스프레드시트 오류 유형과 해결 방안 종합 리뷰
초록
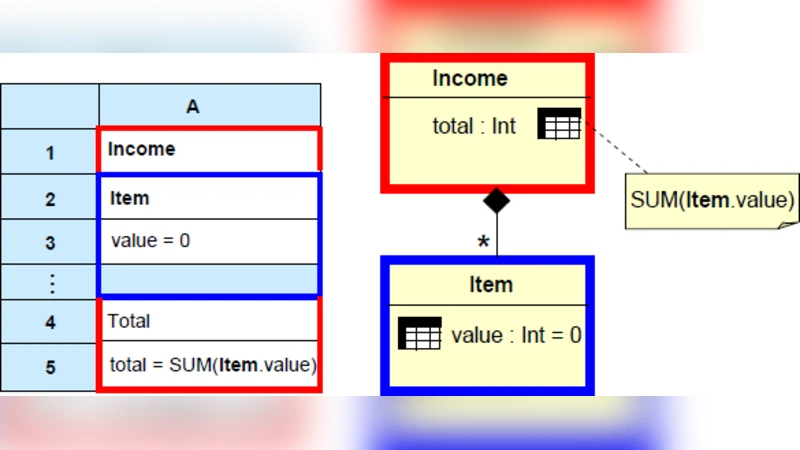
스프레드시트는 업무 전반에 걸쳐 널리 활용되지만 오류 발생률이 높아 다양한 연구가 오류 예방·탐지·수정 도구를 제시한다. 본 논문은 최신 연구들을 오류 정의, 탐지 메커니즘, 지원 가능한 오류 종류별로 분류·정리하고, 사용자가 흔히 저지르는 실수를 조명한다.
상세 분석
본 논문은 스프레드시트 오류 연구의 전반을 체계적으로 정리함으로써 두드러진 학술적·실무적 통찰을 제공한다. 첫째, 오류를 ‘기계적 오류’, ‘논리적 오류’, ‘데이터 입력 오류’, ‘범위/참조 오류’, ‘수식 복제 오류’ 등으로 구분하는 기존 분류 체계를 재검토하고, 각 범주의 발생 원인과 파급 효과를 구체적으로 제시한다. 특히, 기계적 오류는 셀 서식이나 복사‑붙여넣기 과정에서 발생하는 단순 실수이며, 논리적 오류는 복잡한 수식이나 조건부 로직에서 발생하는 설계상의 결함을 의미한다. 둘째, 오류 탐지 접근법을 정적 분석, 동적 테스트, 시각화 기반 감사, 머신러닝 기반 예측 네트워크 등 네 가지 축으로 나눈다. 정적 분석 도구는 셀 의존성 그래프와 데이터 흐름을 분석해 순환 참조나 비정상적인 상수 사용을 자동으로 식별한다. 동적 테스트는 입력값 변동에 따른 결과 변화를 모니터링해 경계값 초과나 비정상적인 출력 패턴을 포착한다. 시각화 기반 감사는 색상‑히트맵, 흐름 차트, 트리맵 등을 활용해 사용자가 직관적으로 위험 영역을 인식하도록 돕는다. 머신러닝 기반 접근법은 대규모 오류 라벨링 데이터셋을 학습해 비정형 오류 패턴을 예측하고, 이상치 점수를 부여한다. 셋째, 오류 예방 메커니즘으로는 템플릿 기반 설계, 데이터 검증 규칙, 사용자 교육 프로그램을 강조한다. 템플릿은 표준화된 구조와 사전 정의된 수식을 제공해 설계 단계부터 오류 가능성을 최소화한다. 데이터 검증 규칙은 입력 제한, 드롭다운 목록, 정규식 검증 등을 통해 입력 단계에서 오류를 차단한다. 넷째, 오류 수정 기법은 자동 교정, 제안 기반 수정, 버전 관리와 롤백 메커니즘을 포함한다. 자동 교정은 일반적인 오타나 잘못된 셀 참조를 자동으로 교정하고, 제안 기반 수정은 사용자가 선택할 수 있는 여러 후보 수식을 제시한다. 버전 관리 시스템은 변경 이력을 추적해 오류 발생 시 신속히 이전 안정 버전으로 복구할 수 있게 한다. 마지막으로, 논문은 현재 도구들의 한계—예를 들어, 복잡한 매크로와 사용자 정의 함수에 대한 탐지 정확도 저하, 대규모 스프레드시트에서의 성능 병목, 그리고 사용자 수용성 부족—을 지적하고, 향후 연구 방향으로 통합형 오류 관리 프레임워크와 인간‑컴퓨터 상호작용 기반 오류 인식 인터페이스 개발을 제안한다. 전체적으로 본 리뷰는 스프레드시트 오류 연구의 전반적인 흐름을 파악하고, 실무 적용 시 고려해야 할 핵심 요소들을 명확히 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기