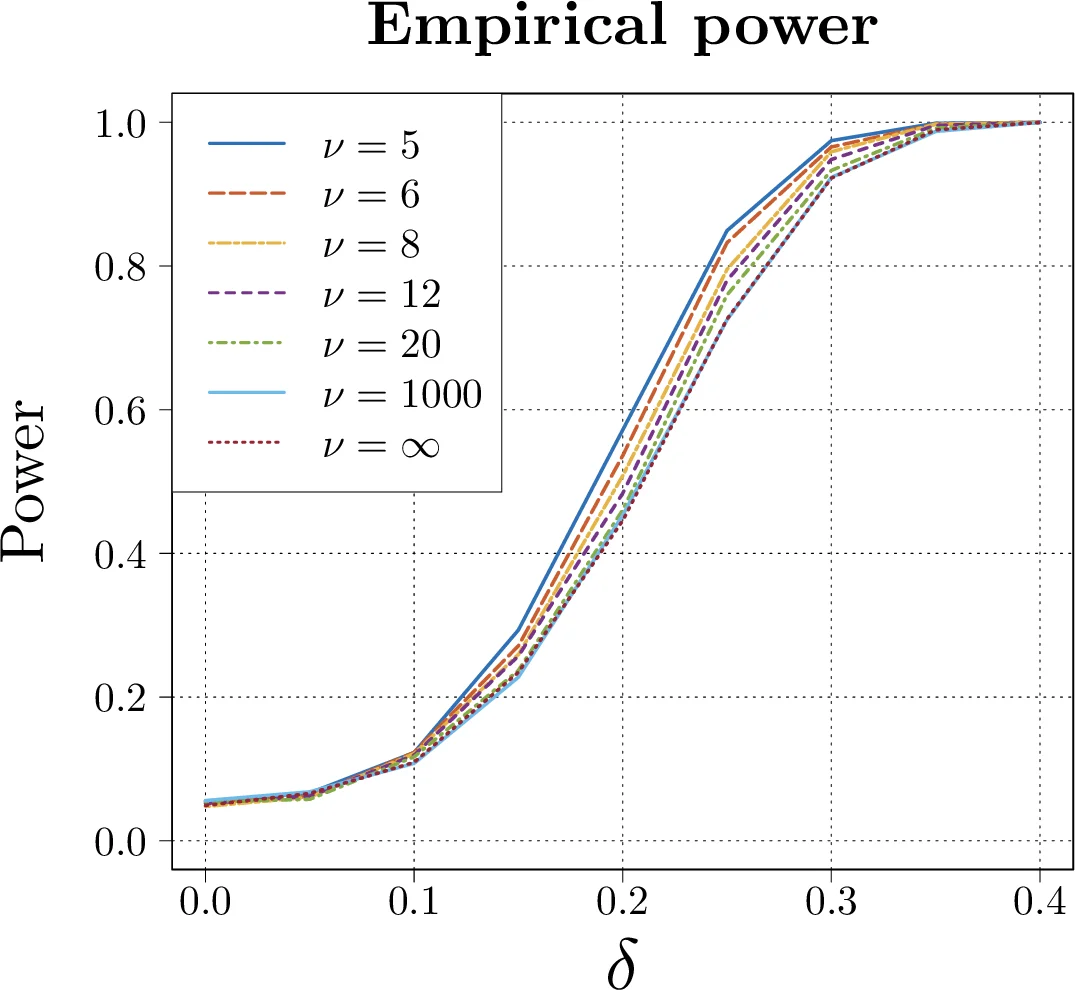
두 번째 핵심은 고차원 가우시안 평균 차이 문제( d/n→c∈(0,∞) )에 대한 정밀한 파워 분석이다. 공통 공분산 Σ가 알려졌을 때 Fisher LDA를 샘플 스플리팅으로 추정하고, 그 정확도를 중심·표준화한 통계량이 null와 local alternative 모두에서 표준 정규분포로 수렴함을 보였다(Thm 5.1, 6.1). 이를 이용해 검정력 식 (6.7)을 도출했으며, 이는 최소극값 검정(Hotelling T², Bai‑Saranadasa, Srivastava‑Du)의 파워와 정확히 일치한다는 점이 놀라웠다. 다만 LDA 기반 검정은 상수 1/√π≈0.564 만큼 효율이 낮아 “asymptotic relative efficiency (ARE) = 1/√π” 를 갖는다. 즉, 균형 샘플( n₁≈n₂ )에서는 LDA가 Hotelling보다 약 44 % 정도 힘이 약하지만, 차원이 커질수록 여전히 일관적인 검정이다.
공분산이 미지인 경우에도 “naïve Bayes”(공분산을 대각선으로 근사)와 같은 선형 분류기를 사용하면 동일한 ARE를 얻는다(Thm 7.1). 이는 공분산 추정 오차가 검정력에 미치는 영향을 정확히 정량화한 결과이며, 고차원에서 공분산을 완전 추정하기 어려운 현실적 상황에 적용 가능하다.
타원형 분포(유한 kurtosis)로 일반화한 결과(Thm 8.8)에서는 가우시안 경우와 동일한 형태의 파워 식이 나오지만, 상수는 √2·fₓ(0) (여기서 fₓ는 마진 밀도) 로 조정된다. 특히 다변량 t‑분포와 같이 꼬리가 무거운 경우, 이 상수가 1보다 커져 LDA 기반 검정이 Hotelling보다 상대적으로 더 효율적일 수 있음을 보여준다.
논문은 또한 고차원 두 표본 평균 검정의 minimax 하한을 정확히 구하고(Prop 3.1), d=o(n) 일 때 Hotelling T²가 이 하한을 달성함을 증명한다(Theorem 4.1). 이는 기존 문헌에서 “Hotelling은 고차원에서 무력하다”는 인식에 중요한 정정이다.
실험 섹션에서는 가우시안, t‑분포, 실제 뇌영상 데이터 등에 대해 제안한 검정과 기존 Hotelling, 그래프 기반 검정을 비교한다. 시뮬레이션 결과는 이론적 파워 식과 매우 일치하며, 특히 차원·표본 비율이 0.5~2 사이일 때 LDA 기반 검정이 실용적으로 충분히 강력함을 확인한다.
실용적 메시지는 두 가지로 정리된다. (1) 데이터가 구조화되지 않았거나 대체 검정통계량을 설계하기 어려운 경우, 복잡한 분류기(예: CNN, Random Forest)를 이용한 정확도 검정이 합리적인 선택이 될 수 있다. (2) 데이터가 충분히 풍부하고 구조가 명확하면, Hotelling이나 고차원 전용 검정(예: 스케일된 T², 그래프 검정)을 사용하는 것이 파워 면에서 더 유리하다.
전반적으로 이 논문은 머신러닝 실무자와 이론 통계학자 사이의 격차를 메우며, “분류 정확도”라는 직관적인 지표를 고차원 가설 검정의 엄밀한 통계적 도구로 전환하는 방법론적 토대를 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기