시퀀스 영상을 공간 이미지로 변환해 정자 운동성 예측
초록
본 논문은 정자 현미경 영상에서 시간 정보를 자동 인코더를 통해 이미지 형태의 “특징 이미지”로 변환하고, 이를 사전 학습된 ResNet‑34에 전달해 정자 운동성 및 형태학을 회귀 예측한다. 85개의 비디오 데이터를 4가지 입력 방식(I1~I4)으로 실험했으며, 다중 프레임을 사용한 I3·I4가 단일 프레임 대비 MAE를 크게 낮추어 시간 정보의 유용성을 입증한다.
상세 분석
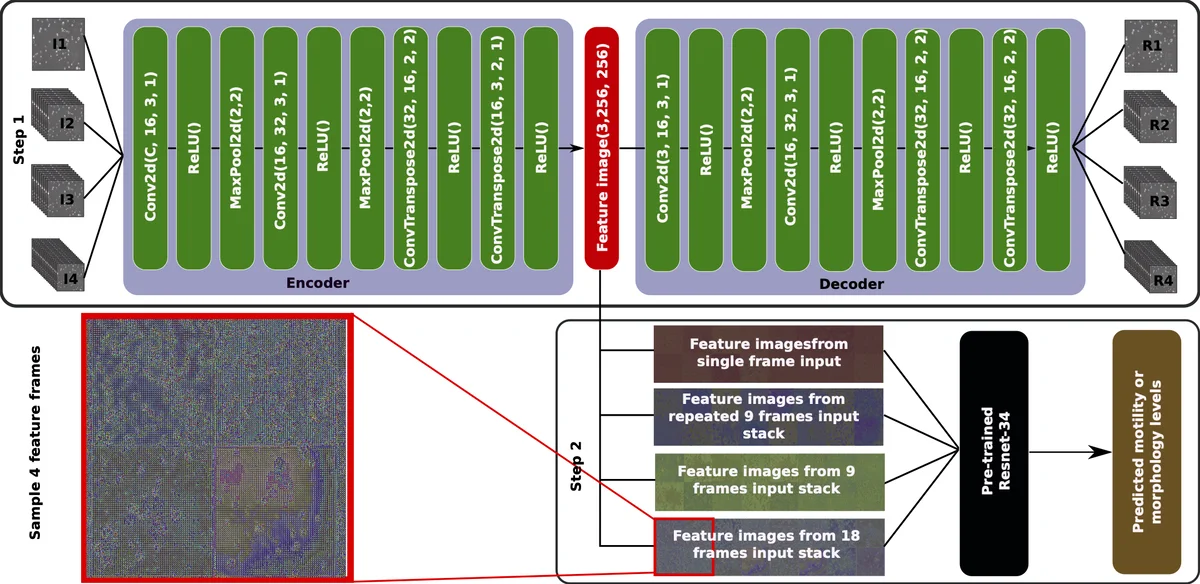
이 연구는 두 단계 딥러닝 파이프라인을 제안한다. 첫 단계에서는 자동 인코더(AE)를 이용해 입력 영상(단일 프레임, 동일 프레임 복제, 9프레임 스택, 18프레임 스택)을 압축하고, 인코더 출력인 256×256 크기의 특징 이미지를 얻는다. 기존 비디오 AE가 벡터 형태의 잠재 표현을 생성하는 것과 달리, 여기서는 공간적 구조를 유지한 이미지 형태의 잠재 공간을 활용한다는 점이 차별점이다. 손실 함수는 MSE이며, 2,000 epoch 동안 학습해 재구성 품질을 확보한다.
두 번째 단계에서는 사전 학습된 ResNet‑34의 마지막 완전 연결 층을 수정해 정자 운동성(진보, 비진보, 정지 비율) 혹은 형태학(머리·미드피스·꼬리 결함 비율) 3개의 연속값을 출력하도록 한다. 특징 이미지는 고정된 인코더 가중치를 그대로 사용해 추출되며, ResNet‑34는 전이 학습을 통해 제한된 데이터(85비디오)에서도 과적합을 방지한다.
입력 유형별 실험 결과를 보면, I3(9프레임)와 I4(18프레임)에서 평균 MAE가 각각 10.8·9.4 정도로 크게 감소한다. 이는 시간적 연속성을 동시에 관찰함으로써 운동성 예측에 필요한 동적 패턴을 효과적으로 포착했음을 의미한다. 반면 형태학은 I1·I2와 유사한 MAE(≈5.6)로, 정자 형태는 단일 프레임에서도 충분히 판단 가능함을 시사한다.
제한점으로는 데이터 양이 매우 적고, 자동 인코더가 재구성 손실만을 최소화하기 때문에 시간적 변화를 명시적으로 강제하지 못한다는 점이다. 향후 변분 자동 인코더(VAE)나 GAN 기반 손실, 혹은 LSTM/GRU와 결합한 하이브리드 구조를 도입하면 시간적 특징 학습을 더욱 강화할 수 있다. 또한, 특징 이미지와 전통적인 시계열 특징(예: optical flow) 간의 정량적 비교가 필요하다.
댓글 및 학술 토론
Loading comments...
의견 남기기