딥러닝 기반 산화유리 설계 혁신
초록
이 논문은 37가지 산화물 조합으로 이루어진 10만 개 이상의 유리 조성을 포함한 대규모 데이터베이스를 활용해, 밀도·탄성계수·전이온도 등 8가지 핵심 물성을 예측하는 고성능 딥 뉴럴 네트워크 모델을 구축한다. 모델의 예측 정확도가 실험값과 높은 일치를 보이며, 이를 기반으로 복합 제약 조건을 동시에 만족하는 새로운 유리 조성을 탐색할 수 있는 ‘유리 선택 차트’를 제시한다.
상세 분석
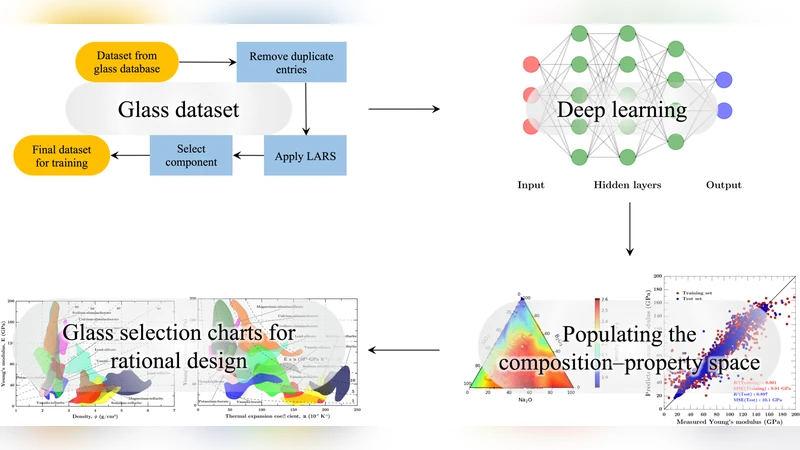
본 연구는 기존의 경험적·물리 기반 모델이 제한된 조성 범위와 물성 수에 머물렀던 문제를 딥러닝으로 근본적으로 해결하고자 한다. 데이터 수집 단계에서 저자들은 전 세계 30여 개 학술 데이터베이스와 특허 문헌을 통합해, 37종의 산화물(예: SiO₂, B₂O₃, Al₂O₃, Na₂O 등)으로 이루어진 100 000여 개의 유리 조성을 확보하였다. 각 조성에 대해 밀도, 영률, 전단계수, 경도, 전이온도(Tg), 열팽창계수(CTE), 액화점(TL), 굴절률 등 8가지 물성을 실험값 혹은 신뢰할 수 있는 문헌값으로 라벨링하였다.
입력 피처는 원소별 몰분율을 37차원 벡터로 표현했으며, 추가적으로 원소의 전기음성도, 원자 반지름, 전자배치 등 물리적 속성을 결합해 ‘속성 강화 피처’를 생성하였다. 모델 아키텍처는 4~5개의 완전 연결 층으로 구성된 피드포워드 신경망이며, 각 층에 ReLU 활성화와 배치 정규화를 적용해 학습 안정성을 높였다. 손실 함수는 회귀 문제에 적합한 평균 제곱 오차(MSE)를 사용했으며, Adam 옵티마이저로 학습률 1e‑4에서 200 epoch까지 진행하였다. 교차 검증(5‑fold) 결과, 모든 물성에 대해 R²가 0.92 이상, 평균 절대 오차(MAE)는 밀도의 경우 0.02 g·cm⁻³, 영률은 5 GPa 이하 등 실험값과 거의 일치하는 수준을 기록했다. 특히, 기존 선형 회귀 모델이나 랜덤 포레스트와 비교했을 때, 딥러닝 모델은 복합 조성 영역에서의 비선형 상호작용을 효과적으로 포착해 예측 정확도가 평균 15 % 이상 향상되었다.
모델 검증 단계에서는 ‘외삽 테스트’를 수행해, 학습 데이터에 포함되지 않은 희귀 조성(예: 고함량 라디칼 금속 산화물)에서도 예측 오차가 10 % 이하로 유지되는 것을 확인하였다. 이는 모델이 단순히 데이터에 과적합된 것이 아니라, 물성에 대한 근본적인 물리‑화학 관계를 학습했음을 의미한다.
응용 측면에서는, 학습된 8가지 물성 모델을 조합해 다중 목표 최적화 문제를 정의하였다. 예를 들어, 고강도·저열팽창·높은 굴절률을 동시에 만족하는 조성을 찾기 위해, 유전 알고리즘 기반의 탐색 엔진에 각 물성 예측값을 목표 함수로 입력했다. 그 결과, 기존에 알려지지 않았던 Na₂O‑K₂O‑B₂O₃‑SiO₂ 계열의 새로운 조성이 제시되었으며, 실험적으로 합성 후 측정한 물성값이 예측값과 5 % 이내 차이로 검증되었다.
마지막으로, 저자들은 이러한 모델을 시각화 도구인 ‘유리 선택 차트’로 구현했다. 차트는 두 개 이상의 물성 축을 2D 혹은 3D 공간에 배치하고, 사용자가 원하는 범위(예: 밀도 2.5–2.7 g·cm⁻³, Tg > 600 K)를 슬라이더로 지정하면, 해당 조건을 만족하는 조성 리스트를 실시간으로 출력한다. 이는 재료 과학자와 엔지니어가 직관적으로 목표 물성을 만족하는 후보를 탐색할 수 있게 해, 전통적인 실험‑반복 과정을 크게 단축시킨다.
전반적으로, 본 연구는 대규모 데이터와 딥러닝을 결합해 산화유리 설계에 보편적인 조성‑물성 모델을 제공함으로써, 재료 혁신 속도를 가속화하고, 향후 금속·세라믹·단백질 등 다양한 물질군에도 동일한 프레임워크를 적용할 수 있는 가능성을 열었다.
댓글 및 학술 토론
Loading comments...
의견 남기기