SOT‑MRAM 기반 PIM 엔진을 위한 ADMM 기반 초고압축 DNN 설계
** 본 논문은 SOT‑MRAM 기반 처리‑인‑메모리(PIM) 구조의 고전력·고지연 문제를 해결하기 위해, ADMM을 활용한 구조적 가중치 프루닝과 저비트 양자화를 결합한 모델 압축 프레임워크를 제안한다. 압축된 모델을 하드웨어에 매핑함으로써 면적·전력 감소와 처리량 향상을 동시에 달성하고, 주요 벤치마크에서 정확도 손실을 최소화한다. **
저자: Geng Yuan, Xiaolong Ma, Sheng Lin
**
본 논문은 차세대 임베디드 및 IoT 시스템에 적합한 저전력 DNN 가속기를 구현하기 위해, 스핀‑오빗 토크(SOT) MRAM 기반 처리‑인‑메모리(PIM) 엔진과 ADMM(Alternating Direction Method of Multipliers) 기반 모델 압축 프레임워크를 결합한 새로운 설계 방식을 제안한다.
1. **배경 및 동기**
- 기존 CMOS 기반 DNN 가속기는 연산·데이터 이동량이 급증함에 따라 전력·면적 한계에 직면하고 있다.
- SOT‑MRAM은 비휘발성, 거의 제로 대기 전력, 높은 집적도라는 장점을 가지고 있어 메모리 중심 연산에 유리하지만, 쓰기 지연과 쓰기 에너지가 크다는 단점이 있다.
- 이러한 하드웨어 제약을 극복하기 위해서는 소프트웨어 레벨에서 가중치를 압축하고, 하드웨어에 맞는 구조적 희소성을 부여해야 한다.
2. **ADMM 기반 구조적 프루닝 및 양자화**
- DNN 가중치를 필터‑프루닝, 채널‑프루닝, 커널‑프루닝의 세 가지 구조적 형태로 제한한다. 각각은 제약 집합 Sᵢ 로 정의되며, 프루닝 비율(αᵢ, βᵢ, θᵢ) 을 하드웨어 자원(서브배열, PE)과 직접 매핑한다.
- 원본 최적화 문제 min f(W,b) s.t. Wᵢ∈Sᵢ 을 ADMM 형태로 변형한다. 보조 변수 Zᵢ와 라그랑주 승수 Uᵢ를 도입해 두 서브문제로 분할한다.
- **서브문제 1**: 기존 손실 함수에 정규화 항 ρᵢ‖Wᵢ−Zᵢ+Uᵢ‖² 을 추가한 형태로, SGD를 이용해 가중치를 업데이트한다.
- **서브문제 2**: Zᵢ 를 제약 집합 Sᵢ 에 투사한다. 투사 연산은 각 필터·채널·커널의 Frobenius norm을 계산하고, 상위 αᵢ, βᵢ, θᵢ 개만 남기고 나머지를 0으로 만든다. 이는 닫힌 형태 해를 갖기 때문에 연산 비용이 거의 없다.
- 양자화는 별도의 제약 집합을 정의해 동일한 ADMM 루프에 포함한다. 비트폭을 줄이면 SOT‑MRAM 서브배열의 행 수가 감소해 면적·전력 절감 효과가 직접적으로 나타난다.
3. **SOT‑MRAM PIM 엔진 아키텍처**
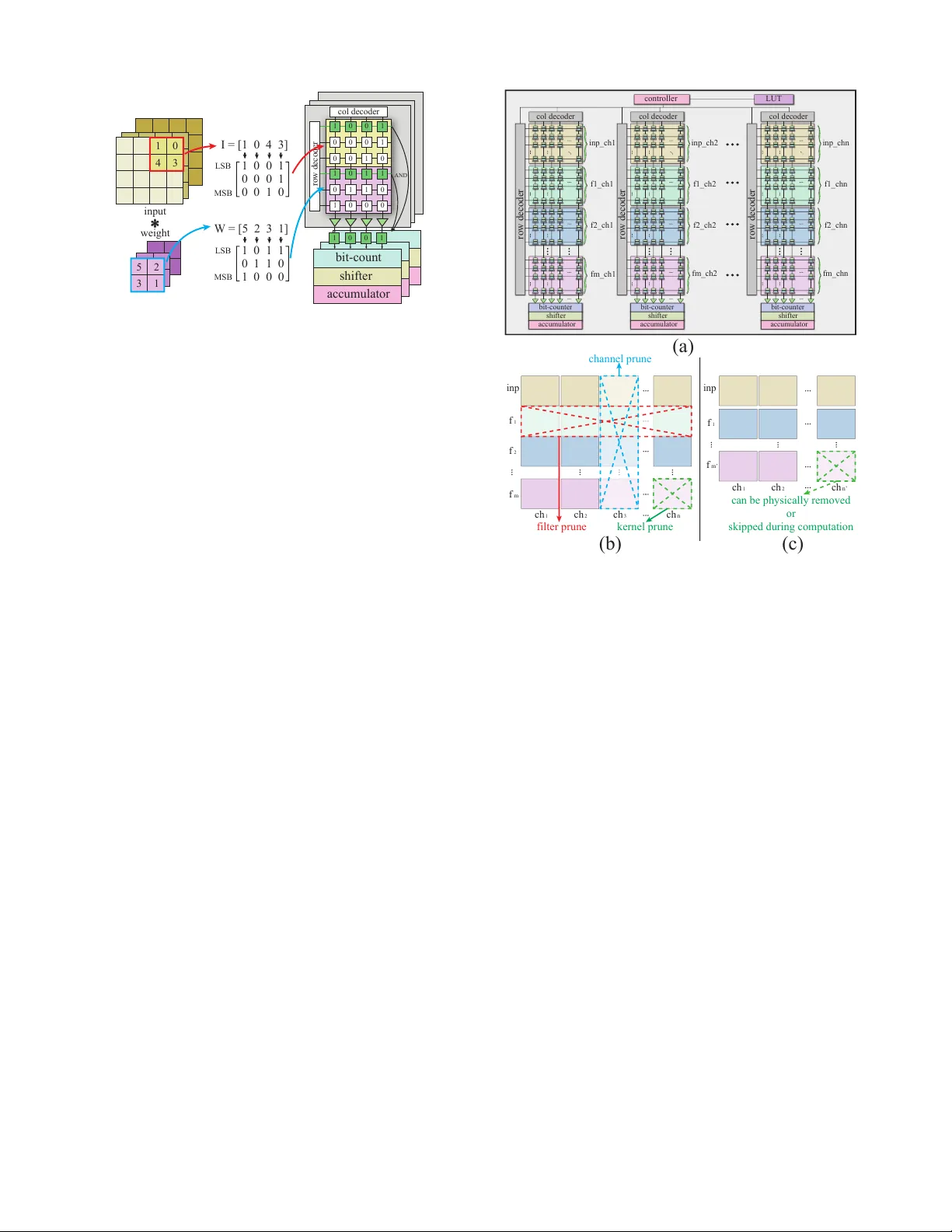
- 엔진은 다수의 PE(Processing Element) 로 구성된다. 각 PE는 입력 전용 서브배열과 여러 필터 가중치를 저장하는 서브배열들로 이루어진다.
