딥러닝의 다항시간 보편성 및 한계
이 논문은 다항시간 내에 학습 가능한 함수 분포를 딥러닝이 언제, 어떻게 학습할 수 있는지를 이론적으로 규명한다. SGD 기반 신경망은 초기화와 학습 파라미터가 다항시간 안에 구현될 경우, 모든 다항시간 학습 가능한 함수 분포를 보편적으로 학습할 수 있음을 보인다. 반면, 배치 크기가 충분히 큰 GD(전역 경사 하강법)는 교차예측가능성(cross‑predictability)이 초다항적으로 낮은 함수 분포를 학습하지 못한다. 이는 SGD와 GD,…
저자: Emmanuel Abbe, Colin S, on
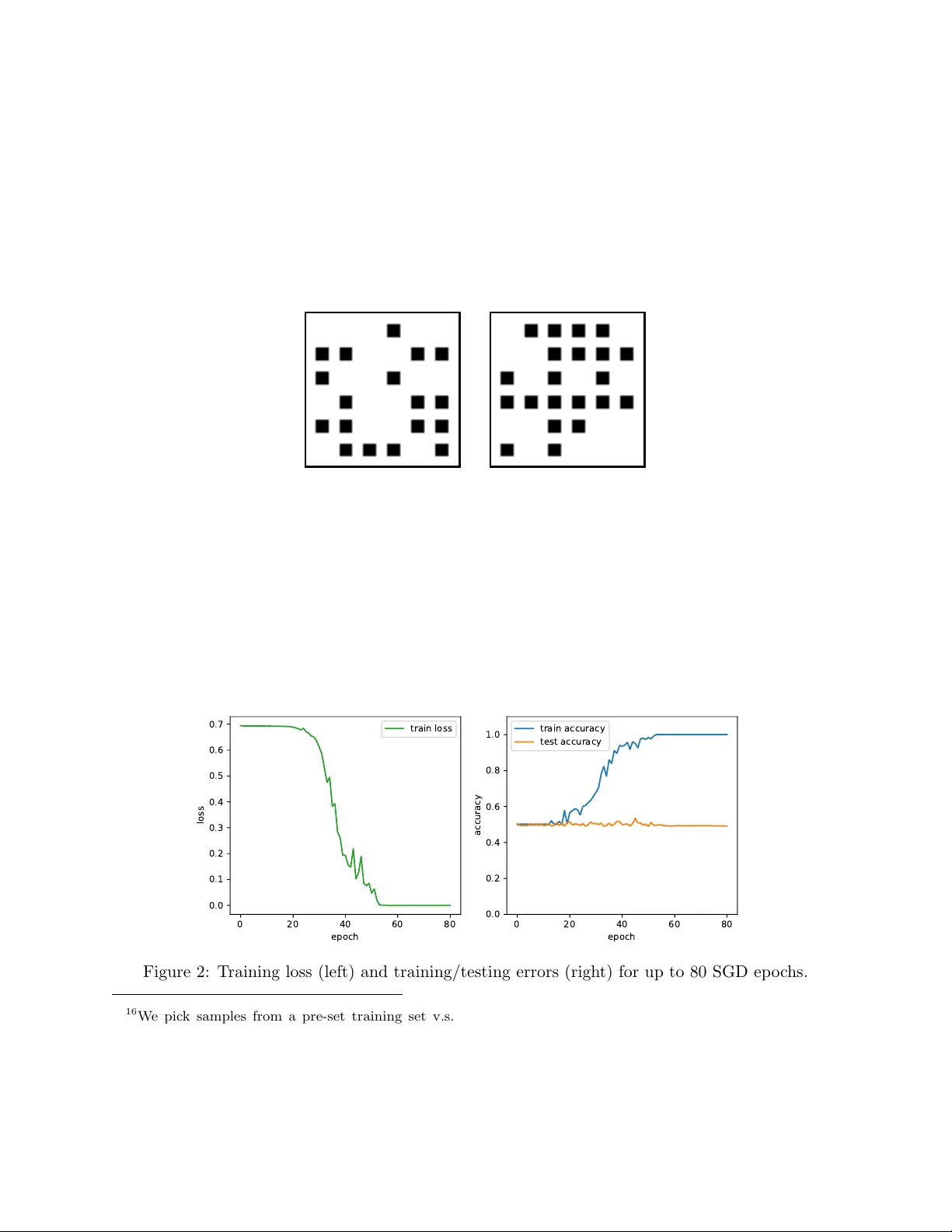
본 논문은 “다항시간 내에 학습 가능한 함수 분포를 딥러닝이 언제, 어떻게 학습할 수 있는가”라는 근본적인 질문에 답하고자 한다. 이를 위해 저자들은 두 가지 상반된 결과를 제시한다.
