분산 SGD를 위한 압축·희소화·지역 연산 결합 기법
본 논문은 양자화와 Top‑k 희소화, 그리고 로컬 업데이트를 동시에 적용한 Qsparse‑local‑SGD 알고리즘을 제안한다. 동기·비동기 두 구현을 모두 분석하고, 부드러운 비볼록 및 강볼록 함수에 대해 기존 분산 SGD와 동일한 수렴 속도를 보임을 증명한다. 실험에서는 ResNet‑50을 ImageNet에 적용해 전송 비트 수를 15‑20배 절감하면서 목표 정확도에 도달한다.
저자: Debraj Basu, Deepesh Data, Can Karakus
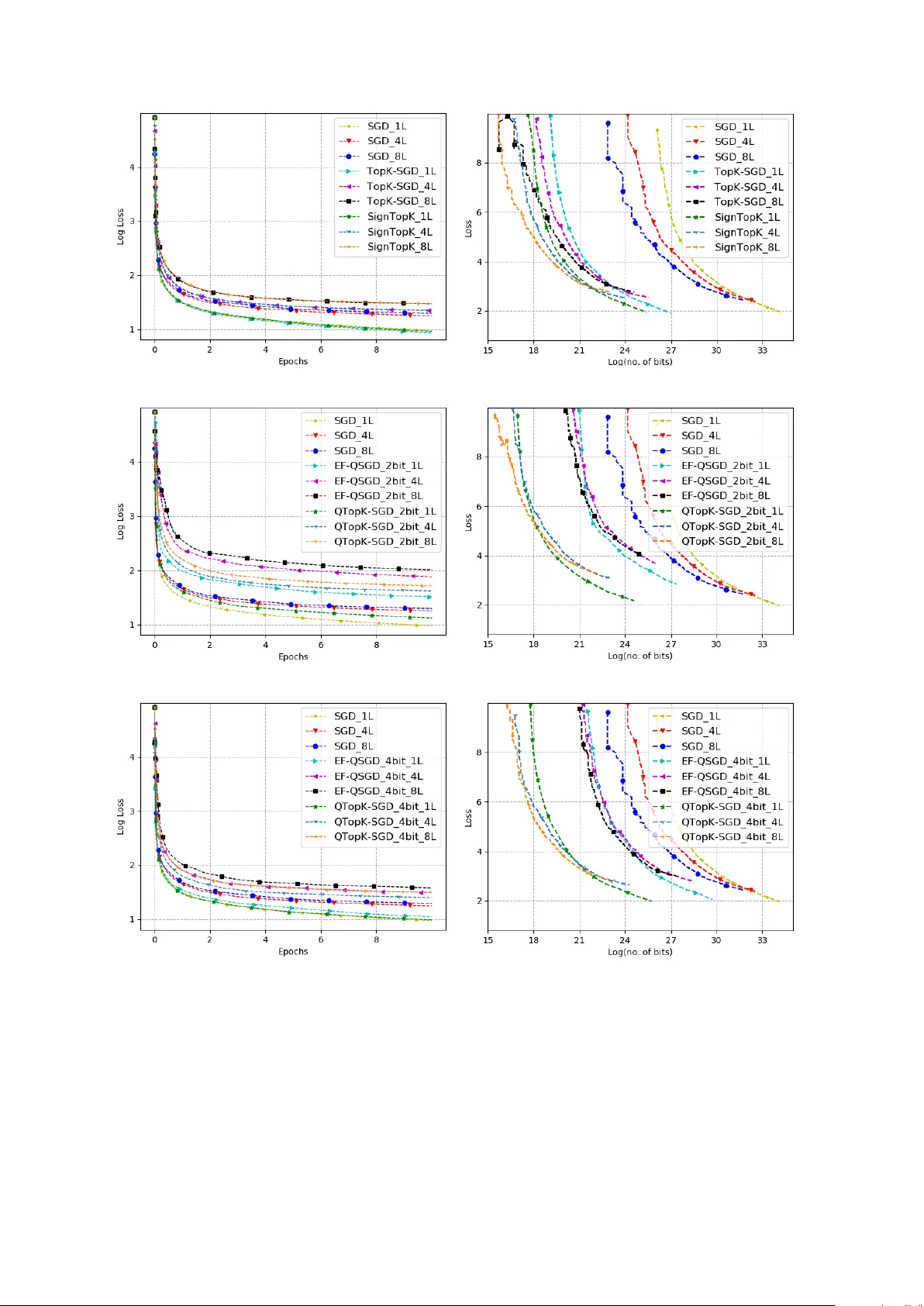
본 논문은 대규모 분산 학습에서 가장 큰 제약 중 하나인 통신 병목을 해결하기 위해, 양자화(quantization), 희소화(sparsification), 그리고 로컬 연산(local computation)을 동시에 적용한 새로운 알고리즘 Qsparse‑local‑SGD를 제안한다. 기존 연구들은 이 세 가지 기법 중 하나 혹은 두 가지를 조합했지만, 세 가지를 모두 포괄하면서도 이론적 수렴을 보장하는 방법은 제시되지 않았다.
먼저 문제 설정을 정의한다. R개의 워커가 각각 로컬 데이터 D_r을 가지고 있으며, 전체 손실 함수는 f(x)= (1/R)∑_{r=1}^R f^{(r)}(x) 로 표현된다. 전통적인 분산 SGD는 각 워커가 전체 gradient를 계산하고, 마스터에 전송해 평균을 취한 뒤 파라미터를 업데이트한다. 하지만 파라미터 차원이 수백만~수억에 달하는 현대 딥러닝 모델에서는 32‑bit 혹은 64‑bit 전체 gradient 전송이 네트워크 대역폭을 크게 초과한다.
이에 저자는 다음과 같은 설계 원칙을 채택한다. (1) **양자화**: 무편향 양자화기 Q_s를 사용해 각 성분을 s개의 레벨로 압축한다. QSGD, stochastic‑s‑level, stochastic‑rotate 등 다양한 양자화기가 정의되고, 기대값이 원본과 동일하도록 설계된다. (2) **희소화**: Top‑k 혹은 Rand‑k 연산자를 적용해 전체 차원 d 중 k개만을 선택한다. 선택된 성분은 그대로 전송하고, 나머지는 0으로 만든다. 이는 압축 연산자 정의에 따라 E
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기