어댑티브 샘플링으로 구현하는 컴팩트 AI 압축 기술
ASCAI는 유전 알고리즘에서 영감을 얻은 적응형 샘플링 기법을 이용해, DNN 각 층의 압축 하이퍼파라미터를 자동으로 탐색한다. 벡터 공간으로 모델 압축을 표현하고, 초기화·선택·교차·돌연변이 과정을 반복해 정확도와 FLOPs 감소를 동시에 최적화한다. 실험 결과, 기존 규칙 기반 및 강화학습 기반 압축 방법보다 높은 압축률과 정확도를 달성한다.
저자: Mojan Javaheripi, Mohammad Samragh, Tara Javidi
본 논문은 리소스가 제한된 임베디드 환경에서 딥 뉴럴 네트워크(DNN)를 효율적으로 압축하기 위한 새로운 자동화 기법인 ASCAI(Adaptive Sampling for acquiring Compact AI)를 제안한다. 기존 압축 기법은 레이어별 하이퍼파라미터(프루닝 비율, 양자화 비트수, 저차원 근사 랭크 등)를 수동으로 설정하거나, 강화학습·그리드 서치와 같은 비효율적인 탐색 방법에 의존한다. 이러한 접근은 레이어 수가 늘어날수록 탐색 공간이 지수적으로 커져 실용적이지 않다.
ASCAI는 압축 정책을 고정 길이 벡터(‘개체’)로 표현하고, 이를 유전 알고리즘 기반의 적응형 샘플링으로 진화시킨다. 구체적인 설계는 다음과 같다.
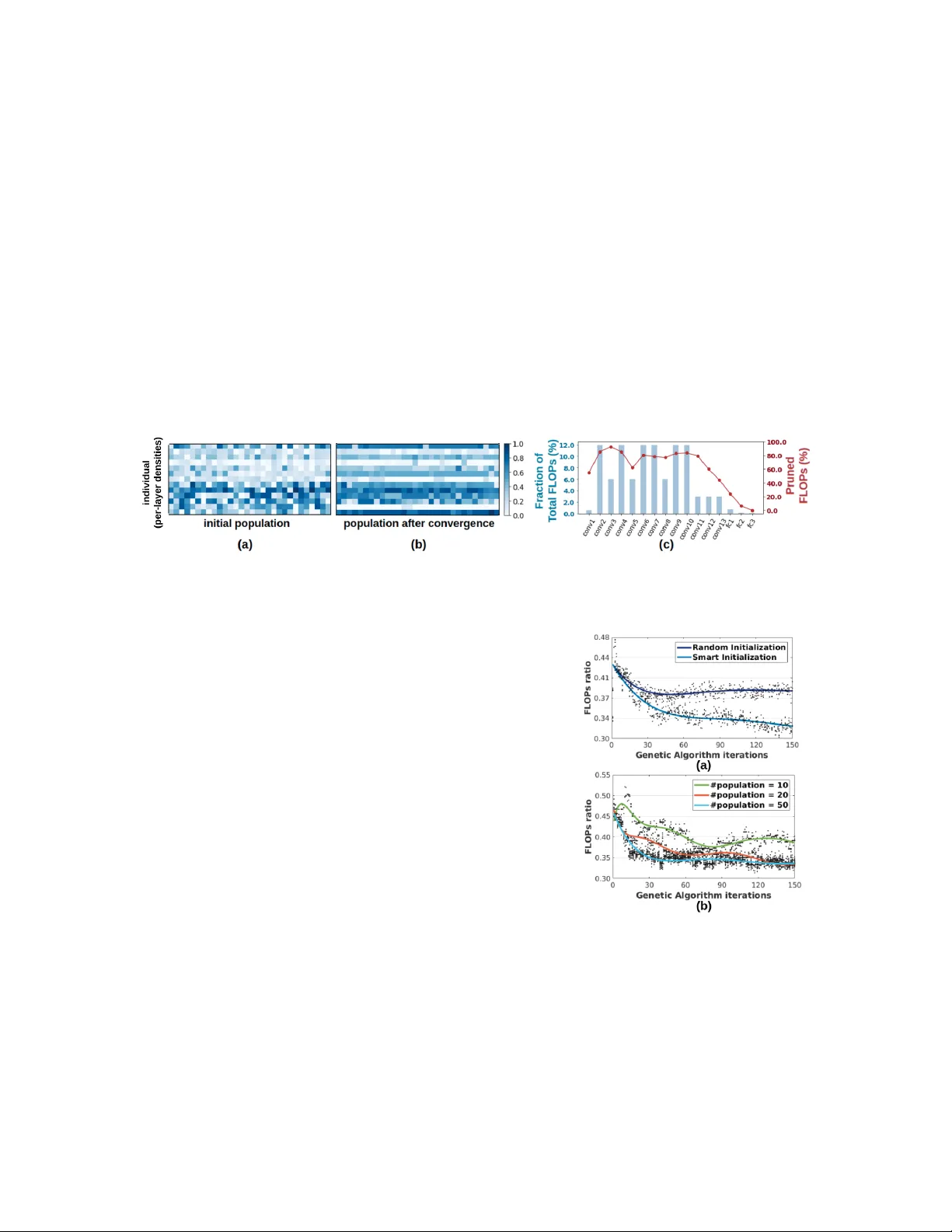
1. **압축 정책의 벡터화**: 프루닝은 각 레이어마다 0~1 사이의 연속값 p를 할당해 프루닝 비율을 나타낸다. SVD는 각 레이어의 근사 랭크를 64 단계 이산값으로 양자화하고, Tucker‑2는 입력·출력 채널 차원을 각각 8 단계로 양자화한다. 이렇게 정의된 벡터는 L1개의 프루닝 파라미터와 L2개의 저차원 근사 파라미터를 포함해 전체 압축 정책을 한 번에 기술한다.
