소셜미디어 빅데이터 기반 감성 분석 플랫폼 SoMABiT
초록
본 논문은 급증하는 소셜미디어 데이터를 빅데이터 기술과 결합해 고객 감성을 자동으로 추출·분석하는 SoMABiT 플랫폼을 제안한다. MapReduce 기반 분산 알고리즘을 설계해 대용량, 다형식 데이터에 대한 확장성을 확보하고, 감성 사전 및 기계학습 모델을 활용해 텍스트, 이미지, 동영상 등 다양한 형태의 피드백을 정량화한다. 기존 연구와 비교해 데이터 수집·전처리·분석·시각화까지 일원화된 파이프라인을 제공함으로써 기업이 실시간 시장 인사이트를 도출할 수 있도록 지원한다.
상세 분석
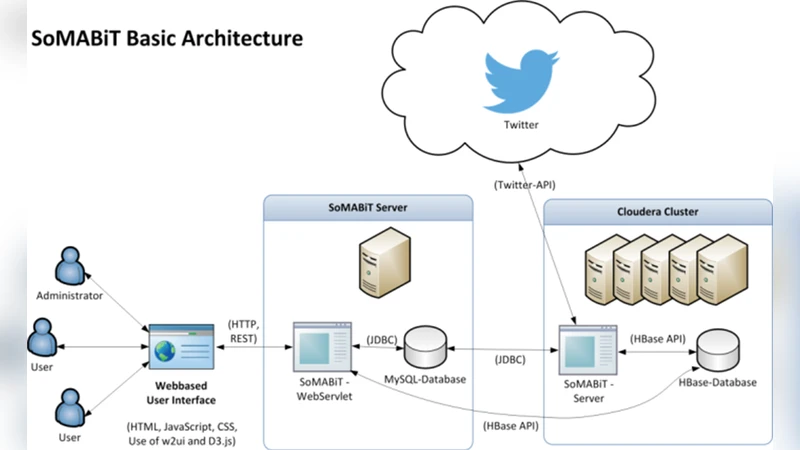
SoMABiT는 “Social Media Analysis using Big Data Technology”의 약어로, 소셜미디어에서 발생하는 비정형·다중모달 데이터를 빅데이터 프레임워크 위에 올려 감성 분석을 수행한다는 점에서 흥미로운 시도를 보여준다. 가장 큰 기술적 핵심은 MapReduce를 이용한 분산 처리 구조이다. 데이터 수집 단계에서 Twitter, Facebook, Instagram 등 다양한 API를 통해 스트리밍 데이터를 HDFS에 저장하고, 이후 Map 단계에서 텍스트 토큰화·정규화, 이미지 메타데이터 추출, 동영상 자막 생성 등을 병렬로 수행한다. Reduce 단계에서는 감성 사전 기반 점수와 사전 학습된 딥러닝 모델(예: LSTM, CNN) 출력을 결합해 최종 감성 점수를 산출한다. 이 과정에서 데이터 스키마가 고정되지 않은 “스키마-온-리드” 방식을 채택해, 새로운 플랫폼이 추가되더라도 파이프라인을 재구성할 필요가 없다는 장점이 있다.
하지만 몇 가지 한계도 존재한다. 첫째, MapReduce는 배치 처리에 최적화돼 있어 실시간 스트리밍 감성 분석에는 Spark Streaming이나 Flink과 같은 인메모리 연산 프레임워크가 더 적합할 수 있다. 논문에서는 실시간 응답성을 언급하지만 구현 세부 사항이 부족해 실제 운영 환경에서의 지연 시간(Latency)과 처리량(Throughput)을 평가하기 어렵다. 둘째, 감성 사전 기반 접근법은 문화·언어·도메인 특이성을 반영하기 어렵다. 다국어 데이터가 포함된 경우 사전 확장이 필요하지만, 논문에서는 영어와 한국어에 국한된 실험만 제시한다. 셋째, 이미지·동영상에 대한 감성 추출은 “시각적 감성”을 텍스트와 동일한 스코어링 체계에 매핑하려는 시도로 보이지만, 구체적인 피처 추출 방법(예: CNN 기반 이미지 캡션 생성)과 평가 지표가 명시되지 않아 재현 가능성이 낮다.
또한, 실험 설계가 비교 대상이 부족하다. 기존의 단일 서버 기반 감성 분석 시스템 혹은 Spark 기반 구현과의 성능·정확도 비교가 없으며, 확장성 검증을 위해 데이터 규모를 10배, 100배로 늘린 경우의 속도 향상 비율이 제시되지 않는다. 이는 SoMABiT의 “any data volume”이라는 주장에 대한 신뢰성을 저하시킨다.
마지막으로, 플랫폼의 운영 관리 측면—예를 들어, 클러스터 자원 할당, 장애 복구, 데이터 프라이버시·보안 정책—에 대한 논의가 전혀 없으며, 기업 적용 시 고려해야 할 법적·윤리적 이슈도 다루지 않는다. 이러한 점들을 보완한다면 SoMABiT는 학술적·산업적 가치를 동시에 확보할 수 있을 것이다.
댓글 및 학술 토론
Loading comments...
의견 남기기