프로그래밍 언어와 버그 연관성 재검증 논쟁
초록
본 논문은 2017년 CACM에 발표된 “프로그래밍 언어와 코드 품질” 연구에 대한 2019년 TOPLAS 재현 연구의 비판을 반박한다. 저자들은 원 논문의 통계적 효과가 작고 해석에 주의가 필요하다는 결론이 그대로 유지된다고 주장하며, TOPLAS 팀이 사용한 과도한 보정 방법과 데이터 해석 오류를 지적한다. 또한 두 연구가 실질적으로 동일한 결과를 얻었음에도 불구하고, TOPLAS가 원 논문을 “수리 불가능”하다고 주장하는 점을 반박한다.
상세 분석
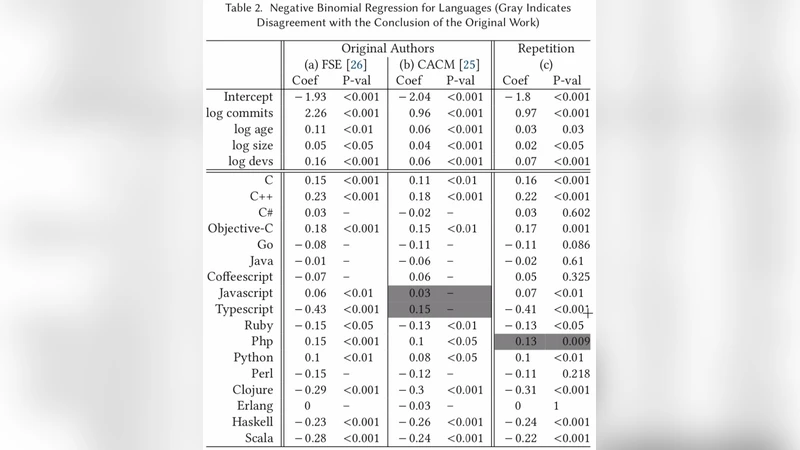
본 논문은 두 차례의 주요 연구, 즉 2014년 FSE 초록·논문과 2017년 CACM 정식 논문을 대상으로 2019년 TOPLAS에서 수행한 재현·재분석 결과에 대한 상세한 반박을 전개한다. 저자들은 먼저 자신들의 원 논문이 이미 “프로젝트 규모, 커밋 수, 개발자 수 등 주요 통제 변수를 로그 변환하여 회귀 모델에 포함”했으며, 따라서 규모 차이에 대한 비판은 사실과 다르다고 지적한다. 이어서 “통제되지 않은 효과”에 대한 비판을 과학적 방법론의 기본 원칙을 무시한 주장으로 규정하고, 실험적 연구는 완전한 통제를 목표로 하기보다 점진적으로 변수들을 통제해 나가는 과정임을 강조한다.
데이터 중복·누락 문제에 대해서는 중복 커밋이 전체의 2% 미만에 불과하고, 누락된 커밋이 특정 언어에 편향되지 않았다는 점을 들어 실질적 영향이 없다고 주장한다. 특히 Perl의 80% 누락 현상은 확장자 매칭 정책(주 확장자만 사용)으로 인한 것이며, 이는 의도된 보수적 수집 방식이므로 결과 왜곡을 초래하지 않는다.
통계적 검정에 있어 TOPLAS가 Bonferroni 보정을 과도하게 적용한 점을 비판한다. 저자들은 이미 논문에서 False Discovery Rate(FDR) 보정을 사용했으며, Bonferroni는 보수적이어서 실제 의미 있는 차이를 놓칠 위험이 크다고 설명한다. 또한 두 연구가 동일한 회귀 결과를 도출했음에도 불구하고, TOPLAS는 회귀 계수 자체를 비교해 차이를 주장했는데, 이는 변수 구성이 다른 모델 간 비교는 통계적으로 부적절하다는 점을 들어 반박한다.
언어 분류 문제에서도 저자들은 2014년 초기에 TypeScript 식별 오류를 발견하고 즉시 수정했으며, 2017년 CACM에서는 수정된 데이터를 사용했다고 명시한다. 반면 TOPLAS는 수정 전 데이터를 근거로 비판했으며, 이는 선택적 인용에 해당한다. 또한 언어를 “정적/동적”, “강력/약함” 등으로 분류하는 기준은 학계에서 아직 합의가 이루어지지 않은 영역이며, 저자들은 다수의 외부 자료를 인용해 자신들의 분류가 타당함을 입증한다.
결론적으로, 저자들은 TOPLAS가 제시한 “핵심 통계적 문제”가 실제로는 재현성 부족, 과도한 보정, 그리고 데이터 해석의 오류에서 비롯된 것이며, 원 논문의 결론—프로그래밍 언어와 버그 연관성은 통계적으로 작고 해석에 신중을 기해야 한다—은 여전히 유효하다고 주장한다.
댓글 및 학술 토론
Loading comments...
의견 남기기