협동 MARL에서 소수의 좋은 경험을 활용한 새로운 해결법
초록
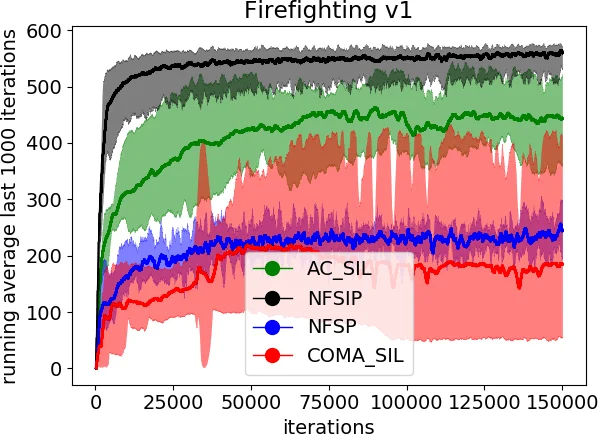
본 논문은 협동 다중에이전트 강화학습(MARL)에서 긍정적인 보상이 매우 드물게 나타나는 상황을 다룬다. 기존의 단일 에이전트 희소보상 기법과 MARL의 비정상성·확장성 해결책을 결합할 수 없다는 한계를 지적하고, NFSP(Neural Fictitious Self‑Play)에 자기모방(self‑imitation) 메커니즘을 추가한 NFSIP(Neural Fictitious Self‑Imitation Play)를 제안한다. NFSIP는 (1) 좋은 경험을 우선순위 버퍼에 저장해 반복 학습하고, (2) 정책 평균화에 가중치를 부여해 좋은 정책이 사라지지 않도록 하며, (3) 일반화된 약화 가상플레이(GWFP) 이론에 기반한 수렴 보장을 제공한다. 세 가지 벤치마크 환경에서 기존 최첨단 MARL 알고리즘보다 현저히 높은 성능을 기록한다.
상세 분석
본 연구는 협동 MARL에서 “few good experiences”라는 특수한 희소보상 문제를 체계적으로 정의하고, 그 원인을 세 가지로 구분한다. 첫째, 다수 에이전트가 동시에 탐색해야 하므로 개별 에이전트 수준의 탐색보다 복합적인 협동 탐색이 필요하다. 둘째, 모든 에이전트가 동시에 학습함에 따라 환경이 비정상화(non‑stationary)되어 기존의 Q‑learning 기반 방법이 불안정해진다. 셋째, 에이전트 수가 증가함에 따라 상태·행동 공간이 기하급수적으로 확대돼 샘플 효율성이 급격히 떨어진다.
이러한 문제를 해결하기 위해 저자들은 NFSP의 두 핵심 구성요소—근사 최적응답을 위한 DQN과 평균 정책을 학습하는 SL 네트워크—에 자기모방 학습(self‑imitation learning, SIL) 구조를 삽입한다. 구체적으로, 에피소드 종료 시 사회복지(social welfare)가 기존 최고값을 초과하는 경우 해당 에피소드를 누적 보상 R(s,a)와 함께 우선순위 버퍼 M_SI에 저장한다. 이후 학습 단계에서 (i) 일반 버퍼 M_RL과 M_SL을 이용해 Q‑network와 π‑network를 모두 업데이트하고, (ii) M_SI에 저장된 “좋은” 경험에 대해서는 Q‑network가 현재 가치 추정보다 낮게 예측할 경우에만 손실을 가중시켜 반복 학습한다. 이때 손실 함수에
댓글 및 학술 토론
Loading comments...
의견 남기기