첫 번째는 SGD(확률적 경사 하강법)를 이용한 신경망 학습이 보편적이라는 정리이다. 저자들은 다항 크기의 신경망을 다항 시간 안에 초기화하고, 학습률, 스텝 수, 그리고 다항 수준의 잡음까지 허용하는 SGD 과정을 설계한다. 핵심 아이디어는 ‘범용 초기화’를 사용해, 임의의 효율적인 학습 알고리즘 A를 신경망 내부에서 시뮬레이션하는 것이다. 구체적으로, A의 연산을 신경망의 가중치와 활성화 함수에 매핑하고, SGD를 통해 그 연산 흐름을 재현한다. 이때 가중치의 정밀도와 잡음이 다항 수준으로 제한되더라도 시뮬레이션 정확도가 유지됨을 증명한다. 따라서 함수 분포 (P_X, P_F)가 다항시간에 학습 가능하면, 동일한 샘플 복잡도와 시간 복잡도로 SGD‑학습 신경망이 동일한 정확도를 달성한다는 ‘보편성’ 정리를 얻는다. 이 결과는 기존에 ERM(Experience Risk Minimization)이 NP‑hard이라는 사실과 대비되어, 최적화 오류까지 다항시간에 제어 가능함을 의미한다.
두 번째는 GD(전역 경사 하강법)와 SQ(Statistical Query) 알고리즘이 보편적이지 않다는 부정적 정리이다. 여기서는 새로운 복합 지표인 교차예측가능성(Cross‑Predictability, CP)을 도입한다. CP_m(P_X, P_F)는 m개의 샘플에 대해 두 독립적인 함수 f, f′∈P_F가 동일한 입력 x에 대해 얼마나 상관관계를 갖는지를 제곱 평균으로 측정한다. CP가 초다항적으로 작은 경우, 즉 함수들 간의 평균 상관이 거의 없을 때, GD는 배치 크기가 다항 수준 이상이면 일반화 오류가 1/2에 수렴한다는 하한을 보인다. 이를 정량화하기 위해 ‘정크 플로우(Junk Flow)’라는 개념을 도입한다. 이는 무작위 라벨에 대해 GD가 누적하는 그래디언트 노름을 의미하며, 초기화와 네트워크 구조에만 의존한다. 최종 일반화 오류 하한은 ½ − (1/σ)·JF·(1/m + CP_∞) 형태로 표현되며, 여기서 σ는 추가된 잡음 수준이다. 이 식은 배치 크기가 충분히 크고 CP가 충분히 낮을 때, GD가 전혀 학습하지 못함을 보인다. 특히, 다항 차수의 모노미얼을 학습할 수 있는 경우는 차수가 상수인 경우에만 제한된다. 이는 기존 SQ 알고리즘이 파리티와 같은 함수들을 학습하지 못하는 것과 직접적인 연관이 있다.
논문은 또한 SGD가 보편성을 유지하는 데 필요한 조건을 정밀히 분석한다. 배치 크기가 1인 순수 SGD에서는 위의 하한이 사라져, CP가 낮아도 학습이 가능함을 보인다. 그러나 배치 크기가 다항 수준으로 증가하면, SGD는 GD와 동일한 한계에 직면한다. 추가적으로, 가중치 업데이트 수를 제한하는 좌표 하강법이나 초기화·그래디언트에 과도한 잡음을 주입하는 경우에도 SGD의 보편성이 무너지며, 이는 ‘노이즈 임계값’과 ‘업데이트 제한’이라는 두 축으로 정리된다.
이러한 결과는 딥러닝 이론에 중요한 시사점을 제공한다. 첫째, SGD가 단순히 최적화 기법을 넘어, 학습 가능한 함수 클래스 자체를 확장시키는 메커니즘임을 증명한다. 둘째, GD와 SQ 알고리즘이 갖는 근본적인 제한을 명시적으로 보여줌으로써, 실제 대규모 배치 학습이 언제 실패할 수 있는지를 이론적으로 예측할 수 있다. 셋째, 교차예측가능성이라는 새로운 복합 지표는 함수 분포의 학습 난이도를 평가하는 도구로 활용될 수 있으며, 기존의 통계적 차원(Statistical Dimension)과는 다른 관점을 제공한다. 넷째, 초기화 설계와 잡음 관리가 딥러닝의 보편성에 미치는 영향을 정량화함으로써, 실무적인 네트워크 설계와 하이퍼파라미터 튜닝에 대한 이론적 가이드를 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기