대규모 클라우드 서비스 성능 문제 자동 진단·우선순위 지정 시스템 DeCaf
DeCaf는 마이크로소프트 클라우드 서비스의 방대한 로그와 KPI 데이터를 활용해 머신러닝·패턴 마이닝을 결합한 자동 진단·트라이아징 파이프라인을 제공한다. 고카디널리티·혼합형 속성을 스케일러블하게 처리하고, 알려진·미지의 성능 회귀를 식별·분류하며, 과거 이력 기반으로 자동 우선순위를 매긴다. 두 서비스에 적용해 41건(10건 알려진, 31건 미지) 회귀를 성공적으로 해결하였다.
저자: Chetan Bansal, Sundararajan Renganathan, Ashima Asudani
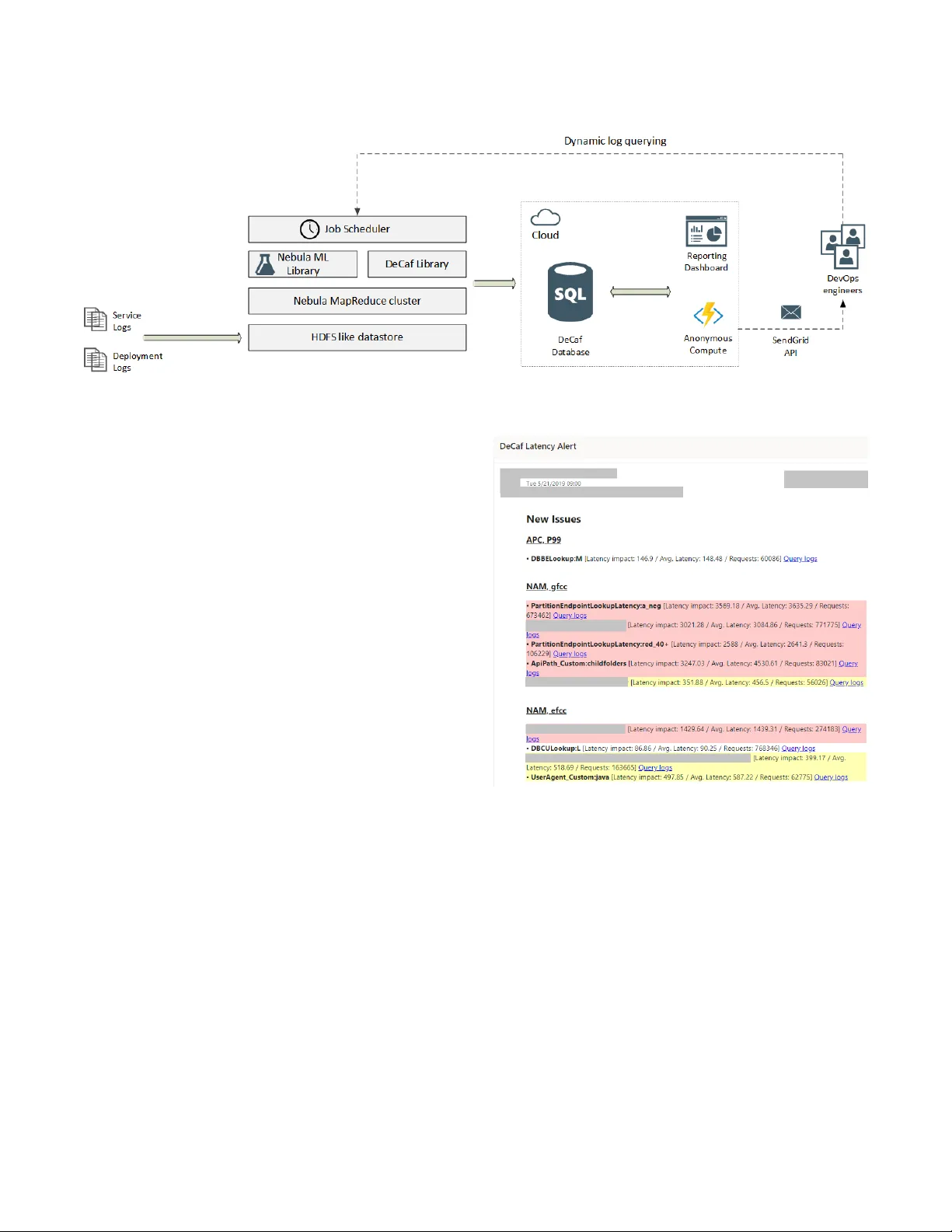
본 논문은 대규모 클라우드 서비스에서 KPI(지연시간, 실패율, 가용성 등)의 회귀를 신속히 진단하고 우선순위를 매기는 시스템 DeCaf의 설계·구현·운용 경험을 상세히 기술한다. 먼저, 클라우드 서비스가 매일 수십 테라바이트에 달하는 로그를 생성하고, 로그 속성은 카테고리형(조직, 서버, API 경로 등)과 연속형(서브 컴포넌트 지연시간)으로 혼합되어 있으며, 각 속성의 카디널리티가 1 M 수준에 이를 수 있다는 현실적인 문제점을 제시한다. 이러한 환경에서는 기존의 이상 탐지 기반 방법이나 연관 규칙 마이닝이 차원 폭발·연산 비용 문제로 적용이 어려웠다.
