실시간 인터랙티브 딥러닝 학습 분석 시스템
본 논문은 딥러닝 모델 학습 중에 발생하는 다양한 이벤트를 실시간 스트림으로 변환하고, 사용자가 동적으로 정의한 map‑reduce 쿼리를 통해 즉시 시각화·분석할 수 있는 오픈소스 시스템 TensorWatch를 제안한다. 기존 로그 기반 모니터링 도구와 달리 학습을 중단하지 않고도 새로운 정보를 요청하고, 여러 시각화를 동시에 표시하며, 스트림을 저장·재사용할 수 있다.
저자: Shital Shah, Rol, Fern
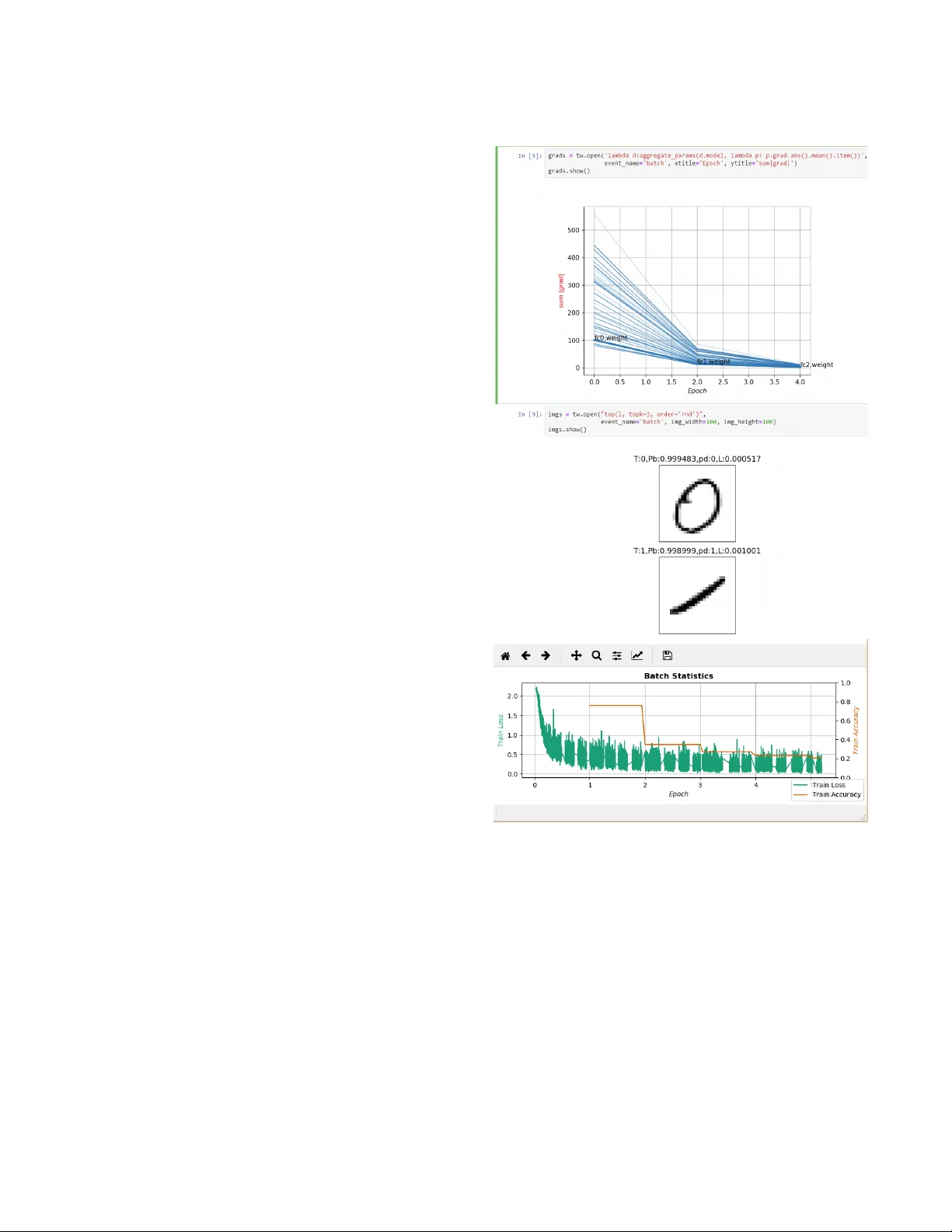
본 논문은 딥러닝 모델 학습 과정에서 발생하는 다양한 이벤트를 실시간으로 스트림화하고, 사용자가 동적으로 정의한 map‑reduce 쿼리를 통해 즉시 분석·시각화할 수 있는 시스템을 설계·구현하였다. 연구 배경으로는 현재 널리 사용되는 TensorBoard, Visdom, VisualDL 등은 학습 시작 전에 로그 항목을 미리 지정해야 하며, 새로운 정보를 얻기 위해서는 학습을 중단하고 로그 코드를 추가·재시작하는 ‘stop‑change‑restart’ 사이클이 필수적이라는 점을 지적한다. 이러한 제한은 특히 모델 디버깅, 그래디언트 흐름 분석, 하이퍼파라미터 튜닝 등 반복적인 탐색 작업에 큰 비용을 초래한다.
