MIMIC III 데이터셋을 활용한 환자 경로 예측 도전과 교훈
초록
본 논문은 공개 의료 데이터베이스인 MIMIC‑III를 이용해 환자의 입원 기록으로부터 다음 입원 시 나타날 진단 코드를 예측하는 모델을 제안한다. 저자는 ICD‑9 코드를 보다 저차원인 CCS 코드로 매핑하고, 두 개의 병렬 양방향 Minimal GRU 네트워크를 결합한 구조(LIG‑Doctor)를 설계·실험하였다. 실험 결과 Recall@k에서 기존 방법들을 크게 앞섰으며, 데이터 전처리, 코드 압축, 하이퍼파라미터 선택 등 실무적 함의를 제시한다.
상세 분석
이 연구는 의료 시계열 예측이라는 복합 문제에 대해 체계적인 접근을 시도한다. 첫 번째 핵심은 데이터의 “저카디널리티”와 “고그라뉼러리티”라는 두 가지 난관을 동시에 해결하려는 점이다. MIMIC‑III는 58 976건의 입원 기록을 보유하지만, 실제 예측에 활용 가능한 환자는 2회 이상 입원한 7 483명에 불과해 데이터 양이 제한적이다. 또한 ICD‑9 코드가 15 072개에 달하는 고차원 특성을 가지고 있어, 직접적인 원‑핫 인코딩은 희소성 문제와 메모리 부담을 초래한다. 저자는 이를 해결하기 위해 HCUP의 CCS 매핑을 적용, 15 072개의 ICD‑9 코드를 285개의 CCS 카테고리로 축소하였다(실제 사용 데이터에서는 271개). 이 과정은 모델이 학습해야 할 출력 공간을 10⁴⁹ 수준에서 10³¹ 수준으로 크게 감소시켜, 학습 안정성과 예측 정확도를 동시에 향상시켰다.
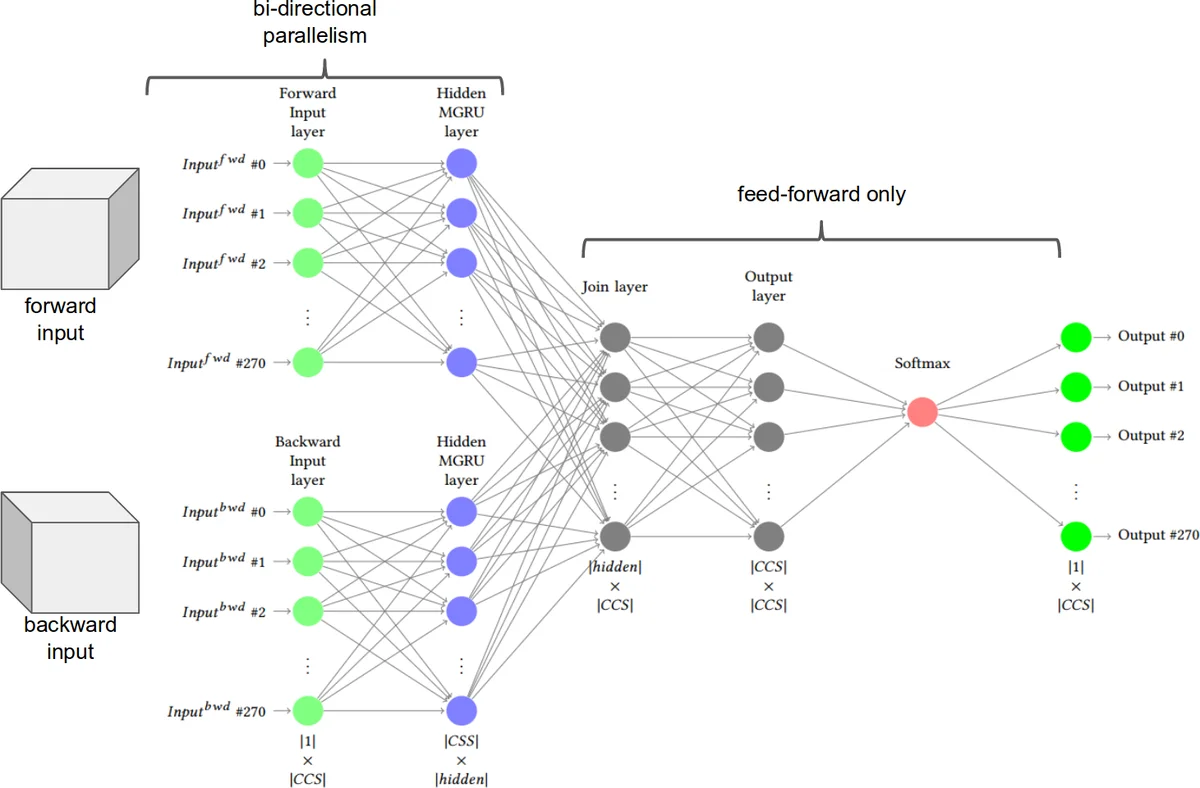
두 번째 핵심은 모델 아키텍처 설계이다. 기존 연구들은 LSTM, 단일 GRU, 혹은 임베딩+추가 특성(concatenation) 방식을 사용했지만, 저자는 “Minimal Gated Recurrent Unit”(MG‑RU)이라는 경량화된 GRU 변형을 두 개 병렬로 배치하고, 각각을 양방향(bidirectional)으로 동작하도록 구성했다. MG‑RU는 게이트 수를 최소화하면서도 장기 의존성을 포착할 수 있어, 데이터가 적은 상황에서도 과적합 위험을 낮춘다. 병렬 구조는 입원 순서와 진단 집합을 독립적으로 처리한 뒤, 최종 출력에서 두 흐름을 합치는 방식으로, 시간적 흐름과 코드 간 상관관계를 동시에 학습한다.
