양자 인터랙티브 통신을 위한 저노이즈 대용량 알파벳 부호화
초록
본 논문은 다중 라운드 양자 통신 프로토콜을 저노이즈 환경에서 거의 용량에 근접하도록 시뮬레이션하는 방법을 제시한다. 임의의 n 라운드 프로토콜을 동일 알파벳의 잡음 채널에 대해 (n(1+Θ(\sqrt{\epsilon}))) 번 사용하면서, 전체 실패 확률을 (2^{-Θ(n\epsilon)}) 이하로 억제한다. 사전 공유된 랜덤성이나 얽힘이 필요 없으며, 기존 양자 결과보다 낮은 상수 오버헤드로 개선된다.
상세 분석
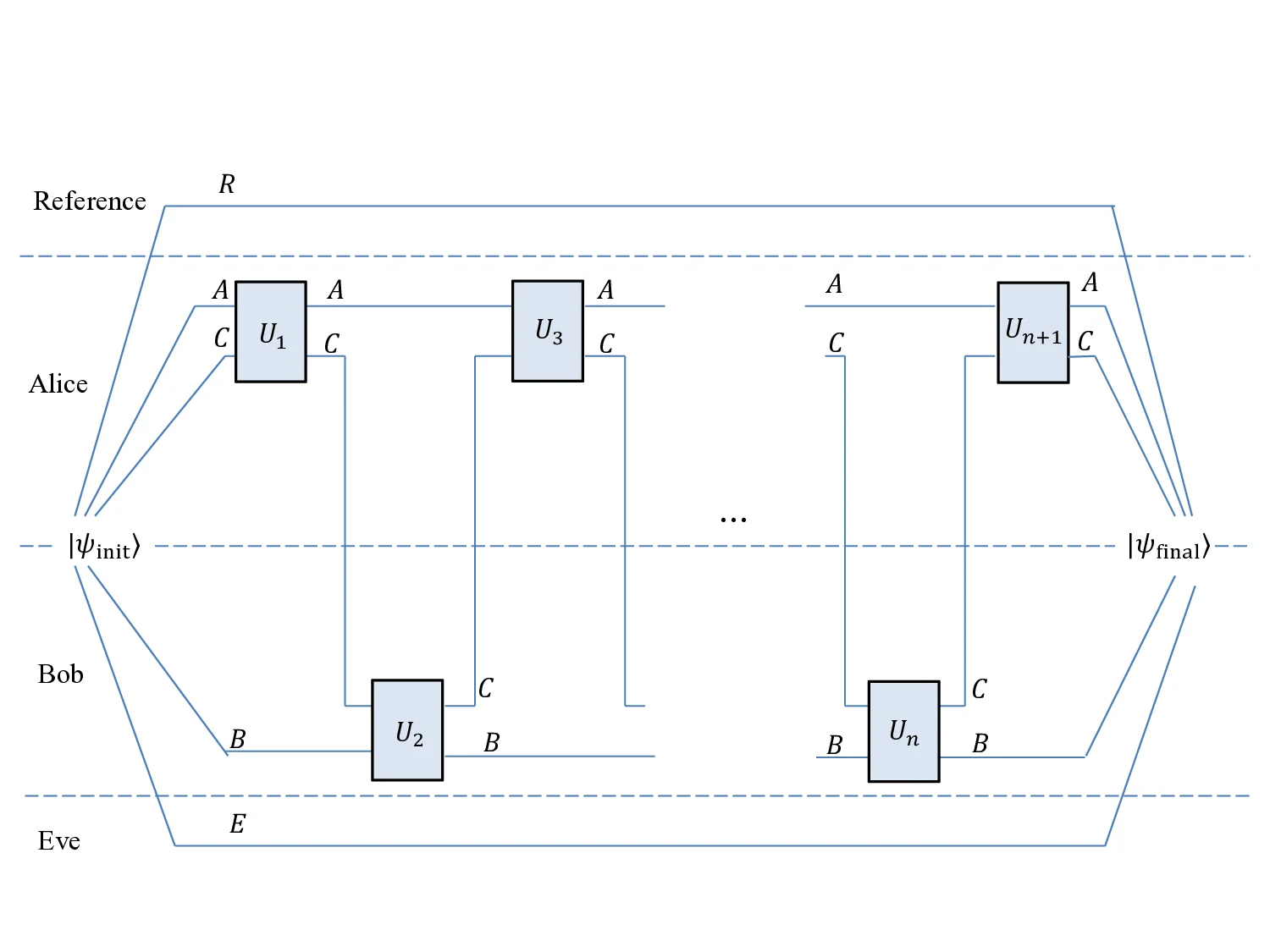
이 연구는 양자 인터랙티브 통신에서 “대용량 알파벳”을 활용해 잡음에 강인한 부호화 체계를 설계한다는 점에서 혁신적이다. 기존의 양자 오류 정정 코드는 각 메시지를 독립적으로 인코딩하면 전체 프로토콜이 한 번의 오류에도 붕괴되는 문제를 안고 있었다. 저자들은 이러한 문제를 해결하기 위해 메시지들을 동적으로 결합하고, 전체 라운드에 걸쳐 일관된 오류 검출·수정 메커니즘을 도입한다. 핵심 아이디어는 (1) 텔레포테이션 기반 프로토콜을 대용량 고전 채널 위에 구현하고, (2) “out‑of‑sync 텔레포테이션” 현상을 정밀히 분석해 오류 누적을 방지하는 것이다. 이를 위해 두 단계의 레지스터 표현을 도입하고, 각 단계에서 발생할 수 있는 위상 오류와 파울리 오류를 해시와 의사난수 생성기를 이용해 효율적으로 추적한다. 또한, 얽힘 재활용과 양자 베르남 암호(QVC)를 결합한 두 번째 프로토콜을 제시해, 순수 텔레포테이션이 적용되지 못하는 상황에서도 동일한 오버헤드와 성공 확률을 유지한다.
복잡도 측면에서 저자들은 사전 공유된 랜덤성이나 얽힘이 전혀 필요 없는 모델을 채택했으며, 모든 연산은 다항 시간 내에 수행 가능하도록 설계되었다. 오류 허용 비율 (\epsilon)에 대해 전체 채널 사용량은 원래 프로토콜 대비 (1+Θ(\sqrt{\epsilon})) 배만 증가하므로, (\epsilon\to0) 일 때 용량에 거의 도달한다. 이는 기존 Brassard 등(FOCS’14)의 비명시적 상수 오버헤드와 비교해 실질적인 개선이며, 특히 저노이즈(예: (\epsilon<10^{-3})) 환경에서 최적에 근접한다는 점이 강조된다. 저자들은 또한 (\sqrt{\epsilon}) 항의 상수를 최적화하는 것이 현재 한계이며, 이를 개선하면 상수 팩터 수준에서 최적성을 달성할 수 있다고 conjecture한다.
댓글 및 학술 토론
Loading comments...
의견 남기기