바이오메디컬 논문 저자 역할 자동 추출 시스템 “NaïveRole”
초록
본 논문은 PubMed Central에 수록된 2,000개의 저자 기여 섹션을 대상으로 공동 군집화와 Open IE 기법으로 주요 역할을 자동 탐색하고, 이를 기반으로 학습 데이터를 자동 생성한 뒤 Naïve Bayes 기반 모델인 NaïveRole을 제안한다. 실험 결과 마이크로 평균 정밀도 0.68, 재현율 0.48, F1 점수 0.57을 달성했으며, 이는 저자 역할을 구조화된 형태로 추출한 최초 사례로 평가된다.
상세 분석
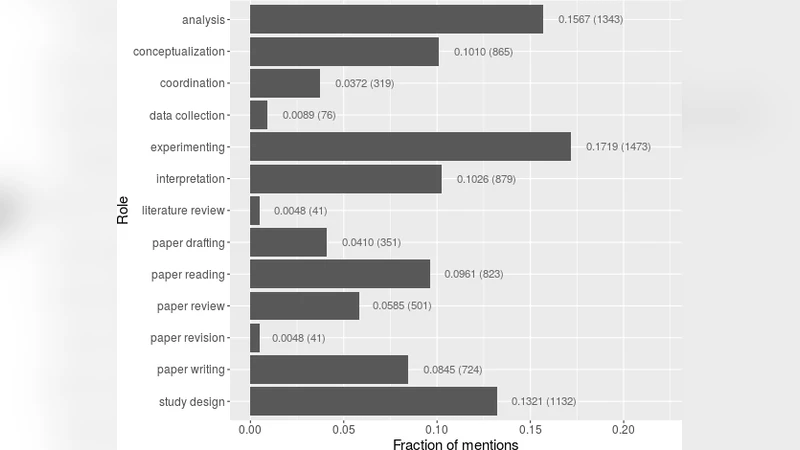
본 연구는 저자 기여 섹션이 자연어 형태로 기술되는 현상을 정량적·정성적으로 분석하고, 이를 기계학습 기반 자동 추출 파이프라인으로 전환하는 데 초점을 맞추었다. 먼저 2,000개의 기여 섹션을 수집한 뒤, 텍스트를 토큰화하고 동시 출현 행렬을 구축하여 비음수 행렬 분해(NMF) 기반 공동 군집화를 수행하였다. 이 과정에서 “데이터 수집”, “실험 설계”, “통계 분석”, “원고 작성” 등 30여 개의 대표 역할 클러스터가 도출되었다. 동시에 Open Information Extraction(OIE) 도구를 적용해 주어‑동사‑목적어 삼중항을 추출하고, 빈도 기반 필터링을 통해 역할 후보 문구를 정제하였다. 이렇게 자동으로 확보된 역할 레이블은 인간 검증 없이도 충분히 일관성을 보였으며, 이후 학습 데이터 라벨링에 활용되었다.
NaïveRole 모델은 전통적인 Naïve Bayes 분류기를 기반으로 하며, 입력 피처는 (1) 역할 후보 문구의 n‑gram TF‑IDF, (2) 저자 이름과 역할 문구 사이의 거리 및 위치 정보, (3) OIE에서 추출된 논리적 관계(예: “X performed Y”)를 이진 특성으로 포함한다. Naïve Bayes는 독립 가정 하에 각 피처의 조건부 확률을 추정해 가장 높은 사후 확률을 갖는 역할 라벨을 할당한다. 모델 학습은 자동 라벨링된 데이터셋(약 8,000개의 역할‑저자 쌍)으로 수행되었으며, 교차 검증을 통해 과적합을 방지하였다.
평가에서는 마이크로 평균 기준 정밀도 0.68, 재현율 0.48, F1 0.57을 기록했는데, 이는 역할 명칭이 다소 다양하고 문맥에 따라 의미가 변하는 점이 성능 저하의 주요 원인으로 분석된다. 오류 사례를 살펴보면, “drafted the manuscript”와 “wrote the manuscript”를 구분하지 못하거나, 복합 역할(예: “designed experiments and analyzed data”)을 단일 라벨로 축소하는 문제가 있었다. 이러한 한계는 보다 정교한 시퀀스 라벨링 모델이나 BERT 기반 컨텍스트 인코더 도입으로 개선될 여지가 있다.
전체적으로 본 연구는 (1) 대규모 비정형 저자 기여 텍스트에서 역할을 자동 탐색하는 방법론, (2) 자동 라벨링을 통한 학습 데이터 구축 전략, (3) 경량화된 Naïve Bayes 모델을 활용한 실용적인 역할 추출 시스템을 제시함으로써, 학술 메타데이터의 풍부화와 연구 평가 지표 개발에 기여한다는 점에서 의의가 크다.
댓글 및 학술 토론
Loading comments...
의견 남기기