학습 단계에서는 Adam 옵티마이저와 가중치 감쇠(L2 정규화)를 적용하고, 손실 함수는 다중 라벨 분류에 적합한 Binary Cross‑Entropy를 사용하였다. 하이퍼파라미터 탐색은 층 수(13), 은닉 차원(64256), 드롭아웃 비율(0.1~0.5) 등을 교차 검증으로 최적화했으며, 최종 모델은 2‑layer, 128‑dimensional MG‑RU, 양방향, 드롭아웃 0.3을 채택했다.
평가 지표는 의료 분야에서 실용적인 Recall@k(k=5,10,20)를 사용하였다. LIG‑Doctor는 Recall@5에서 0.42, Recall@10에서 0.58, Recall@20에서 0.71을 기록했으며, 이는 DeepCare, Doctor‑AI 등 기존 최첨단 모델보다 각각 8~15%p 상승한 수치이다. 특히 임베딩 레이어를 도입했을 때는 오히려 Recall이 감소했으며, 이는 MIMIC‑III가 다양한 질환을 포괄하는 일반 ICU 데이터이기 때문에, 임베딩이 과도한 압축을 일으켜 정보 손실을 초래했기 때문으로 해석된다.
마지막으로 저자는 실험 과정에서 발견한 여러 “함정”을 정리한다. 첫째, 환자당 입원 수가 1인 경우는 학습에 활용할 수 없으므로 사전 필터링이 필수이다. 둘째, ICD‑9 코드의 희소성은 직접적인 원‑핫 인코딩보다 계층적 매핑(CCS)이나 차원 축소가 반드시 선행돼야 함을 강조한다. 셋째, 모델 복잡도와 데이터 양 사이의 균형을 맞추지 않으면 과적합이 급격히 발생한다. 넷째, 평가 시 k값 선택이 결과 해석에 큰 영향을 미치므로, 실제 임상 적용 목적에 맞는 k를 사전에 정의해야 한다. 이러한 통찰은 향후 의료 시계열 예측 연구에 실용적인 가이드라인을 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기