음향 분야를 혁신하는 머신러닝
초록
본 리뷰는 음향 데이터 분석에 머신러닝(특히 딥러닝)이 가져온 최근 혁신을 정리한다. 기존 물리 기반 모델과 대비해 데이터‑주도 방식의 장점과 한계를 논의하고, 음성 스피커 위치 추정, 해양 음원 탐지, 생물음향, 일상 소음 인식 등 네 가지 주요 연구 분야에서의 적용 사례와 향후 과제를 제시한다.
상세 분석
이 논문은 머신러닝(ML)이 전통적인 신호 처리와 물리 모델을 보완하거나 대체할 수 있는 가능성을 체계적으로 제시한다. 먼저 ML을 ‘입력‑출력 매핑을 학습하는 데이터‑주도 기법’으로 정의하고, 지도학습과 비지도학습, 그리고 강화학습(본 리뷰에서는 다루지 않음)으로 크게 구분한다. 지도학습에서는 라벨이 있는 데이터 쌍을 이용해 회귀·분류 모델을 학습하며, 선형 회귀, 서포트 벡터 머신, 신경망(특히 딥러닝) 등이 대표적이다. 비지도학습은 라벨이 없을 때 데이터 구조를 탐색하는데, 주성분 분석(PCA), K‑means, 가우시안 혼합 모델(GMM) 등 전통적 기법과 t‑SNE, 딥 오토인코더와 같은 최신 방법을 포함한다.
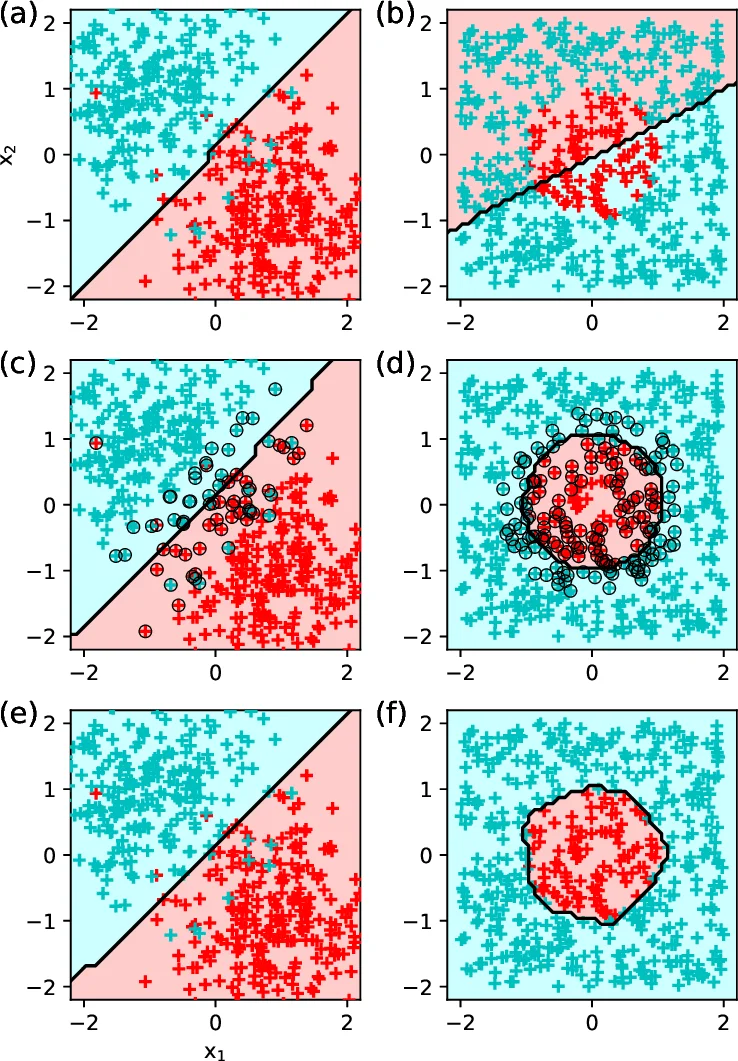
논문은 모델 일반화 능력에 대한 논의를 중심으로 ‘용량(capacity)’과 ‘복잡도(complexity)’ 개념을 도입한다. 모델 용량이 데이터 복잡도보다 낮으면 과소적합(under‑fitting)으로 성능이 제한되고, 반대로 용량이 과도하면 과적합(over‑fitting)으로 학습 데이터에만 특화된 모델이 된다. 이를 시각화한 Figure 2는 다항 회귀 예시를 통해 훈련·검증 오류가 어떻게 변하는지를 보여준다. 교차 검증과 별도의 검증·테스트 세트 활용이 일반화 성능을 평가하는 표준 절차로 제시된다.
딥러닝 파트에서는 다층 퍼셉트론, 컨볼루션 신경망(CNN), 순환 신경망(RNN) 등 구조적 특성을 설명하고, 대규모 라벨링 데이터가 확보될 경우 복잡한 음향 현상(예: 인간 음성, 방음 효과)을 직접 모델링할 수 있음을 강조한다. 그러나 ‘블랙박스’ 특성으로 인한 해석 가능성 부족과 데이터 요구량이 큰 점을 한계로 지적한다.
응용 분야는 네 가지로 구분된다. 1) 음성 처리에서의 스피커 위치 추정은 다중 마이크 배열과 방음 환경을 고려한 딥러닝 기반 DOA(방향 탐지) 알고리즘이 기존 기법보다 높은 정확도를 보인다. 2) 해양 음향에서는 광대역 수신기와 변동하는 수중 전파 환경을 다루기 위해 CNN‑기반의 소스 로컬라이제이션과 시뮬레이션 데이터로 사전 학습된 모델이 활용된다. 3) 생물음향에서는 종 식별 및 행동 분석을 위해 스펙트로그램을 입력으로 하는 CNN·RNN 하이브리드 모델이 적용되며, 데이터가 희소한 경우 전이 학습과 반지도 학습이 효과적이다. 4) 일상 소음 인식에서는 도시 환경 소리의 분류·세분화에 딥러닝 기반 세그멘테이션 모델이 사용되며, 멀티태스크 학습을 통해 소리 감지와 동시에 상황 인식을 수행한다.
마지막으로 논문은 물리 기반 모델과 ML 모델을 결합한 ‘하이브리드 모델’의 필요성을 강조한다. 물리적 제약을 반영한 손실 함수 설계, 도메인 지식 기반 특징 추출, 그리고 데이터‑주도 학습을 결합함으로써 해석 가능성과 성능을 동시에 향상시킬 수 있다. 향후 연구 과제로는 라벨링 비용 감소를 위한 자기 지도 학습, 모델 압축·경량화, 그리고 실시간 시스템 적용을 위한 효율적인 알고리즘 설계가 제시된다.
댓글 및 학술 토론
Loading comments...
의견 남기기