AI 가속기 성능 평가의 함정 처리량만으로는 부족하다
초록
본 논문은 최신 AI 전용 ASIC 가속기들의 성능을 평가할 때 단일 처리량 지표(OPS, FPS 등)만을 사용하는 관행이 정확도 저하라는 중요한 비용을 간과한다는 점을 지적한다. 저자들은 대표적인 이미지 분류 모델들을 대상으로 INT8 양자화와 가중치 프루닝 같은 일반적인 최적화를 적용한 뒤, 하드웨어 FPS와 엔드‑투‑엔드 FPS, 그리고 TOP‑1 정확도의 변화를 정량적으로 측정한다. 실험 결과, 일부 최적화는 처리량을 크게 높이는 반면 정확도 손실이 1 % 이상 발생해 실제 서비스에 부정적 영향을 미칠 수 있음을 보여준다. 따라서 정확도 제약을 포함한 종합적인 평가가 필요함을 강조한다.
상세 분석
이 논문은 AI 가속기 설계와 평가에서 흔히 간과되는 ‘정확도–처리량 트레이드오프’를 체계적으로 분석한다. 먼저, 저자들은 현재 산업계와 학계에서 OPS, TOPS, FPS 등 순수 처리량 지표만을 강조하는 경향을 비판한다. 이러한 접근은 특히 추론 단계에서 INT8 양자화, 가중치 프루닝, 데이터·모델 병렬화, 파이프라인 등 다양한 최적화 기법이 적용될 때 발생하는 정확도 저하를 무시한다는 점에서 위험하다.
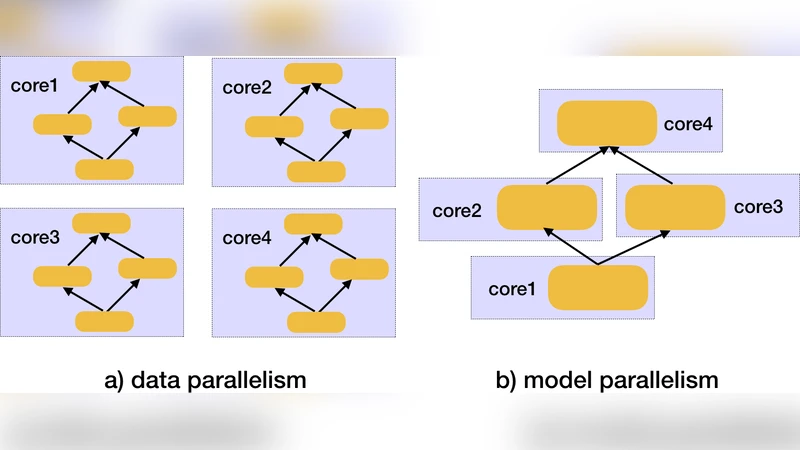
실험 플랫폼으로는 4개의 채널과 각 채널당 8개의 연산 코어, DDR 메모리를 갖춘 커스텀 ASIC인 ACC‑1을 사용한다. 소프트웨어 스택은 오픈소스 프레임워크 Caffe 기반으로, 데이터 병렬성, 모델 병렬성, 파이프라인, 양자화·프루닝 등을 조합할 수 있다. 저자들은 ImageNet 데이터셋을 이용해 AlexNet, ResNet‑18/34/50/101/152, GoogLeNet, Inception‑V3, MobileNet, SqueezeNet 등 12개의 CNN 모델을 선정하고, FP16 기준 정확도와 INT8 양자화·프루닝 적용 후의 정확도 변화를 측정한다.
핵심 결과는 다음과 같다. 첫째, INT8 양자화는 메모리 대역폭과 연산량을 크게 감소시켜 하드웨어 FPS는 평균 30 % 이상 향상시키지만, TOP‑1 정확도는 모델에 따라 0.6 %~1.4 %까지 감소한다. 특히 GoogLeNet과 MobileNet에서 1 % 이상 손실이 관찰돼, 경량 모델일수록 양자화 민감도가 높다는 점을 시사한다. 둘째, 가중치 프루닝은 희소성을 활용해 하드웨어 FPS를 추가로 끌어올리지만, 희소도가 높아질수록 데이터 전송 및 로드 밸런싱 문제가 발생해 엔드‑투‑엔드 FPS는 포화되거나 오히려 감소한다. 또한, 프루닝 비율이 70 %를 초과하면 정확도 손실이 급격히 증가한다.
이러한 결과는 ‘처리량만으로는 실사용 성능을 평가할 수 없다’는 논문의 핵심 주장을 뒷받침한다. 특히, 엔드‑투‑엔드 FPS와 정확도 사이의 비선형 관계는 시스템 설계 단계에서 정확도 제약을 명시적으로 포함시켜야 함을 강조한다. 또한, 데이터 파이프라인과 CPU‑Accelerator 간의 인터페이스 최적화가 전체 성능에 미치는 영향을 간과해서는 안 된다.
논문은 또한 현재 실험이 CNN 기반 이미지 인식에 국한되어 있다는 한계를 인정하고, RNN·Transformer 등 시퀀스 모델에 대한 확장 연구와 다중 플랫폼 간 비교, 그리고 사전 학습된 고성능 모델의 포팅 비용 등을 향후 연구 과제로 제시한다. 전반적으로, 이 연구는 AI 가속기 성능 평가에 있어 정확도·처리량·시스템 전체 흐름을 통합적으로 고려하는 새로운 평가 프레임워크의 필요성을 설득력 있게 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기