대규모 학술 어휘 사전 LScDC: 170만 초록 기반 새로운 의미 정량화 도구
초록
본 논문은 2014년 발표된 1,673,824편의 영문 초록을 모아 만든 Leicester Scientific Corpus(LSC)를 소개하고, 이 코퍼스에서 추출한 974,238개의 어휘(lemmas)로 구성된 Leicester Scientific Dictionary(LScD)와, 등장 빈도가 10건 이상인 104,223개의 핵심 어휘로 구성된 LScDC를 제시한다. 두 사전을 기존 학술 어휘 리스트인 New Academic Word List(NAWL)와 비교하여 99.6%의 겹침을 보였으나 순위는 차이를 보였다.
상세 분석
이 연구는 학술 텍스트 의미를 정량화하기 위한 기반 자료 구축을 목표로 한다. 먼저 Web of Science에서 2014년 출판된 논문 초록 1,673,824건을 수집해 252개 주제 카테고리와 인용 횟수 메타데이터를 부착한 LSC를 만든다. 텍스트 전처리 단계에서는 형태소 분석을 통해 어간(stemming) 처리하고, 일반적인 불용어(stop‑words)를 제거하였다. 이렇게 정제된 토큰 집합에서 중복을 없앤 974,238개의 고유 lemmas를 LScD에 수록했으며, 각 어휘가 등장한 문서 수와 전체 토큰 빈도를 함께 제공한다.
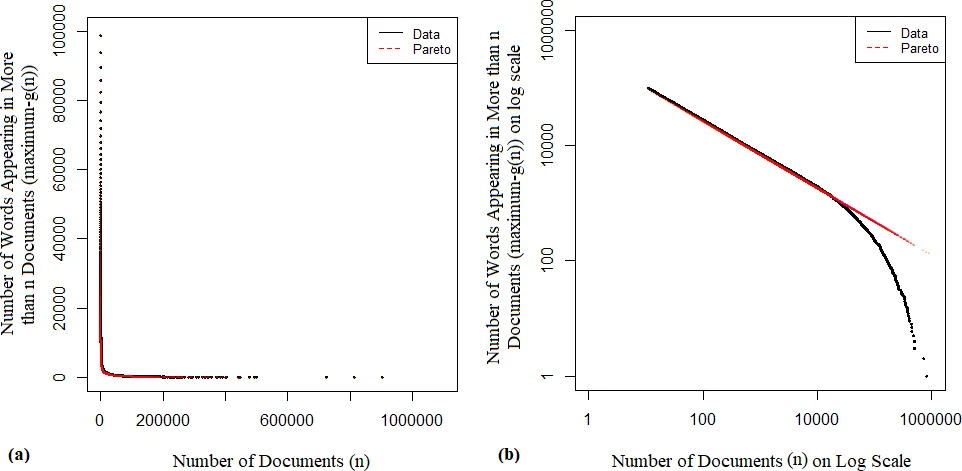
핵심 사전 LScDC는 ‘희소 어휘는 의미 정보 제공에 기여도가 낮다’는 가정 하에, LScD에서 10문서 이하에 등장한 어휘를 제외해 104,223개의 어휘만 남겼다. 이 기준은 전체 어휘의 약 60%가 한 문서에만 등장한다는 관찰에 기반한다. 결과적으로 LScDC는 보다 안정적인 빈도 통계와 의미 점수 계산에 적합한 어휘 집합을 제공한다.
비교 분석에서는 NAWL(963개 어휘군, 288백만 토큰 기반)과 LScDC를 대조하였다. NAWL을 어간화(stemming)한 후 895개의 고유 lemmas가 남았으며, 이 중 891개가 LScDC에 포함돼 99.6%의 커버리지를 보였다. 그러나 두 리스트는 빈도 기반 순위가 크게 달라, 학술 분야별 특수 용어와 일반 어휘의 비중 차이가 원인으로 제시된다. NAWL은 일반·구어·교과서 텍스트를 혼합한 코퍼스에서 추출된 반면, LScDC는 순수 학술 초록에서 도출돼 과학·공학 분야의 전문 용어가 풍부하다.
이 논문의 주요 강점은 방대한 멀티디시플리너리 코퍼스를 기반으로 어휘를 체계화했으며, 희소 어휘 제거 기준을 명시적으로 제시해 재현 가능성을 높였다는 점이다. 다만, 2014년 한 해에 국한된 데이터와 WoS 색인 논문에만 초점을 맞춘 점은 최신 연구 동향이나 비영어권 학술어휘를 반영하지 못한다는 제한이 있다. 또한 어간화 과정에서 의미가 손실될 가능성도 존재한다. 향후에는 연도 확대, 다중 데이터베이스 통합, 의미‑네트워크 분석 등을 통해 사전의 포괄성과 활용성을 강화할 여지가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기