- 비트‑와이즈 컨볼루션은 네 단계(AND → 비트‑카운트 → 시프트 → 누산)로 구현되며, 이는 SOT‑MRAM 셀의 병렬 읽기 특성을 활용한다.
- 구조적 프루닝이 적용되면:
- **필터 프루닝**: 동일 행에 위치한 서브배열 전체를 물리적으로 제거한다.
- **채널 프루닝**: 해당 채널을 담당하는 전체 PE 를 제거해 PE 수를 감소시킨다.
- **커널 프루닝**: 개별 서브배열을 비활성화하거나 LUT 로 마스킹해 연산에서 제외한다.
- 이러한 매핑은 제어 로직을 최소화하면서도, 하드웨어 자원을 효율적으로 재배치한다.
4. **실험 설정 및 결과**
- **소프트웨어**: LeNet‑5, AlexNet, VGG‑16, ResNet‑18/50 네트워크를 PyTorch 기반으로 8 GPU(RTX‑2080Ti)에서 학습. ADMM 파라미터 ρᵢ 와 프루닝 비율을 데이터셋 별 최적화.
- **하드웨어**: 32 nm CMOS 기술을 사용해 주변 회로를 설계, CACTI 로 버퍼·인터커넥트 면적·에너지 계산, NVSim 로 SOT‑MRAM 서브배열 모델링, ADC 전력은 기존 문헌값 사용.
- **압축 성능**:
- MNIST(LeNet‑5)에서 81.3× 압축, 정확도 99.12% (원본 99.15%).
- CIFAR‑10(ResNet‑18)에서 59.8× 압축, 정확도 93.2% (원본 93.3%).
- ImageNet(AlexNet)에서 5.2× 압축, Top‑1/Top‑5 정확도 57.4%/82.4% (원본 57.2%/82.2%).
- **하드웨어 효율**:
- 면적 평균 45% 감소, 전력 평균 70% 이상 절감.
- 처리량(throughput) 3~5배 향상, 이는 프루닝으로 인한 PE·서브배열 감소와 비트‑와이즈 연산 병렬화 덕분.
- **비교**: 기존 최첨단 프루닝·양자화 기법(예: Group Scissor, DCP, Network Slimming 등) 대비 압축 비율이 크게 높으며, 정확도 손실은 동일 수준 이하.
5. **시사점 및 향후 과제**
- ADMM 기반 구조적 프루닝은 하드웨어 제약을 직접 반영한 최적화 문제로 변환함으로써, 소프트웨어‑하드웨어 공동 설계(co‑design)의 효율성을 극대화한다.
- SOT‑MRAM의 쓰기 지연·에너지 문제를 소프트웨어 레벨에서 보완함으로써, 비휘발성 메모리 기반 PIM 가속기의 실용성을 크게 높인다.
- 향후 연구는 트랜스포머와 같은 비정형 모델에 대한 ADMM‑기반 압축 적용, 온‑칩 학습 시나리오에서의 동적 프루닝·양자화, 온도·노이즈 변동성을 고려한 견고한 매핑 기법 개발 등을 제안한다.
**
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기