형태와 행동을 동시에 최적화하는 데이터 효율적 딥 강화학습
본 논문은 로봇의 형태(형태학)와 제어 정책을 동시에 학습하는 새로운 프레임워크를 제안한다. Soft‑Actor‑Critic(SAC) 기반의 액터‑크리틱 구조를 이용해 기존에 평가된 디자인과 행동 데이터를 재활용함으로써, 실제 프로토타입이나 시뮬레이션을 반복적으로 수행하지 않고도 최적의 형태‑행동 조합을 빠르게 탐색한다. 설계 탐색 단계에서는 Q‑함수를 목표 함수로 사용하고, 전역 최적화 기법인 입자군집 최적화(PSO)를 적용한다. 실험 결과,…
저자: Kevin Sebastian Luck, Heni Ben Amor, Roberto Cal
본 논문은 로봇의 형태와 행동을 동시에 최적화하는 새로운 프레임워크를 제시한다. 인간과 동물처럼 로봇도 형태와 제어가 상호 의존적으로 진화한다는 점에 착안하여, 형태(형태학)와 행동(제어 정책)을 하나의 확장된 마르코프 결정 과정(MDP)으로 모델링한다. 여기서 상태 전이 확률 p(s′|s,a,ξ)와 보상 r(s,a,ξ)는 모두 형태 변수 ξ에 의존한다.
전통적인 접근법은 형태를 먼저 진화시키고, 그 후에 별도로 정책을 학습하는 이중 최적화 방식을 사용한다. 그러나 형태를 실제로 제작하거나 시뮬레이션에서 평가하는 비용이 매우 크기 때문에, 이러한 방법은 데이터 효율성이 낮다. 논문은 이를 해결하기 위해, 강화학습 과정에서 학습된 Q‑함수를 형태 평가 함수로 재활용한다. 구체적으로, 현재 정책 π(s,ξ)로 선택된 행동 a에 대해 Q(s,a,ξ)를 최대화하는 ξ를 탐색한다. 이는 실제 로봇을 만들지 않아도 형태의 기대 보상을 추정할 수 있게 한다.
이를 구현하기 위해 두 종류의 액터‑크리틱 네트워크를 도입한다. 첫 번째는 “인구” 네트워크(Q_Pop, π_Pop)로, 모든 이전 디자인 데이터로 학습되어 형태 전반에 대한 일반화를 제공한다. 두 번째는 “개별” 네트워크(Q_Ind, π_Ind)로, 현재 디자인에 특화되도록 인구 네트워크의 가중치로 초기화하고, 현재 디자인에서 수집된 데이터에 집중적으로 학습한다. 학습 배치의 10%는 인구 replay buffer에서 샘플링해 개별 네트워크가 과도하게 편향되지 않도록 한다. 이렇게 하면 새로운 디자인에 대해 정책을 처음부터 학습할 필요 없이, 이전 경험을 효과적으로 전이시킬 수 있다.