**시스템 아키텍처**는 세 가지 핵심 구성요소로 이루어진다. 첫째, **Long‑Running Process (P)** 로, 딥러닝 학습 루프 자체이며 배치 완료, 에포크 종료 등 다양한 이벤트와 해당 시점의 관측값(예: 손실, 정확도, 그래디언트 통계)을 생성한다. 둘째, **Agent (A)** 로, P 내부에 삽입된 경량 모듈이며 클라이언트로부터 들어오는 스트림 생성 요청을 비동기적으로 수신하고, 이벤트가 발생할 때마다 활성화된 스트림에 대해 map‑reduce 연산을 수행한다. 에이전트는 요청이 없을 경우 거의 무부하이며, 관측값을 미리 모두 노출해 두어 클라이언트가 필요에 따라 부분 집합을 선택하도록 설계되었다. 셋째, **Client** 로, 사용자는 Jupyter Notebook, CLI, 혹은 별도 GUI에서 map‑reduce 사양을 작성하고, 결과 스트림을 시각화 엔진이나 다른 파이프라인에 연결한다. 클라이언트는 하나의 스트림을 다중 시각화·처리 대상으로 라우팅할 수 있어, 같은 데이터에 대해 라인 차트, 히스토그램, 샘플 이미지 등 다양한 형태를 동시에 볼 수 있다.
**Map‑Reduce DSL** 은 데이터 과학자들이 익숙한 함수형 프로그래밍 패턴을 그대로 적용한다. `map` 연산은 각 이벤트의 관측값을 변환하거나 필터링하고, `reduce` 연산은 지정된 윈도우(예: 에포크 단위) 내에서 집계값을 생성한다. 기존 reduce는 전체 스트림이 끝날 때까지 결과를 내보내지만, 저자들은 각 스트림 값에 바이너리 플래그 B를 부착해 B가 true가 되는 시점에 즉시 집계 결과를 출력하도록 확장하였다. 이를 통해 에포크마다 평균 배치 시간, 레이어별 그래디언트 평균 등 중간 집계값을 실시간 스트림으로 제공한다.
**시각화 레이어**는 두 가지 주요 개념을 도입한다. 첫째, **Adaptive Visualizer** 로, 스트림의 데이터 타입(숫자, 문자열, 튜플 등)을 자동으로 인식해 적절한 차트 유형을 선택한다. 예를 들어, (x, y) 튜플이면 2D 라인 차트, (x, y, z) 튜플이면 3D 라인 차트, (x, y, label) 형태이면 라벨이 포함된 2D 차트로 자동 매핑한다. 사용자는 명시적으로 차트 유형을 오버라이드할 수도 있다. 둘째, **Frame‑Based Animated Visualization** 으로, 스트림의 각 값이 하나의 프레임을 구성하도록 하여 애니메이션 형태의 시각화를 지원한다. 이는 레이어별 그래디언트 변화, 예측 샘플을 손실값 순으로 정렬해 보여주는 동적 이미지 그리드 등, 학습 진행 상황을 직관적으로 파악하는 데 유용하다.
**관련 연구와 차별점**을 정리하면, 기존 도구들은 사전 정의된 로그만을 읽어 모니터링하므로 새로운 정보를 얻기 위해 학습을 중단하고 로그를 추가·재시작해야 한다. 반면 TensorWatch는 동적 스트림 생성과 실시간 쿼리를 기본 설계에 포함시켜, 사용자가 학습 도중 언제든지 새로운 관측값을 요청하고 즉시 결과를 확인할 수 있다. 또한 스트림 영속성(persistence) 기능을 통해 필요할 때만 디스크에 저장함으로써 로그 기반 시스템의 I/O 병목을 회피한다.
**실제 적용 시나리오**는 네 가지 예시로 제시된다. 1) **학습 손실·정확도 모니터링** – 배치마다 손실과 정확도를 실시간 라인 차트로 확인하고, 이상 징후가 보이면 즉시 그래디언트 흐름을 추가 조회한다. 2) **그래디언트 흐름 진단** – 손실 감소가 멈출 경우, 그래디언트 흐름 차트를 동적으로 요청해 vanishing/exploding 문제를 파악한다. 3) **하이퍼파라미터 실시간 튜닝** – 클라이언트에서 새로운 하이퍼파라미터 값을 에이전트에 전달해 학습 중에 즉시 적용한다. 4) **클라우드 비용 절감** – 다수의 장시간 학습 작업을 모니터링하면서 성능 지표가 일정 기준 이하인 작업을 조기에 종료한다.
**결론**적으로, 저자들은 시스템 설계가 **프로그래머블, 확장 가능, 저오버헤드**라는 세 가지 목표를 충족함을 강조한다. map‑reduce 기반 DSL은 데이터 과학자에게 친숙하고, 에이전트와 클라이언트 구조는 학습 프로세스에 거의 영향을 주지 않으며, 다양한 시각화와 스트림 영속성 옵션은 실험 재현성과 비용 효율성을 동시에 제공한다. 오픈소스 구현인 TensorWatch는 GitHub에 공개되어 있어, 연구자와 엔지니어가 손쉽게 도입·확장할 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기