혼합음원 ECoG 신호를 이용한 신경음소 인식
초록
본 논문은 인간이 복수의 말소리를 동시에 들을 때 한 음원에 집중하고 방해 음원을 억제하는 능력을, 전두엽 피질 위에 부착된 고밀도 ECoG 전극으로 측정한 신경신호를 이용해 신경음소 인식(NSR) 시스템으로 정량화한다. 기존 연구보다 수동 전사 기반 초기화와 침묵 삽입을 통한 정렬 불일치 보정을 적용해 ASR 대비 NSR의 혼합음원 상황에서의 성능 저하를 크게 줄였다. 실험 결과, 단일 화자에서는 ASR이 우수했지만, 혼합 화자에서는 NSR의 전화 오류율(PER) 상승폭이 12%에 불과해 인간 청취자의 강인성을 객관적으로 입증하였다.
상세 분석
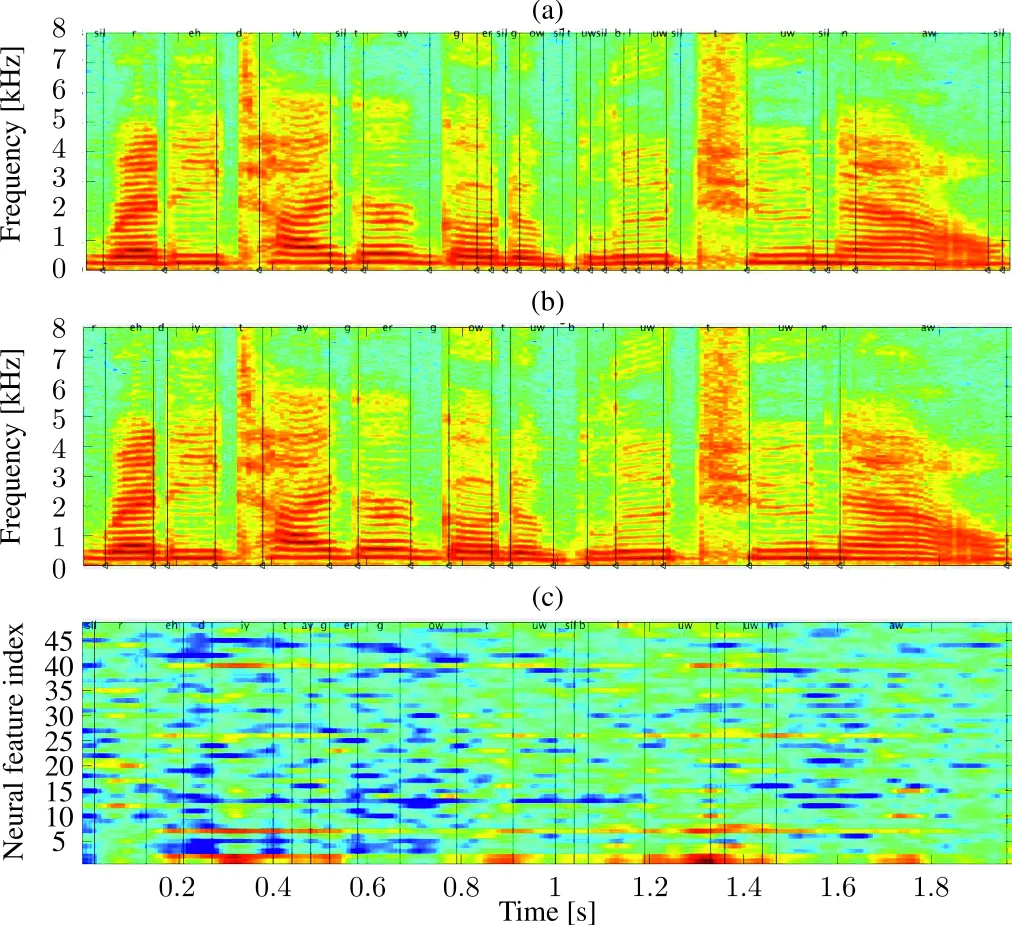
이 연구는 신경음성 인식(NSR)이라는 비교적 새로운 패러다임을 기존 자동음성인식(ASR)과 직접 비교함으로써 인간 청취의 잡음 강인성을 정량화하려는 시도이다. 주요 기여는 세 가지로 요약할 수 있다. 첫째, 초기 모델 파라미터를 평탄 시작(flat start) 대신 수동 전사된 CRM 데이터로 초기화함으로써 ASR와 그 파생 NSR의 기본 정렬 정확도를 크게 향상시켰다. 이는 특히 훈련 데이터가 제한적인 상황에서 모델 수렴 속도와 최종 PER에 결정적인 영향을 미친다. 둘째, 신경 신호와 음성 신호 사이에 존재할 수 있는 침묵 위치 불일치를 고려하여, 모든 음소 뒤에 선택적 침묵을 삽입하고 0.9의 침묵 스킵 확률을 부여한 새로운 라티스 구조를 도입했다. 이 설계는 신경 신호가 음성보다 짧은 지속시간을 가질 때 발생하는 정렬 오류를 완화시켜, 신경 기반 음소 모델의 학습을 방해하지 않는다. 셋째, 고밀도 16×16 ECoG 전극 배열을 이용해 후두상측두회(pSTG)에서 고감마 대역(70–160 Hz) 신호를 추출하고, 공간 PCA·Varimax 회전·비음성 NMF·시간 미분까지 4단계의 차원 축소 및 특징 강화 파이프라인을 구축했다. 이 복합 전처리 과정은 신경 데이터의 잡음과 상관성을 효과적으로 억제하면서도 음소 구분에 필요한 스펙트로템포럴 정보를 보존한다. 실험 설계는 CRM과 TIMIT 두 코퍼스를 결합해 단일 화자와 혼합 화자(칵테일 파티) 상황을 모두 평가했으며, 8번의 몬테카를로 교차 검증을 통해 통계적 신뢰성을 확보했다. 결과적으로 ASR은 단일 화자에서 평균 PER 4.0% 수준이지만 혼합 화자에서는 54%로 급격히 악화되는 반면, NSR은 단일 화자에서 56% 수준이지만 혼합 화자에서도 60% 내외에 머물러 상대적 증가율이 12%에 불과했다. 이는 인간 청취자가 청각 피질에서 선택적 주의 메커니즘을 통해 방해 음원을 억제한다는 기존 신경생리학적 발견을 NSR 시스템을 통해 정량적으로 재현한 것이다. 또한, GMM/HMM 기반 NSR 정렬을 사용했을 때 DNN/HMM 기반 ASR 정렬 대비 PER가 4.5% 감소하는 등 정렬 전략의 중요성을 강조한다. 전반적으로 이 논문은 신경 기반 음소 인식 모델의 설계, 초기화, 정렬 보정 방법론을 체계적으로 제시하고, 인간 청취의 강인성을 객관적 지표로 측정하는 데 성공하였다. 향후 연구에서는 정렬 불일치의 보다 정교한 모델링과 다양한 청각 환경(예: 실시간 잡음, 다채널 스피커)에서의 일반화 가능성을 탐색할 여지가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기