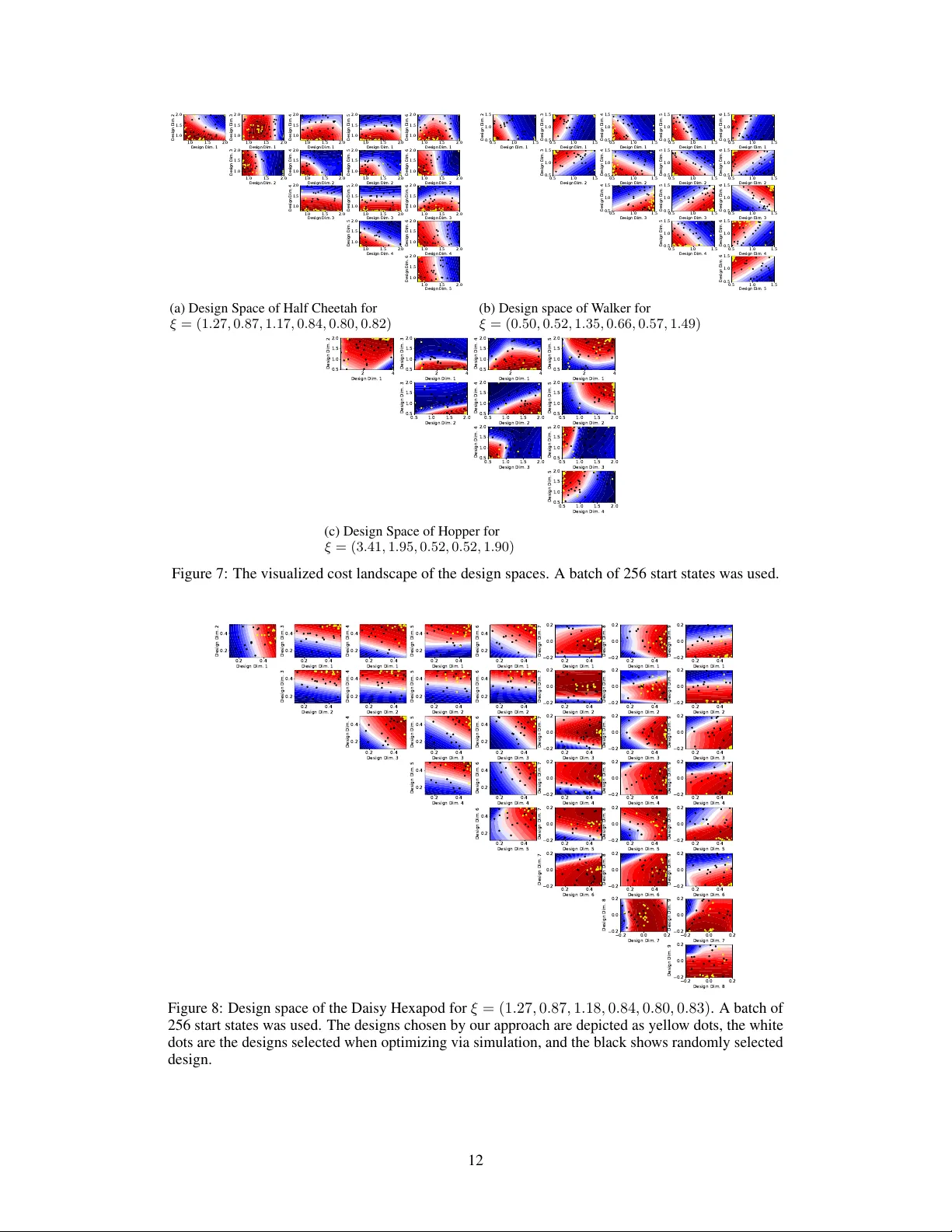
디자인 탐색 단계에서는 두 가지 전략을 비교한다. 무작위 샘플링과 Novelty Search가 후보 디자인을 생성하는데, 실험에서는 무작위 샘플링이 더 안정적인 성능을 보였다. 탐색‑활용 교차는 매 설계 최적화 사이클마다 수행된다. 설계 최적화는 Eq.(6)의 목표 함수를 사용해 입자군집 최적화(PSO)로 수행한다. 목표 함수는 현재 인구 크리틱이 예측한 Q값의 평균이며, 시작 상태 배치는 replay buffer에서 무작위로 추출한다. PSO는 700개의 입자를 250번 반복하면서 후보 디자인을 평가한다.
강화학습 알고리즘으로는 Soft‑Actor‑Critic(SAC)을 채택한다. 네트워크는 3개의 은닉층(각 200유닛)으로 구성되고, 개별 네트워크는 에피소드당 1000번, 인구 네트워크는 250번 업데이트한다. 이는 개별 네트워크가 현재 디자인에 빠르게 적응하도록 설계된 것이다.
실험은 MuJoCo 기반의 Half‑Cheetah 환경에서 수행되었다. 기존의 공동 최적화 방법(예: Schaff et al., Ha 등)과 비교했을 때, 제안 방법은 동일하거나 더 높은 최종 보상을 달성하면서도 필요한 디자인 프로토타입 수를 10배 이상 감소시켰다. 특히, 실제 로봇 제작 비용과 시간을 크게 절감할 수 있음을 보여준다. 또한, Q‑함수가 형태와 행동 사이의 복합적인 상호작용을 효과적으로 학습한다는 것을 시각화와 정량적 분석을 통해 입증하였다.
결론적으로, 이 연구는 형태와 행동을 동시에 최적화하는 문제를 “데이터 재활용”이라는 관점에서 재구성함으로써, 설계‑제어 공동 최적화의 데이터 효율성을 크게 향상시킨다. 향후 실제 로봇에 적용한다면, 물리적 프로토타입 제작 비용을 최소화하면서도 고성능 로봇을 빠르게 설계·제어할 수 있는 실용적인 방법론이 될 것이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기