안전한 인터랙티브 모델 기반 학습 프레임워크 SiMBL
SiMBL은 베이지안 RNN 전방 모델, Lyapunov 함수 기반 안전 집합, 안전 제어 정책을 동시에 학습하여 실제 환경에서 제어기를 점진적으로 개선하고, 확률적 검증을 통해 안전성을 보장한다.
저자: Marco Gallieri, Seyed Sina Mirrazavi Salehian, Nihat Engin Toklu
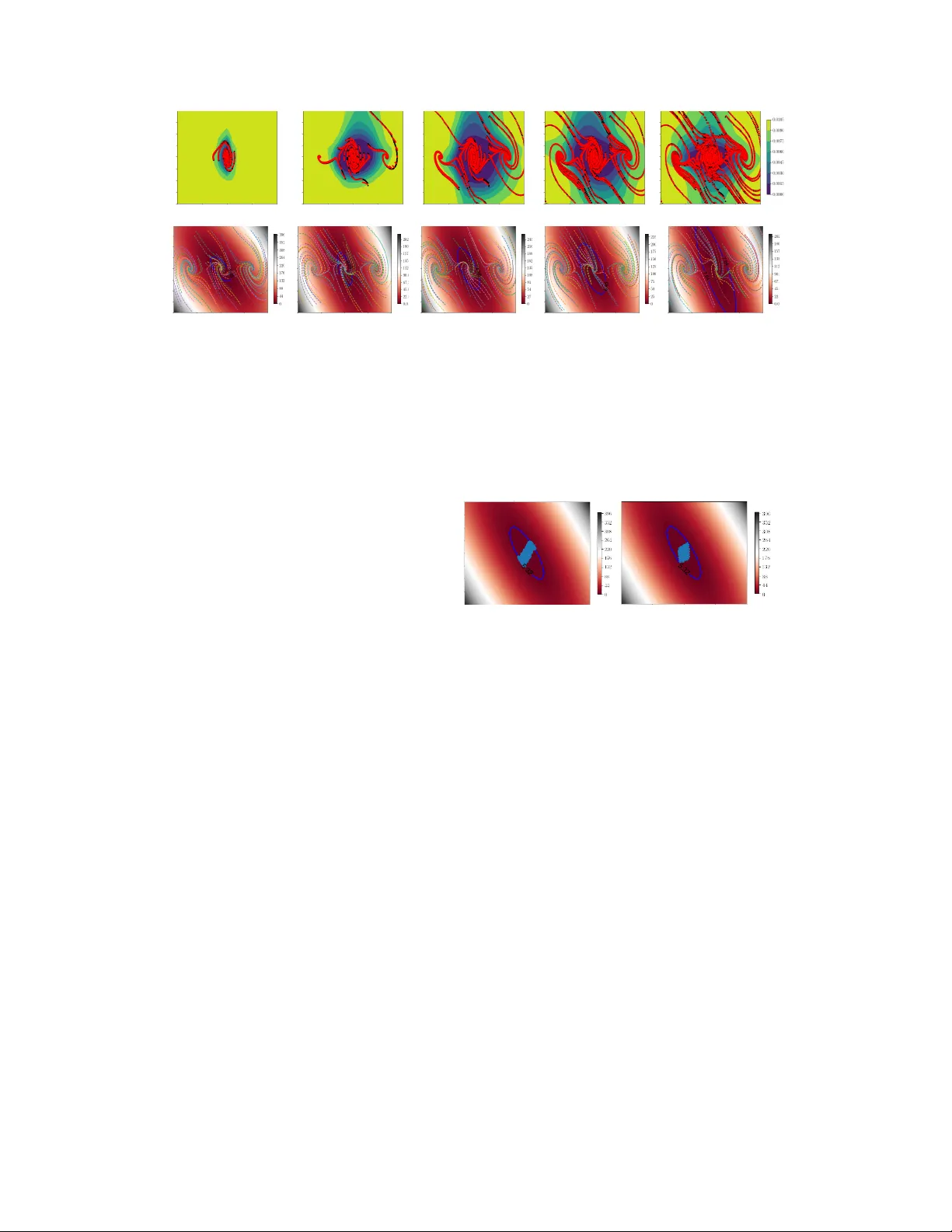
논문은 먼저 제어 대상 시스템을 이산 시간 결정론적 동역학 x(t+1)=x(t)+Δt f(x(t),u(t)) 으로 정의하고, 상태와 입력에 대한 유한하고 비선형인 제약 X, U 를 가정한다. 안전성을 X_s⊆X 내에서 시스템이 수렴하고 제약을 위반하지 않는 것으로 정의하고, 이를 Lyapunov 함수 V(x) 와 정책 K(x) 를 통해 보장한다.
SiMBL의 핵심은 베이지안 RNN 전방 모델이다. 모델은 μ(x,u;θ_μ) 와 Σ(x,u;θ_Σ) 를 출력하는 두 개의 신경망으로 구성되며, Σ 는 시그모이드와 스케일 σ_w 를 통해 최대 분산을 제한한다. NCP 기법을 적용해 훈련 데이터와 무관한 입력에 대해 큰 불확실성을 부여하고, KL 발산과 불확실성 일관성 손실을 포함한 복합 손실 L(θ_μ,θ_Σ) 을 최소화한다. 특히 이전 모델이 존재할 경우, 새로운 모델은 동일한 데이터에 대해 불확실성이 감소하도록 제약한다.
Lyapunov‑Net은 V(x)=xᵀ(I+V_net(x)ᵀV_net(x))x+ψ(x) 형태를 취하고, ψ(x)=ReLU(φ(x)−1) 으로 작업 영역을 반영한다. 안전 집합 X_s={x∈X | V(x)≤l_s} 의 크기를 최대화하기 위해 l_s 와 V_net 파라미터를 동시에 학습한다. 학습 목표는 두 가지 손실을 결합한 J(x) 으로, 하나는 Lyapunov 감소 조건 위반을 페널티화하고, 다른 하나는 안전/불안전 구분을 위한 분류 손실이다.
제어 정책 K(x) 는 교대 최소화 절차에서 Lyapunov 손실을 최소화한 뒤, 강인 제어 손실 L_c(x,u)=ℓ(x,u)+E_W
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기