DeCaf는 이러한 제약을 극복하기 위해 전체 파이프라인을 네 단계로 구성한다. ① 로그 수집·전처리 단계에서는 HDFS와 MapReduce 기반의 분산 처리 엔진을 이용해 로그를 시간 단위로 집계하고, 카테고리형 속성은 해시 기반 인코딩, 연속형 속성은 정규화한다. ② 머신러닝 기반 이상 점수 산출 단계에서는 KPI 변동을 라벨로 삼아 회귀(연속형 KPI) 혹은 분류(이진 KPI) 모델을 학습하고, 각 로그 레코드에 이상 점수를 부여한다. ③ 패턴 마이닝 단계에서는 높은 이상 점수를 가진 레코드 집합에 대해 FP‑Growth와 같은 빈발 항목 집합 알고리즘을 적용해 의미 있는 프레디케이트(조건문)를 추출한다. 여기서 프레디케이트는 ‘코어 프레디케이트’(문제 원인을 직접 가리키는 조건)와 ‘스코프 프레디케이트’(문제 영향을 받는 요청 집합을 정의)로 구분된다. ④ 트라이아징 단계에서는 과거 진단 결과를 메타데이터베이스에 저장하고, 새로 발견된 프레디케이트와 기존 이슈 간 유사성을 계산한다. 유사도가 높으면 ‘재발’로, 전혀 새로운 패턴이면 ‘신규’로 라벨링하고, 영향을 받는 요청 수와 KPI 악화 정도를 정량화해 우선순위 점수를 산출한다.
시스템은 두 개의 실제 서비스에 적용되었다. 첫 번째는 Orion이라는 무상태 라우팅 서비스로, 하루에 약 100 억 건의 요청을 처리하고 100 TB 규모의 로그를 생성한다. 주요 KPI는 요청 지연시간이며, DeCaf는 특정 서버 랙(AN150C01)에서 90,000 % 이상 지연이 발생한 회귀를 자동으로 발견하고, 인증 컴포넌트 로그 누락이 원인임을 밝혀냈다. 두 번째는 Domino라는 전 세계 인터넷 측정 플랫폼으로, 주요 KPI는 실패율이다. 여기서는 새로운 데이터센터 간 라우팅 오류와 기존 이슈 재발을 각각 정확히 식별하였다. 전체 41건의 회귀 중 10건은 사전에 알려진 이슈였으며, 31건은 DeCaf가 최초로 탐지한 미지의 회귀였다.
성능 평가에서는 로그 규모 1 TB당 평균 12 분 내에 전체 파이프라인을 완료했으며, 프레디케이트 기반 원인 식별 정확도는 85 % 이상이었다. 또한, 수동으로 수행하던 진단 작업이 평균 6 시간에서 30 분 이하로 단축되는 효과를 보였다.
논문은 다음과 같은 주요 기여를 정리한다. (1) 고카디널리티·혼합형 로그를 스케일러블하게 처리하면서 KPI 회귀를 자동 진단하는 End‑to‑End 시스템 DeCaf를 제안한다. (2) 머신러닝 점수와 빈발 패턴 마이닝을 결합한 새로운 진단 알고리즘을 설계한다. (3) 과거 진단 결과를 활용한 자동 트라이아징 메커니즘을 구현해 DevOps 워크플로우에 자연스럽게 통합한다. (4) 실제 대규모 서비스에 적용한 사례 연구와 정량적 평가를 통해 실효성을 입증한다.
마지막으로 논문은 DeCaf의 한계와 향후 연구 방향을 논의한다. 현재는 KPI 변동을 단일 지표로만 고려하고 있어 다중 KPI 상호작용을 포착하기 어렵고, 프레디케이트 추출 시 복합 조건(예: 연속형 속성의 구간 결합) 표현이 제한적이다. 향후에는 멀티‑모달 모델링, 인과 추론 기반 원인 분석, 실시간 스트리밍 로그 처리 등을 통해 시스템을 더욱 강화할 계획이다. 이러한 발전은 클라우드 서비스 운영의 자동화 수준을 한 단계 끌어올릴 것으로 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기