시간 주파수 분할과 사운드 이벤트 검출을 위한 약한 라벨 학습 프레임워크
본 논문은 강한 라벨이 없는 음성 데이터만을 이용해 시간‑주파수(T‑F) 마스크를 학습하고, 이를 통해 사운드 이벤트 검출과 소리 분리를 동시에 수행하는 새로운 프레임워크를 제안한다. CNN 기반의 세그멘테이션 매핑과 전역 가중치 순위 풀링(GWRP) 기반의 분류 매핑을 결합해 약한 라벨만으로도 T‑F 마스크를 추정한다. DCASE 2018 데이터셋을 재조합한 실험에서 기존 모델을 크게 능가하는 F1 점수를 기록하였다.
저자: Qiuqiang Kong, Yong Xu, Iwona Sobieraj
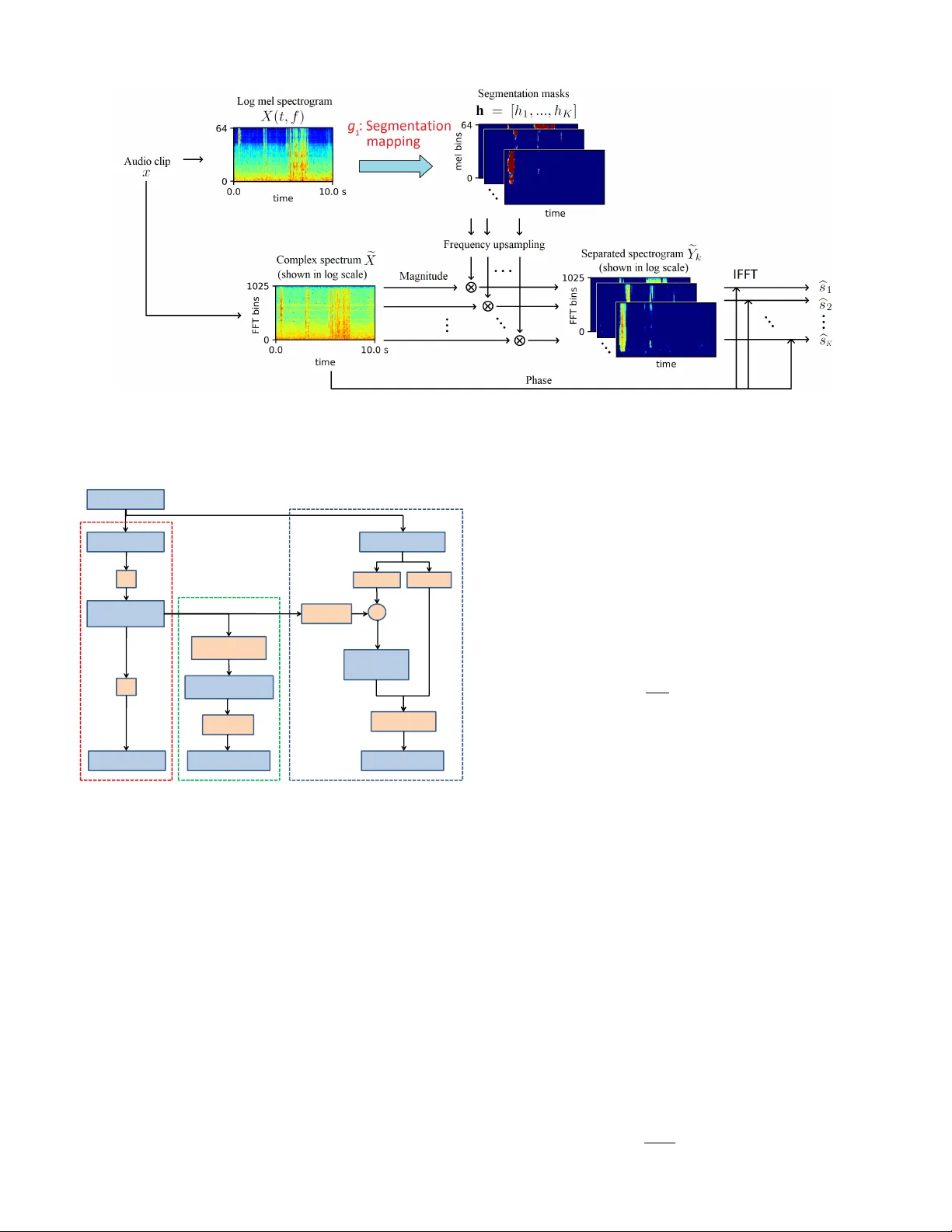
본 논문은 강한 라벨(시작·종료 시점)이 없는 약한 라벨 데이터만을 이용해 사운드 이벤트 검출(Sound Event Detection, SED)과 소리 분리(sound event separation)를 동시에 수행할 수 있는 새로운 프레임워크를 제안한다. 기존의 SED 연구는 대부분 강한 라벨이 포함된 데이터에 의존했으며, 라벨링 비용이 크게 요구되는 단점이 있었다. 반면, 최근 공개된 대규모 오디오 태깅 데이터셋은 클립 수준의 존재 여부만을 제공하는 약한 라벨 형태이므로, 이를 효과적으로 활용하는 방법이 필요했다.
