대규모 바이오의학 지식 그래프에서 컨텍스트 정보 활용의 새로운 지평
초록
이 논문은 바이오의학 분야에서 자연어 의미를 결정하는 핵심 요소인 ‘컨텍스트’ 정보를 대규모 지식 그래프에 효과적으로 통합하고 활용하는 새로운 방법론을 제안합니다. PubMed 및 SCAIView 데이터를 기반으로 구축된 7,100만 개 이상의 노드와 8억 5천만 개의 관계를 가진 초대규모 그래프에서, 레이블 속성 그래프와 폴리글랏 퍼시스턴스 시스템을 활용해 컨텍스트 마이닝, 복잡한 그래프 쿼리, 지식 발견을 수행하는 프레임워크를 소개합니다. 27개의 실제 사용 사례를 통해 이 접근법의 실용성을 입증합니다.
상세 분석
이 논문의 핵심 기술적 기여는 단순한 주석(annotation)을 넘어서는 일반화된 ‘컨텍스트’ 개념을 그래프 이론을 통해 정형화하고, 이를 초대규모 바이오의학 지식 그래프에 적용 가능한 아키텍처로 구현한 점에 있습니다. 기존의 RDF 트리플 스토어가 가진 내부 구조 부재 및 복잡한 질의의 한계를 지적하며, Neo4j 기반의 레이블 속성 그래프를 채택한 것은 중요한 기술적 선택입니다. 이는 노드와 관계에 내부 속성과 라벨을 부여할 수 있어, 서브그래프 매칭이나 트래버설 같은 복잡한 탐색 질의를 가능하게 합니다.
또한, 단일 데이터베이스의 확장성 한계를 극복하기 위한 ‘폴리글랏 퍼시스턴스’ 접근법은 실용적인 통찰을 제공합니다. 대용량 그래프 처리를 위해 이기종 저장 기술을 결합하는 이 방식은 성능 최적화를 위한 현실적인 해법입니다.
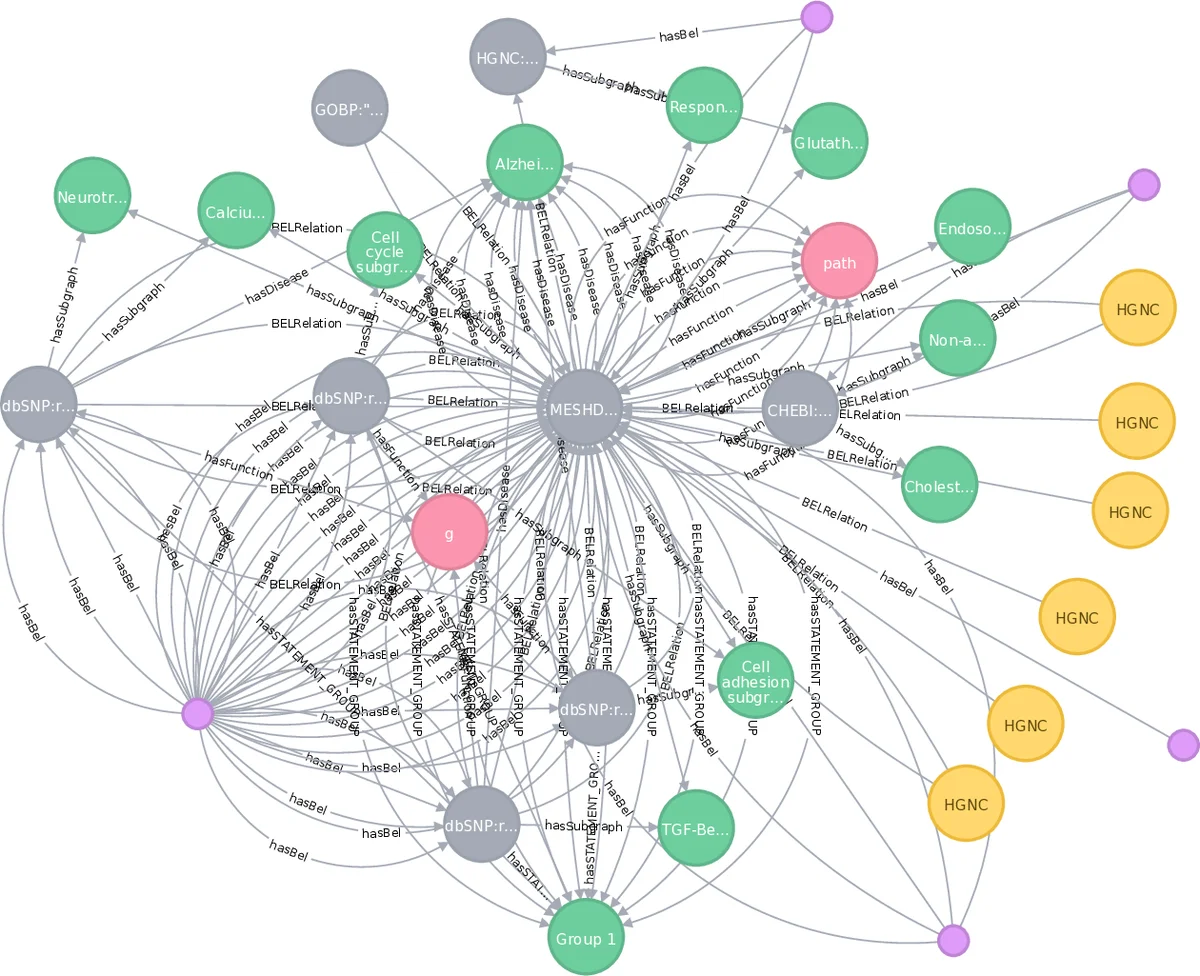
가장 혁신적인 부분은 ‘컨텍스트 메타그래프’와 ‘확장 컨텍스트 서브그래프’라는 그래프 이론적 정의를 도입한 것입니다. 지식 그래프 G 내의 모든 엔티티 E와 관계 R에 컨텍스트 집합 C를 매핑하는 함수 con()을 정의하고, 이를 통해 원본 그래프와 컨텍스트 간의 이중층 구조(하이퍼그래프 H_G|M)를 형성합니다. 이는 단순한 연결 이상으로, 서로 다른 의미 계층(예: 분자 계층, 문서 계층, 메커니즘 계층) 간의 임베딩 관계를 수학적으로 모델링하여, 문맥에 따른 지식의 다층적 해석과 탐색을 가능하게 하는 이론적 토대를 마련했습니다. 이 구조는 27개의 실제 사용 사례에 적용되어 복잡한 생의학적 질문(예: 공병성 메커니즘, 인구통계학적 정보에 따른 약물 반응 차이 등)에 대한 그래프 질의로 구체화되었습니다.
댓글 및 학술 토론
Loading comments...
의견 남기기