샘플 효율 강화학습을 위한 최대 엔트로피 멜로맥스 에피소드 제어
본 논문은 비파라메트릭·반파라메트릭 에피소드 제어(EC) 모델에 최대 엔트로피 멜로맥스 정책을 결합한 MEMEC을 제안한다. 상태에 따라 조정되는 온도 파라미터를 갖는 Boltzmann 탐색을 통해 기존 ε‑greedy, UCB, Thompson 샘플링 등에 비해 샘플 효율과 최종 성능이 크게 향상됨을 CartPole, Acrobot, Gridworld 및 Atari 5종 게임에서 실험적으로 입증한다.
저자: Marta Sarrico, Kai Arulkumaran, Andrea Agostinelli
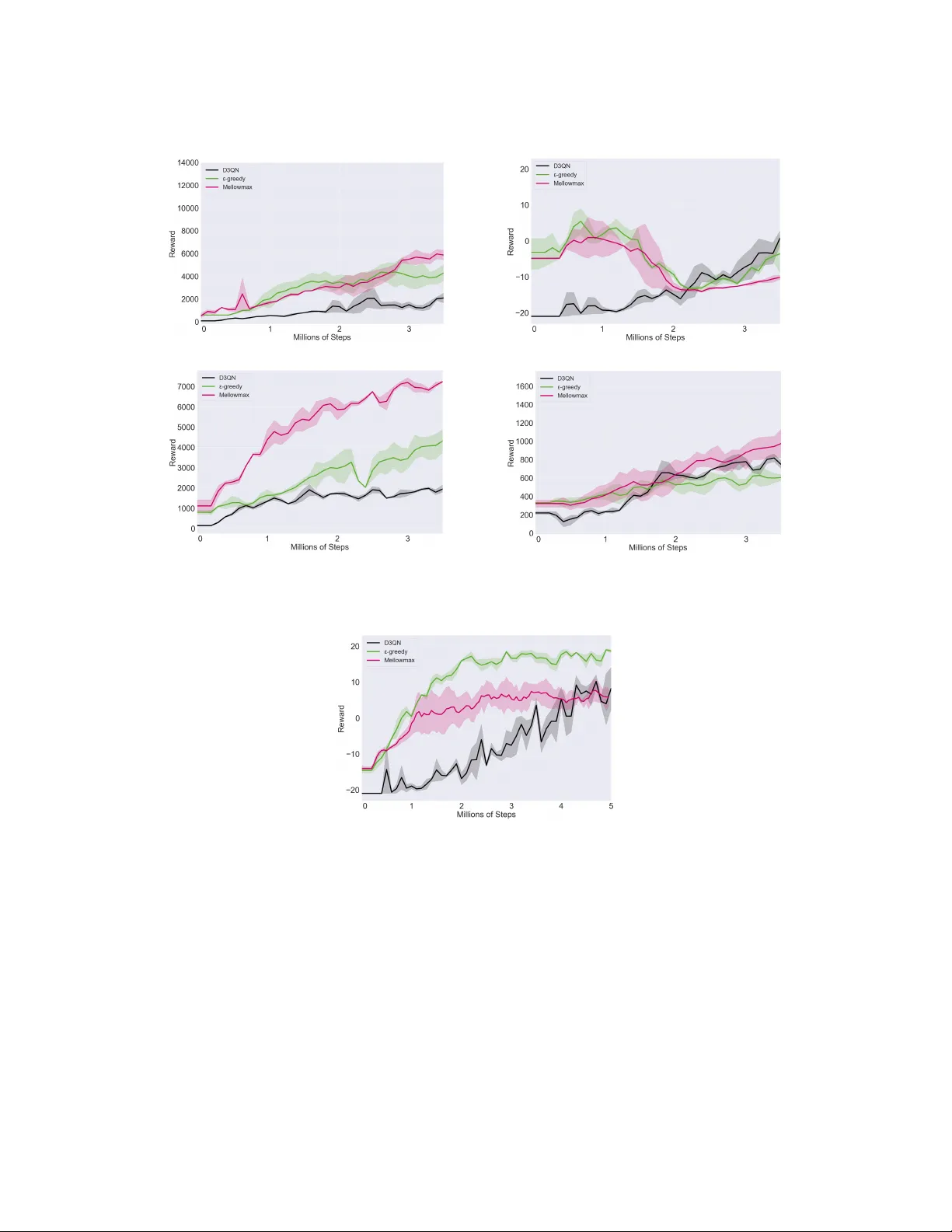
본 논문은 강화학습(RL) 분야에서 샘플 효율성의 한계를 극복하고자, 인간의 장기 기억 체계에서 영감을 얻은 에피소드 제어(Episodic Control, EC)와 최신 탐색 정책인 최대 엔트로피 멜로맥스(Maximum Entropy Mellowmax)를 결합한 새로운 알고리즘 MEMEC(Maximum Entropy Mellowmax Episodic Control)을 제안한다.
**배경 및 동기**
딥 Q‑네트워크(DQN)와 같은 심층 강화학습은 복잡한 환경에서 뛰어난 성능을 보이지만, 인간 수준의 학습 속도에 비해 수백 배 이상의 경험이 필요하다. EC는 비파라메트릭(MFEC) 혹은 반파라메트릭(NEC) 방식으로 상태‑행동 쌍을 메모리에 저장하고, 최근 경험을 기반으로 빠르게 정책을 형성한다. 그러나 기존 EC는 탐색 단계에서 주로 ε‑greedy에 의존해, 탐색‑활용 트레이드오프가 충분히 최적화되지 못한다는 문제가 있다.
**방법론**
멜로맥스 연산자는
\
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기