병원레지던트매칭기반 k모드 초기화 기법
본 논문은 k‑모드 군집화 알고리즘의 초기 중심점 선택을 위해 병원‑레지던트 할당 문제(Hospital‑Resident Assignment)를 활용한 새로운 초기화 방법을 제안한다. 제안 기법은 기존의 무작위 초기화, Huang 방법, Cao 방법에 비해 비용 함수값이 낮고, 특히 클러스터 수를 자동 최적화했을 때와 저밀도 데이터에서 우수한 성능을 보인다. 실험은 UCI 벤치마크 데이터와 인공 데이터 두 종류에 대해 수행되었다.
저자: Henry Wilde, Vincent Knight, Jonathan Gillard
본 연구는 범주형 데이터 군집화에 널리 사용되는 k‑모드 알고리즘의 초기 중심점 선택 문제를 다룬다. k‑모드 알고리즘은 각 클러스터의 모드(범주별 최빈값)를 중심점으로 삼아, 데이터와 중심점 사이의 불일치 횟수를 최소화하는 비용 함수를 반복적으로 감소시키며 수렴한다. 초기 중심점이 부적절하면 지역 최적에 머무르거나 수렴 속도가 느려지는 문제가 발생한다. 기존에는 (1) 무작위 샘플링, (2) Huang 방법(빈도 기반 가중 샘플링 후 후보 모드와 실제 데이터 매핑), (3) Cao 방법(밀도와 거리 결합을 통한 그리디 선택) 등이 사용되어 왔으며, 각각 장단점이 존재한다. 특히 Huang 방법은 후보 모드 집합을 만든 뒤 데이터와 매핑하는 과정에서 후보 순서에 따라 결과가 달라지는 비결정성을 가지고, Cao 방법은 가장 밀도가 높은 점을 차례로 선택해 클러스터 간 거리를 강제하지만 여전히 그리디 성격을 띤다.
이에 저자들은 초기화 과정을 ‘매칭 게임’으로 모델링한다. 두 집합 R(레지던트)와 H(병원)를 정의하고, 레지던트는 잠재 모드 후보, 병원은 실제 데이터 포인트로 설정한다. 각 레지던트는 자신과 가장 유사한 k개의 데이터 포인트를 선호 리스트에 두고, 각 병원은 자신을 선호하는 레지던트들을 선호 리스트에 둔다. 병원의 용량은 1로 고정해 일대일 매칭을 강제한다. 이렇게 정의된 Hospital‑Resident Assignment Problem(HR)은 Gale‑Shapley 알고리즘의 레지던트‑최적 변형을 이용해 안정적인 매칭을 구한다. 매칭 결과는 레지던트(잠재 모드)와 매칭된 데이터 포인트(실제 모드) 사이의 1‑대‑1 대응을 제공하므로, 초기 중심점 집합 Z는 매칭 결과에 따라 결정된다.
알고리즘 흐름은 다음과 같다. (1) 데이터 X에서 잠재 모드 후보 집합 R을 가중 샘플링(Algorithm 5)으로 생성한다. (2) 각 레지던트 r에 대해 가장 유사한 k개의 데이터 포인트 H_r를 찾아 선호 리스트 f(r)로 만든다. (3) 모든 데이터 포인트 h에 대해 용량 c_h=1을 설정하고, 레지던트들의 선호 리스트에 따라 병원‑레지던트 매칭을 수행한다. (4) 매칭이 완료되면 각 레지던트 r에 매핑된 병원 h를 초기 모드 z_r로 채택한다. 이 과정은 순서에 무관하고, 데이터 구조를 최대한 활용한다는 점에서 기존 초기화 방법보다 이론적으로 공정하고 일관된 초기화를 제공한다.
