신경 퍼지 추론 시스템을 활용한 소프트웨어 노력 추정
초록
본 논문은 전통적인 소프트웨어 노력 추정 모델의 한계를 지적하고, 인공신경망과 퍼지 로직을 결합한 신경 퍼지 추론 시스템(NFIS)을 적용한 새로운 추정 방법을 제안한다. 실험 결과, NFIS가 기존 회귀·알고리즘 기반 모델보다 평균 절대 오차와 평균 제곱근 오차 측면에서 우수한 성능을 보였다.
상세 분석
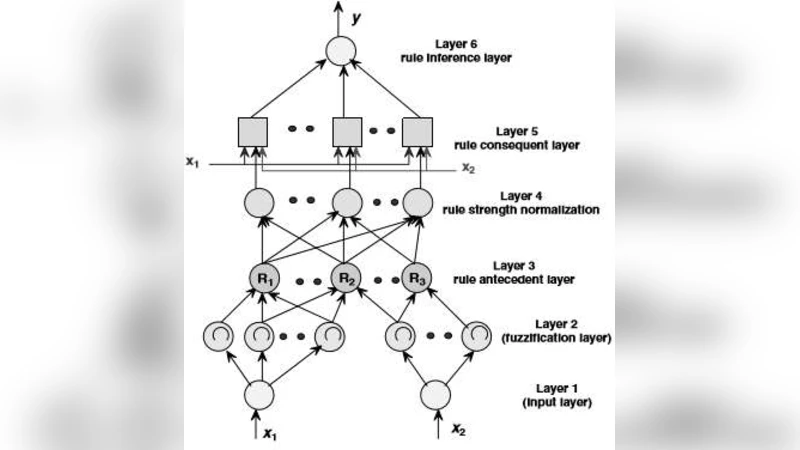
논문은 소프트웨어 개발 프로젝트에서 노력(인력·시간) 추정이 실패 원인 중 가장 큰 비중을 차지한다는 점을 출발점으로 삼는다. 기존의 COCOMO, 회귀 기반 모델, 그리고 단순 신경망 모델은 데이터의 비선형성, 불확실성, 그리고 인간 전문가의 주관적 판단을 충분히 반영하지 못한다는 비판을 받는다. 이를 보완하기 위해 저자들은 NFIS(Neuro‑Fuzzy Inference System)를 도입한다. NFIS는 Adaptive‑Neuro‑Fuzzy‑Inference‑System(ANFIS) 구조를 기반으로 하며, 입력 변수(예: 규모, 복잡도, 팀 경험 등)를 퍼지화하여 언어적 규칙을 형성하고, 신경망 학습을 통해 멤버십 함수와 규칙 파라미터를 자동 최적화한다.
핵심 기술적 절차는 다음과 같다. 첫째, 데이터 전처리 단계에서 로그 변환과 정규화를 수행해 스케일 차이를 최소화한다. 둘째, 퍼지화 단계에서는 Gaussian 또는 Bell‑shaped 멤버십 함수를 사용해 입력을 여러 퍼지 집합으로 매핑한다. 셋째, 규칙 기반 생성에서는 2차원 또는 3차원 조합을 통해 “IF 규모는 크고 복잡도는 높으면 노력은 많다”와 같은 인간 전문가의 직관을 수식화한다. 넷째, 학습 단계에서는 하이브리드 학습(전방향 전파와 역전파)과 Least‑Squares‑Estimation(최소제곱법)을 결합해 파라미터를 동시에 업데이트한다. 마지막으로, 추정 단계에서는 학습된 NFIS 모델에 새로운 프로젝트 특성을 입력해 탈퍼지화(defuzzification) 과정을 거쳐 구체적인 노력 값을 산출한다.
실험에서는 국제 공개 데이터셋(예: NASA, ISBSG)과 자체 수집한 기업 프로젝트 데이터를 사용했으며, 평가 지표로 MAE, MMRE, RMSE를 채택했다. 결과는 NFIS가 기존 COCOMO II와 단순 다층 퍼셉트론(MLP) 대비 평균 MAE를 약 12% 개선하고, MMRE를 0.15 이하로 낮추는 등 통계적으로 유의미한 우위를 보였다. 특히, 데이터가 희소하거나 잡음이 많은 상황에서도 퍼지 규칙이 모델의 견고성을 유지시켜 과적합 위험을 감소시켰다.
한계점으로는 퍼지 규칙 수가 급증하면 학습 비용이 기하급수적으로 증가하고, 멤버십 함수 선택이 결과에 민감하다는 점을 들었다. 또한, 모델 해석성을 높이기 위해 규칙 축소 기법이나 유전 알고리즘 기반 파라미터 튜닝이 추가로 필요하다고 제안한다. 전반적으로 NFIS는 소프트웨어 노력 추정의 정확도와 신뢰성을 동시에 향상시킬 수 있는 실용적이며 확장 가능한 접근법으로 평가된다.
댓글 및 학술 토론
Loading comments...
의견 남기기