제안된 시스템은 두 단계의 매핑으로 구성된다. 첫 번째 단계인 세그멘테이션 매핑(g₁)은 로그 멜 스펙트로그램과 같은 시간‑주파수(T‑F) 표현을 입력으로 받아, 각 클래스별 T‑F 마스크 hₖ(t,f)를 출력한다. 이 마스크는 이상적인 비율 마스크(IRM)와 유사하도록 시그모이드 활성화를 적용해 0~1 사이 값을 갖는다. 두 번째 단계인 분류 매핑(g₂)은 각 마스크에 전역 가중치 순위 풀링(Global Weighted Rank Pooling, GWRP)을 적용해 클래스 존재 확률 pₖ를 산출한다. GWRP는 마스크 내 모든 T‑F 유닛을 순위에 따라 가중합함으로써, 단순 max‑pooling이 초점이 되는 가장 강한 유닛만을 사용하고 나머지를 무시하는 문제를 완화한다.
학습 과정에서는 전체 손실을 이진 교차 엔트로피 형태로 정의하고, g₁과 g₂를 end‑to‑end 방식으로 동시에 최적화한다. 약한 라벨만으로도 마스크가 점진적으로 학습되며, 최종적으로는 (1) 마스크를 주파수 축으로 평균해 시간 도메인에서 프레임별 이벤트 스코어 vₖ(t)를 얻고, 이를 임계값 및 최소 지속 시간 기준으로 후처리해 이벤트의 시작·종료 시점을 추정한다. (2) 마스크를 원본 복소 스펙트럼에 곱해 역변환함으로써 각 이벤트의 파형을 분리한다. 따라서 약한 라벨만으로도 검출과 분리를 동시에 달성한다.
실험은 DCASE 2018 Task 1(배경 소리)과 Task 2(목표 이벤트)를 0 dB 신호대잡음비(SNR)로 혼합한 데이터셋을 사용하였다. 제안 모델은 Audio Tagging에서 F1 = 0.534, 프레임‑단위 SED에서 F1 = 0.398, 이벤트‑단위 SED에서 F1 = 0.167을 기록했으며, 이는 동일 조건의 Fully Connected DNN(0.331, 0.237, 0.120)보다 크게 향상된 결과이다. 특히 T‑F 세그멘테이션 자체에 대한 평가에서도 F1 = 0.218을 달성해, 기존 방법이 불가능했던 T‑F 마스크 추정에 성공하였다.
이 연구는 (1) 라벨링 비용이 낮은 약한 라벨 데이터만으로도 강력한 SED와 소리 분리를 구현할 수 있음을 증명하고, (2) GWRP 기반의 분류 매핑이 마스크 학습에 효과적임을 보여준다. 향후 연구에서는 중첩 이벤트, 다양한 SNR 환경, 그리고 어텐션 기반 풀링과의 비교 등을 통해 모델의 일반화 능력을 확장할 수 있을 것으로 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기