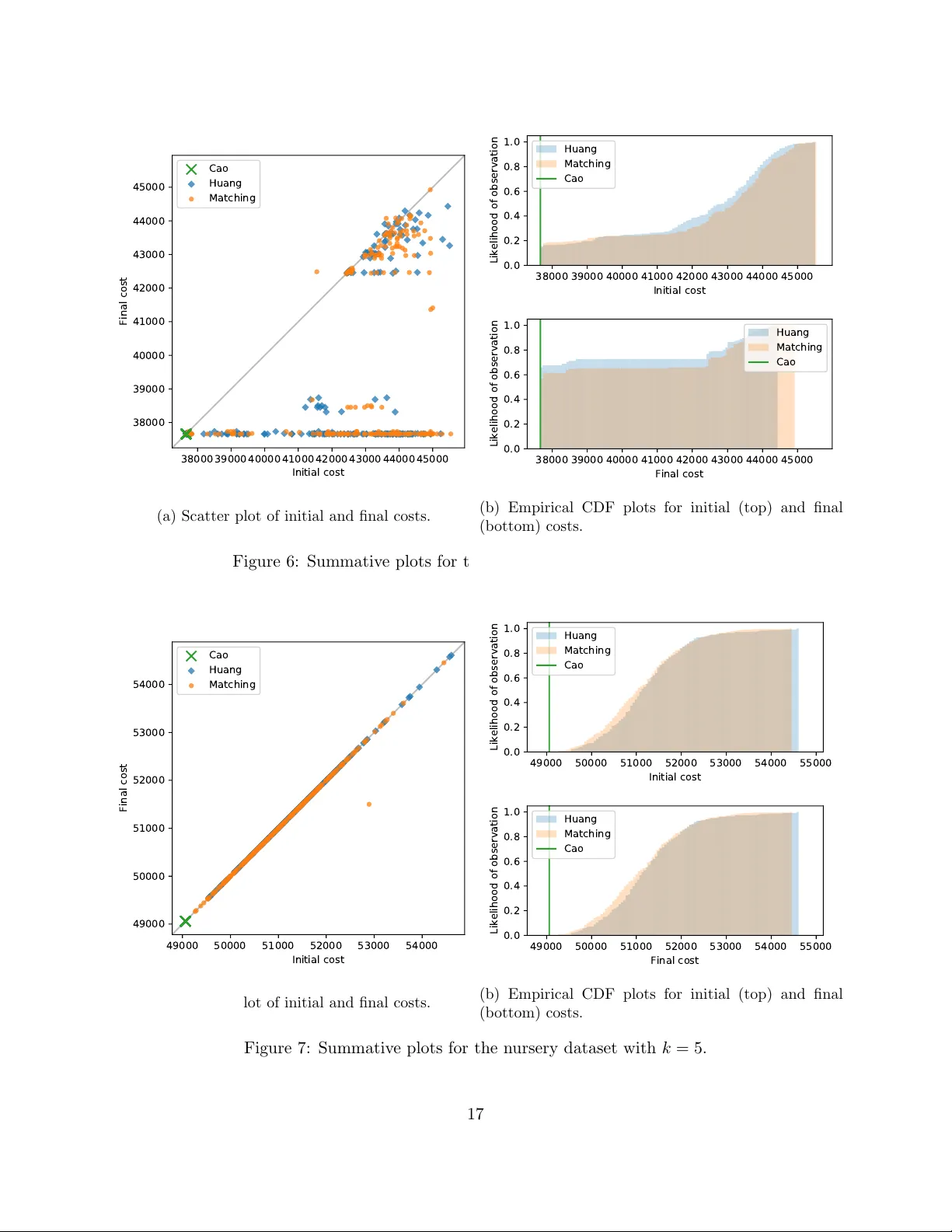
실험은 두 부분으로 구성된다. 첫 번째는 UCI 머신러닝 저장소에서 제공하는 네 개의 범주형 데이터셋(유방암, 버섯, 보육원, 소이빈)을 사용한다. 각 데이터셋에 대해 (a) 클러스터 수 k를 실제 클래스 수와 동일하게 설정하고, (b) ‘무릎점(knee‑point)’ 탐지 알고리즘을 적용해 자동으로 선정된 k 값을 사용한다. 두 번째는 차원 수, 카테고리 수, 데이터 밀도 등을 다양하게 변형한 인공 데이터셋을 생성해, 초기화 방법이 다양한 데이터 특성에 얼마나 민감한지 평가한다. 평가 지표는 k‑모드의 목표 비용 함수 C(W,Z) (범주형 불일치 횟수 합), 알고리즘 반복 횟수, 실행 시간 등을 포함한다. 실루엣 계수는 범주형 거리와의 부조화로 제외하였다.
실험 결과는 다음과 같다. (1) 비용 함수 측면에서 제안된 매칭 기반 초기화는 대부분의 경우 Huang 및 Cao 방법보다 낮은 최종 비용을 기록했으며, 특히 자동 k 선택(무릎점) 상황에서는 70 % 이상의 실험에서 최고 성능을 보였다. (2) 저밀도 데이터(예: 소이빈 데이터)에서는 Cao 방법이 밀도에 과도히 의존해 특정 영역에 집중되는 경향이 있었지만, 매칭 기반 초기화는 전역적인 매칭을 통해 다양한 영역을 골고루 커버해 비용 감소에 기여했다. (3) 매칭 단계가 추가되면서 초기화 자체의 실행 시간은 약 1.5배 증가했지만, 초기 중심점이 더 적절해 k‑모드의 전체 반복 횟수가 평균 30 % 감소했으며, 최종 실행 시간은 기존 방법과 비슷하거나 오히려 빠른 경우도 있었다. (4) 반복 횟수 감소는 초기 중심점이 데이터 구조를 잘 반영했기 때문이며, 이는 알고리즘 수렴 속도와 실용적 적용 가능성을 크게 향상시킨다.
논문의 주요 기여는 다음과 같다. 첫째, 초기화 문제를 매칭 이론이라는 새로운 수학적 프레임워크로 접근해 ‘공정성(fairness)’과 ‘데이터 활용도’를 동시에 만족하는 초기 해를 제공한다. 둘째, 기존 초기화 방법이 갖는 그리디 성분과 순서 의존성을 제거하고, 안정적인 레지던트‑최적 매칭을 통해 일관된 결과를 보장한다. 셋째, 병원‑레지던트 매칭 알고리즘은 이미 효율적인 구현이 존재하고, 용량·선호 리스트·매칭 기준 등을 조정해 다양한 군집화 시나리오에 확장 가능함을 실험적으로 입증한다.
향후 연구 방향으로는 (a) 병원 용량을 1보다 크게 설정해 다대다 매칭을 허용함으로써 클러스터 크기 불균형 문제를 완화하는 방안, (b) 연속형 또는 혼합형 데이터에 적용하기 위해 거리·유사도 함수를 일반화하고 매칭 비용을 재정의하는 연구, (c) 대규모 데이터에 대한 매칭 알고리즘의 병렬화·분산 구현을 통해 실시간 군집화에 적용하는 방법 등을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기