딥러닝 혁명과 컴퓨터 아키텍처와 칩 설계의 미래
초록
최근 10년간 딥러닝이 급격히 발전하면서 컴퓨터 비전·음성·번역·자연어 이해 등 다양한 분야에서 성능이 크게 향상되었다. 이 논문은 이러한 머신러닝 혁신이 포스트‑모어스 법 시대에 요구되는 새로운 연산 장치와 설계 패러다임을 어떻게 변화시키는지를 조명한다. 또한 딥러닝이 회로 설계 자동화에 기여할 가능성과, 다중 작업을 동시에 수행하면서도 희소하게 활성화되는 대규모 모델의 설계 방향을 제시한다.
상세 분석
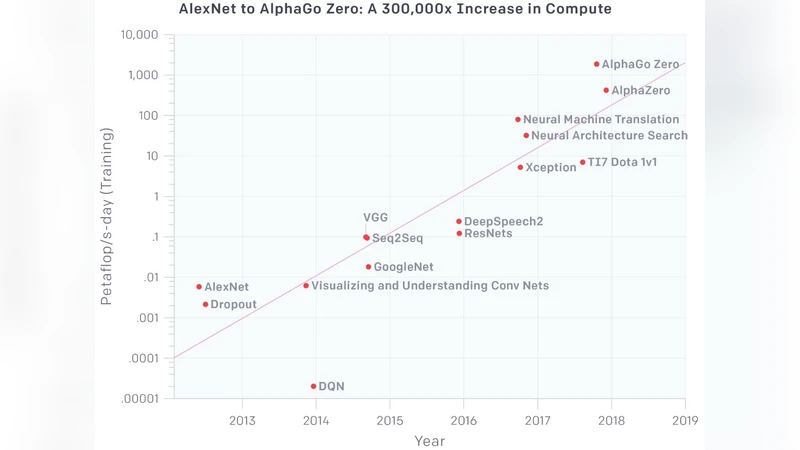
본 논문은 딥러닝의 급격한 성장과 그에 따른 연산 요구량 증가가 전통적인 범용 프로세서와 기존 반도체 공정의 한계를 드러냈음을 강조한다. 특히, 모델 파라미터 수가 수십억에서 수조 단위로 확대됨에 따라 메모리 대역폭, 에너지 효율, 연산 밀도 측면에서 기존 CPU·GPU 구조는 포화 상태에 이른다. 이를 극복하기 위해 ASIC 기반 가속기(예: 구글 TPU), 데이터플로우 아키텍처, 그리고 뉴로모픽 칩과 같은 특수 목적 하드웨어가 부상했으며, 이러한 설계는 연산 단위와 메모리 계층을 긴밀히 결합해 데이터 이동을 최소화함으로써 에너지당 연산량을 크게 향상시킨다.
또한 논문은 포스트‑모어스 법 시대에 ‘스파스 활성화(sparse activation)’와 ‘다이내믹 라우팅(dynamic routing)’이 핵심 설계 원칙이 될 것이라고 주장한다. 현재 대부분의 딥러닝 모델은 전체 네트워크를 완전 활성화하지만, 실제 작업에 필요한 부분만 선택적으로 활성화하면 연산량을 수십 배까지 줄일 수 있다. 이를 구현하기 위해서는 하드웨어 수준에서 조건부 실행, 가변 길이 워크로드 스케줄링, 그리고 빠른 메모리 접근 제어가 필수적이다.
논문은 또한 머신러닝이 회로 설계 자체를 혁신할 가능성을 탐구한다. 설계 규칙 검증, 레이아웃 최적화, 전력 예측 등 전통적으로 전문가의 경험에 의존하던 영역에 딥러닝 기반 모델을 적용하면 설계 주기가 단축되고 최적화 효율이 향상된다. 특히, 강화학습을 이용한 자동 배치와 신경망 기반 전력 모델링은 복잡한 시스템‑온‑칩(SoC) 설계에서 실시간 피드백을 제공한다.
마지막으로, 다중 작업을 동시에 수행하면서도 각 작업에 맞는 서브네트워크만을 활성화하는 ‘스파스 멀티태스크 모델’의 연구 방향을 제시한다. 이러한 모델은 예시와 태스크에 기반한 라우팅 테이블을 동적으로 생성하고, 하드웨어는 이를 실시간으로 해석해 필요한 연산 유닛만을 가동한다. 결과적으로 메모리 사용량과 전력 소모를 최소화하면서도 다양한 애플리케이션을 하나의 칩에서 효율적으로 실행할 수 있다.
요약하면, 딥러닝 혁신은 하드웨어 설계에 새로운 제약과 기회를 동시에 제공하며, 스파스 활성화, 다이내믹 라우팅, 그리고 머신러닝 기반 설계 자동화가 포스트‑모어스 시대의 핵심 동력이 될 것으로 전망된다.
댓글 및 학술 토론
Loading comments...
의견 남기기