주관적 의견 배제의 불공정성: 머신러닝에서 새로운 정의와 완화 방안
이 논문은 주관적 라벨이 존재하는 머신러닝 과제에서 “의견 배제”라는 새로운 불공정성 개념을 정의하고, 이를 정량화·시각화하는 방법을 제시한다. 알고리즘·데이터·평가 단계에서 발생하는 편향을 분석하고, 사용자별 라벨 예측 성능 차이를 측정하는 지표와 시각화 기법을 통해 원인을 파악한다. 또한 데이터 집계 방식을 재설계하고, 사용자 특성을 활용한 조건부 모델링 등을 통해 불공정성을 완화하는 전략을 논의한다.
저자: Agathe Balayn, Aless, ro Bozzon
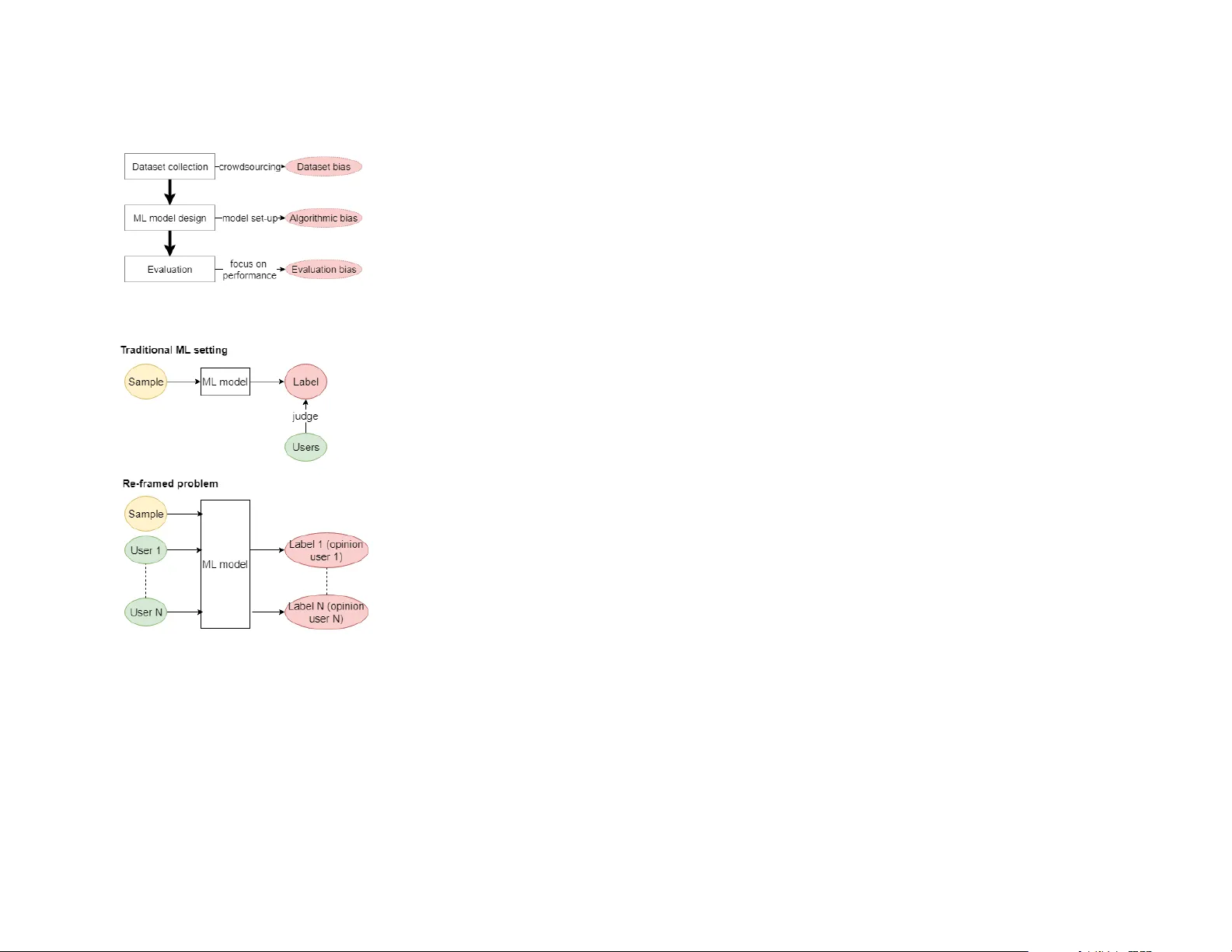
본 논문은 머신러닝(ML) 시스템이 주관적 라벨을 다루는 상황에서 발생하는 새로운 형태의 불공정성을 조명한다. 기존의 ML 파이프라인은 객관적 라벨을 전제로 설계돼 왔으며, 주관적 판단이 필요한 작업—예를 들어 텍스트 독성, 이미지 미학, 감정 분석 등—에 적용될 때 라벨의 다원성을 무시하고 다수 의견만을 ‘정답’으로 삼는 경향이 있다. 저자들은 이를 ‘의견 배제(opinion exclusion)’라는 개념으로 정의하고, 이러한 배제가 사용자 경험을 왜곡하고 사회적 필터 버블을 강화할 위험이 있음을 강조한다.
논문은 먼저 의견 배제 불공정성의 원인을 세 단계로 구분한다. 첫째, **알고리즘 편향**에서는 주관적 라벨을 이진화하거나 다수결(MV)로 집계하는 기존 방법이 소수 의견을 학습에서 제외한다는 점을 지적한다. 둘째, **데이터셋 편향**에서는 크라우드소싱 라벨을 품질 검증 없이 단일 라벨로 축소함으로써, ‘의견 다양성’ 자체가 데이터에 반영되지 못한다는 문제를 제시한다. 특히, 라벨 품질을 판단하기 위해 ‘동의율’만을 기준으로 저품질 annotator를 걸러내는 과정이 실제로는 소수 의견을 제거하는 효과를 낸다. 셋째, **평가 편향**에서는 기존의 정확도·F1·AUC와 같은 성능 지표가 의견 배제 현상을 드러내지 못하고, 오히려 모델이 다수 의견에만 최적화되도록 유도한다는 점을 비판한다.
이러한 문제를 해결하기 위해 저자들은 **불공정성 정량화 지표**와 **시각화 방법**을 제안한다. 구체적으로, 각 annotator의 평균 불일치율(ADR)을 계산해 사용자들을 그룹화하고, 그룹별 모델 성능을 측정한다. 그룹 간 성능 표준편차를 불공정성 지표로 사용함으로써, 모델이 특정 사용자 그룹(특히 다수 의견과 크게 다른 의견을 가진 그룹)에 대해 얼마나 부정확한지를 수치화한다. 이 지표는 (1) 불공정성을 정량화, (2) 일반 성능과의 트레이드오프 관찰, (3) 평가 데이터셋에 독립적, (4) 적용하고자 하는 성능 메트릭에 맞게 조정 가능, (5) 원인 분석을 위한 인사이트 제공이라는 다섯 가지 요구조건을 만족한다.
시각화 측면에서는 ADR 기반 그룹별 정확도를 그래프 형태로 나타내어, 어느 그룹이 가장 큰 성능 격차를 보이는지 직관적으로 파악할 수 있다. 이를 통해 데이터 수집 단계에서 특정 annotator나 의견 유형을 보강하거나, 모델 설계 단계에서 사용자 특성을 반영하는 전략을 도출한다.
실험에서는 독성 예측 데이터셋(
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기