2. **워밍 초기화**: 무작위 초기화만으로는 정확도가 급격히 떨어지는 영역을 많이 탐색하게 된다. 따라서 논문은 사전 정의된 정확도 임계값(acc_thr)을 만족하는 개체만을 받아들이는 워밍 초기화 방식을 도입한다. 연속형 파라미터는 평균이 θ_i/2, 표준편차가 θ_i/2인 정규분포에서 샘플링하고, 이산형 파라미터는 최소 허용 랭크 θ_i 이상을 균등하게 선택한다. 이 과정은 초기 탐색 비용을 크게 절감한다.
3. **평가·스코어링**: 각 개체는 압축된 모델을 실제로 구축하고 검증 데이터에 대해 정확도를 측정한다. 스코어는 ΔFLOPs / PEN_acc 로 정의되며, ΔFLOPs는 원본 모델 대비 FLOPs 감소량, PEN_acc는 정확도 감소에 대한 페널티이다. 정확도가 임계값 이하이면 큰 페널티를 부여해 스코어를 급격히 낮춘다. 이 설계는 압축률을 무조건 추구하는 대신 정확도 보장을 우선시한다.
4. **유전 연산**:
- **선택**: 정규화된 스코어를 기반으로 최소 스코어를 0으로 만들어 가장 낮은 개체가 선택될 확률을 0으로 만든다.
- **교차**: 인접한 두 개체를 p_cross 확률로 교차하고, 각 유전자의 교환 확률 p_swap을 조절한다. 이를 통해 우수한 압축 패턴을 서로 교환한다.
- **돌연변이**: 연속형 파라미터는 N(0,0.2) 잡음을 추가하고, 이산형 파라미터는 ±1 변화를 적용한다. 변형 후에는 허용 범위 내로 클리핑한다.
5. **실험 설정**: CIFAR‑10과 ImageNet 데이터셋을 사용해 ResNet‑50, VGG‑16 등 여러 네트워크에 대해 비구조적 프루닝(Pn), 구조적 프루닝(Ps), SVD, Tucker‑2, 그리고 복합 압축(D+Ps)을 적용했다. 비교 대상은 CP, AMC, SFP, FP, SSS, GDP, ThiNet, RNP 등 기존 최첨단 압축 방법이다.
6. **주요 결과**:
- 비구조적 프루닝에서는 파라미터 수를 1.33배 감소시키면서도 정확도 손실을 최소화했다.
- 구조적 프루닝에서는 평균 1.25배 FLOPs를 감소시키고, 정확도는 기존 방법과 동등하거나 약간 향상되었다.
- 복합 압축에서는 VGG‑16의 FLOPs 감소율을 기존 5배에서 7.2배로 확대했으며, 정확도는 0.3% 상승했다.
- 초기화 방식과 인구 규모에 대한 Ablation Study 결과, 워밍 초기화가 수렴 속도를 크게 높이고, 적절한 인구 규모(예: 50~100)가 최적의 탐색 효율을 제공한다는 것을 확인했다.
7. **분석 및 논의**: 진화 과정에서 초기 레이어와 마지막 완전 연결 레이어는 높은 밀도를 유지하는 경향을 보였으며, 이는 정확도 유지에 중요한 역할을 함을 시사한다. 또한, ASCAI는 레이어 간 상호 의존성을 고려해 전체 FLOPs 비중이 큰 레이어를 우선적으로 압축하고, FLOPs 비중이 작은 레이어는 압축을 완화한다. 이는 기존 규칙 기반 프루닝이 단일 레이어에만 초점을 맞추는 것과 차별화된다.
8. **한계와 향후 연구**: 현재 스코어링 함수에 사용된 가중치와 페널티 파라미터는 경험적으로 설정했으며, 하드웨어‑특화 비용(메모리 대역폭, 전력 소비)까지는 반영되지 않는다. 또한, 압축 정책이 레이어별 연속·이산 파라미터에 한정돼 있어, 비선형 양자화, 혼합 정밀도 등 보다 복잡한 압축 기법을 포함시키려면 추가 설계가 필요하다. 향후 연구에서는 다목표 최적화(예: 정확도·FLOPs·전력)와 자동 파라미터 튜닝을 결합한 확장형 프레임워크를 제시할 수 있다.
결론적으로, ASCAI는 유전 알고리즘의 전역 탐색 능력과 워밍 초기화·정교한 스코어링을 결합해, 대규모 DNN 압축 문제를 효율적으로 해결한다. 실험 결과는 기존 규칙 기반 및 강화학습 기반 방법보다 압축률과 정확도 모두에서 우수함을 입증한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기